使用 RDS 数据 API
通过 RDS 数据 API(数据 API),您可以将 Web 服务接口用于 Aurora 数据库集群。数据 API 不需要与数据库集群的持久连接。相反,它提供了安全 HTTP 终端节点以及与 Amazon 开发工具包的集成。您可以使用终端节点运行 SQL 语句,而无需管理连接。
对数据 API 的所有调用都是同步的。默认情况下,如果调用未在 45 秒内完成处理,就会超时。但是,在调用超时后,您可以使用 continueAfterTimeout 参数继续运行 SQL 语句。有关示例,请参阅运行 SQL 事务。
用户无需在调用数据 API 时传递凭证,因为数据 API 会使用存储在 Amazon Secrets Manager 中的数据库凭证。要在 Secrets Manager 中存储凭证,用户必须获得使用 Secrets Manager 以及数据 API 的适当权限。有关向用户授权的更多信息,请参阅 授予对 RDS 数据 API 的访问权限。
您还可以使用数据 API 将 Amazon Aurora 与其它 Amazon 应用程序(如 Amazon Lambda、Amazon AppSync 和 Amazon Cloud9)集成。数据 API 提供了一种更安全的方式来使用 Amazon Lambda。通过此方式,您无需配置 Lambda 函数来访问 Virtual Private Cloud (VPC) 中的资源,即可访问数据库集群。有关更多信息,请参阅 Amazon Lambda
您可以在创建 Aurora 数据库集群时启用数据 API。您也可以稍后修改配置。有关更多信息,请参阅启用 RDS 数据 API。
启用数据 API 后,还可以使用查询编辑器运行即席查询,而无需配置查询工具在 VPC 中访问 Aurora。有关更多信息,请参阅使用查询编辑器。
主题
区域和版本可用性
有关适用于数据 API 的区域和引擎版本的信息,请参阅以下部分。
| 集群类型 | 区域和版本可用性 |
|---|---|
Aurora PostgreSQL 预调配和 Serverless v2 |
|
Aurora PostgreSQL Serverless v1 |
|
Aurora MySQL Serverless v1 |
注意
目前,数据 API 不适用于 Aurora MySQL 预调配集群或 Serverless v2 数据库集群。
如果在通过命令行界面或 API 访问数据 API 时需要经过 FIPS 140-2 验证的加密模块,请使用 FIPS 端点。有关可用的 FIPS 端点的更多信息,请参阅《美国联邦信息处理标准(FIPS)第 140-2 版》
RDS 数据 API 的限制
RDS 数据 API(数据 API)存在以下限制:
您只能对数据库集群中的写入器实例执行数据 API 查询。但是,写入器实例可以接受写入和读取查询。
使用 Aurora Global Database,您可以在主数据库集群和辅助数据库集群上启用数据 API。但是,在辅助集群提升为主集群之前,它没有写入器实例。因此,您发送到辅助集群的数据 API 查询会失败。在提升的辅助集群具有可用的写入器实例后,对该数据库实例的数据 API 查询应该会成功。
性能详情不支持监控您使用数据 API 进行的数据库查询。
T 数据库实例类不支持数据 API。
对于 Aurora PostgreSQL Serverless v2 和预调配数据库集群,RDS 数据 API 不支持枚举类型。有关受支持类型的列表,请参阅将 RDS 数据 API 用于 Serverless v2 和预调配以及 Aurora Serverless v1 的比较。
对于 Aurora PostgreSQL 版本 14 和更高版本的数据库,数据 API 仅支持使用 scram-sha-256 进行密码加密。
将 RDS 数据 API 用于 Serverless v2 和预调配以及 Aurora Serverless v1 的比较
下表描述了将 RDS 数据 API(数据 API)用于 Aurora PostgreSQL Serverless v2 和预调配数据库集群以及 Aurora Serverless v1 数据库集群之间的区别。
| Difference | Aurora PostgreSQL Serverless v2 和预调配 | Aurora Serverless v1 |
|---|---|---|
| 每秒最大请求数 | 无限制 | 1000 |
| 使用 RDS API 或 Amazon CLI 在现有数据库上启用或禁用数据 API |
|
|
| CloudTrail 事件 | 来自数据 API 调用的事件是数据事件。默认情况下,这些事件会自动排除在跟踪记录之外。有关更多信息,请参阅在 Amazon CloudTrail 跟踪记录中包含数据 API 事件。 | 来自数据 API 调用的事件是管理事件。默认情况下,这些事件会自动包含在跟踪记录中。有关更多信息,请参阅从 Amazon CloudTrail 跟踪记录中排除数据 API 事件(仅限 Aurora Serverless v1)。 |
| 多语句支持 | 不支持多语句。在这种情况下,数据 API 会引发 ValidationException: Multistatements aren't
supported。 |
对于 Aurora PostgreSQL,多语句仅返回第一个查询响应。对于 Aurora MySQL,不支持多语句。 |
| BatchExecuteStatement | 更新结果中生成的字段对象为空。 | 更新结果中生成的字段对象包括插入的值。 |
| ExecuteSQL | 不支持 | 已弃用 |
| ExecuteStatement |
数据 API 不支持某些数据类型,例如几何和货币类型。在这种情况下,数据 API 会引发 仅支持以下类型:
仅支持以下数组类型:
|
ExecuteStatement 支持检索多维数组列和所有高级数据类型。 |
授予对 RDS 数据 API 的访问权限
用户只有在获得授权的情况下才能调用 RDS 数据 API(数据 API)操作。您可以通过附加定义用户权限的 Amazon Identity and Access Management(IAM)策略,授予用户使用数据 API 的权限。如果您使用的是 IAM 角色,您还可以将策略附加到角色。Amazon 托管式策略 AmazonRDSDataFullAccess 包含数据 API 的权限。
AmazonRDSDataFullAccess 策略还包含允许用户从 Amazon Secrets Manager 获取密钥值的权限。用户需要使用 Secrets Manager 来存储他们在调用数据 API 时可以使用的密钥。使用密钥意味着用户不需要在调用数据 API 时提供其目标资源的数据库凭证。数据 API 会透明地调用 Secrets Manager,后者会允许(或拒绝)用户的密钥请求。有关如何设置与数据 API 一起使用的密钥的信息,请参阅在 Amazon Secrets Manager 中存储数据库凭证。
AmazonRDSDataFullAccess 策略提供对资源的完全访问权限(通过数据 API 进行访问)。您可以通过定义指定资源的 Amazon Resource Name (ARN) 的策略来缩小范围。
例如,以下策略显示了用户访问数据库集群(由其 ARN 标识)的数据 API 所需的最低权限的示例。该策略包含用户访问 Secrets Manager 和获取数据库实例授权所需的权限。
{ "Version": "2012-10-17", "Statement": [ { "Sid": "SecretsManagerDbCredentialsAccess", "Effect": "Allow", "Action": [ "secretsmanager:GetSecretValue" ], "Resource": "arn:aws:secretsmanager:*:*:secret:rds-db-credentials/*" }, { "Sid": "RDSDataServiceAccess", "Effect": "Allow", "Action": [ "rds-data:BatchExecuteStatement", "rds-data:BeginTransaction", "rds-data:CommitTransaction", "rds-data:ExecuteStatement", "rds-data:RollbackTransaction" ], "Resource": "arn:aws:rds:us-east-2:111122223333:cluster:prod" } ] }
建议您为策略语句中的 "Resources" 元素使用具体的 ARN(如示例所示),而不是通配符 (*)。
使用基于标签的授权
RDS 数据 API(数据 API)和 Secrets Manager 都支持基于标签的授权。标签是用附加的字符串值标记资源(如 RDS 集群)的键值对,例如:
environment:productionenvironment:development
您可以出于成本分配、操作支持、访问控制及许多其他原因,为资源应用标签。(如果您的资源上还没有标签,并且您想要应用标签,您可以在为 Amazon RDS 资源添加标签中了解更多信息。) 您可以在策略语句中使用标签来限制对使用这些标签进行标记的 RDS 集群的访问。例如,Aurora 数据库集群可能包含将其环境标识为生产环境或开发环境的标签。
以下示例说明如何在策略语句中使用标签。这条语句要求在 Data API 请求中传递的集群和密钥都包含 environment:production 标签。
策略的应用方式如下:当用户使用数据 API 进行调用时,请求被发送到服务。数据 API 首先验证在请求中传递的集群 ARN 是否包含 environment:production 标签。然后,它会调用 Secrets Manager 以在请求中检索用户密钥的值。Secrets Manager 还会验证用户的密钥是否已使用 environment:production 进行标记。如果包含,Data API 将使用检索到的值作为用户的数据库密码。最后,如果此密码正确,则会为用户成功调用 Data API 请求。
{ "Version": "2012-10-17", "Statement": [ { "Sid": "SecretsManagerDbCredentialsAccess", "Effect": "Allow", "Action": [ "secretsmanager:GetSecretValue" ], "Resource": "arn:aws:secretsmanager:*:*:secret:rds-db-credentials/*", "Condition": { "StringEquals": { "aws:ResourceTag/environment": [ "production" ] } } }, { "Sid": "RDSDataServiceAccess", "Effect": "Allow", "Action": [ "rds-data:*" ], "Resource": "arn:aws:rds:us-east-2:111122223333:cluster:*", "Condition": { "StringEquals": { "aws:ResourceTag/environment": [ "production" ] } } } ] }
该示例分别显示了针对数据 API 和 Secrets Manager 的 rds-data 和 secretsmanager 操作。不过,您可以通过多种不同的方式组合操作和定义标签条件,以支持您的特定使用案例。有关更多信息,请参阅为 Secrets Manager 使用基于身份的策略(IAM 策略)。
在策略的 "Condition" 元素中,您可以从以下选项中选择标签键:
aws:TagKeysaws:ResourceTag/${TagKey}
要了解有关资源标签以及如何使用 aws:TagKeys 的更多信息,请参阅使用资源标签控制对 Amazon 资源的访问。
注意
数据 API 和 Amazon Secrets Manager 都会对用户进行授权。如果您不具有策略中定义的所有操作的权限,则会收到 AccessDeniedException 错误。
在 Amazon Secrets Manager 中存储数据库凭证
调用 RDS 数据 API(数据 API)时,您可以使用 Secrets Manager 中的密钥传递 Aurora 数据库集群的凭证。要通过此方式传递凭证,您需要指定密钥的名称或密钥的 Amazon 资源名称 (ARN)。
在密钥中存储数据库集群凭证
-
使用 Secrets Manager 创建包含 Aurora 数据库集群凭证的密钥。
有关说明,请参阅《Amazon Secrets Manager 用户指南》中的创建数据库密钥。
-
使用 Secrets Manager 控制台查看您创建的密钥的详细信息,或运行
aws secretsmanager describe-secretAmazon CLI 命令。记下密钥的名称和 ARN。您可以将其用于对数据 API 的调用中。
有关使用 Secrets Manager 的更多信息,请参阅 Amazon Secrets Manager 用户指南。
要了解 Amazon Aurora 如何管理身份和访问管理,请参阅 Amazon Aurora 如何使用 IAM。
有关创建 IAM 策略的更多信息,请参阅 IAM 用户指南中的创建 IAM 策略。有关将 IAM 策略添加到用户的信息,请参阅 IAM 用户指南 中的添加和删除 IAM 身份权限。
启用 RDS 数据 API
要使用 RDS 数据 API(数据 API),请为 Aurora 数据库集群启用它。您可以在创建或修改数据库集群时启用数据 API。
注意
对于 Aurora PostgreSQL,Aurora Serverless v2、Aurora Serverless v1 和预调配数据库支持数据 API。对于 Aurora MySQL,只有 Aurora Serverless v1 数据库支持数据 API。
在创建数据库时启用 RDS 数据 API
在创建支持 RDS 数据 API(数据 API)的数据库时,您可以启用此功能。以下过程描述了在使用 Amazon Web Services Management Console、Amazon CLI 或 RDS API 时如何执行此操作。
要在创建数据库集群时启用数据 API,请在创建数据库页面的连接部分中选中启用 RDS 数据 API 复选框,如以下屏幕截图所示。

有关如何创建数据库的说明,请参阅以下内容:
对于 Aurora PostgreSQL Serverless v2 和预调配数据库 – 创建 Amazon Aurora 数据库集群
对于 Aurora Serverless v1 – 创建 Aurora Serverless v1 数据库集群
要在创建 Aurora 数据库集群时启用数据 API,请运行带 --enable-http-endpoint 选项的 create-db-cluster Amazon CLI 命令。
以下示例创建一个启用了数据 API 的 Aurora PostgreSQL 数据库集群。
对于 Linux、macOS 或 Unix:
aws rds create-db-cluster \ --db-cluster-identifiermy_pg_cluster\ --engine aurora-postgresql \ --enable-http-endpoint
对于 Windows:
aws rds create-db-cluster ^ --db-cluster-identifiermy_pg_cluster^ --engine aurora-postgresql ^ --enable-http-endpoint
要在创建 Aurora 数据库集群时启用数据 API,请使用 CreateDBCluster 操作,并将 EnableHttpEndpoint 参数的值设置为 true。
在现有数据库上启用 RDS 数据 API
您可以修改支持 RDS 数据 API(数据 API)的数据库集群以启用或禁用此功能。
启用或禁用数据 API(Aurora PostgreSQL Serverless v2 和预调配)
使用以下过程在 Aurora PostgreSQL Serverless v2 和预调配数据库上启用或禁用数据 API。要在 Aurora Serverless v1 数据库上启用或禁用数据 API,请使用启用或禁用数据 API(仅限 Aurora Serverless v1)中的过程。
您可以使用 RDS 控制台为支持此功能的数据库集群启用或禁用数据 API。为此,请打开要启用或禁用数据 API 的数据库的集群详细信息页面,然后在连接和安全选项卡上,转到 RDS 数据 API 部分。此部分显示数据 API 的状态,并允许您启用或禁用它。
以下屏幕截图显示 RDS 数据 API 未启用。

要在现有数据库上启用或禁用数据 API,请运行 enable-http-endpoint 或 disable-http-endpoint Amazon CLI 命令,然后指定数据库集群的 ARN。
以下示例启用数据 API。
对于 Linux、macOS 或 Unix:
aws rds enable-http-endpoint \ --resource-arncluster_arn
对于 Windows:
aws rds enable-http-endpoint ^ --resource-arncluster_arn
要在现有数据库上启用或禁用数据 API,请使用 EnableHttpEndpoint 和 DisableHttpEndpoint 操作。
启用或禁用数据 API(仅限 Aurora Serverless v1)
使用以下步骤在现有 Aurora Serverless v1 数据库上启用或禁用数据 API。要在 Aurora PostgreSQL Serverless v2 和预调配数据库上启用或禁用数据 API,请使用启用或禁用数据 API(Aurora PostgreSQL Serverless v2 和预调配)中的过程。
在修改 Aurora Serverless v1 数据库集群时,您可以在 RDS 控制台的连接部分中启用数据 API。
以下屏幕截图显示了在修改 Aurora 数据库集群时启用的数据 API。
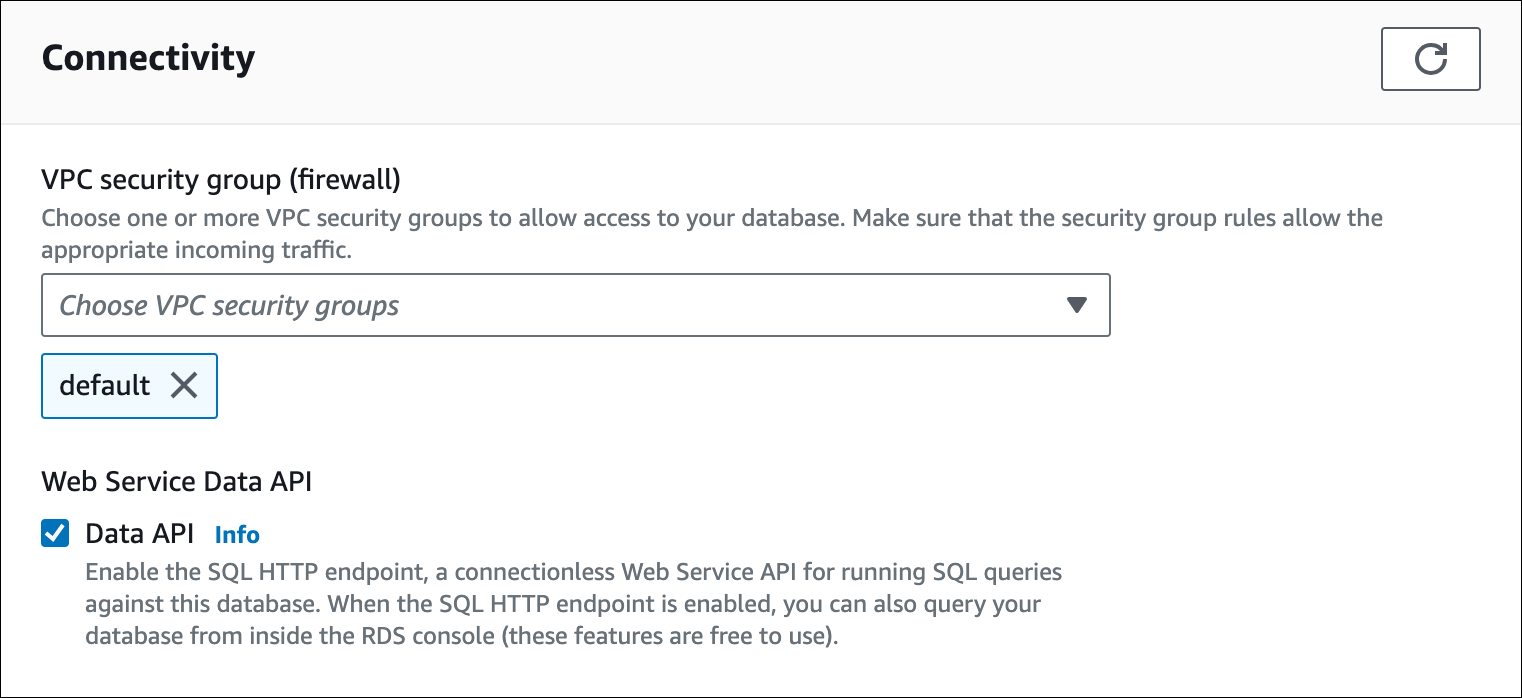
有关如何修改 Aurora Serverless v1 数据库集群的说明,请参阅修改 Aurora Serverless v1 数据库集群。
要启用或禁用数据 API,请运行 modify-db-cluster Amazon CLI 命令,并使用 --enable-http-endpoint 或 --no-enable-http-endpoint(如果适用)。
以下示例在 sample-cluster 上启用数据 API。
对于 Linux、macOS 或 Unix:
aws rds modify-db-cluster \ --db-cluster-identifier sample-cluster \ --enable-http-endpoint
对于 Windows:
aws rds modify-db-cluster ^ --db-cluster-identifier sample-cluster ^ --enable-http-endpoint
要启用数据 API,请使用 ModifyDBCluster 操作,并将 EnableHttpEndpoint 的值设置为 true 或 false(如果适用)。
为 RDS 数据 API 创建 Amazon VPC 端点(Amazon PrivateLink)
借助 Amazon VPC,您可以在 Virtual Private Cloud (VPC) 中启动Amazon资源(例如 Aurora 数据库集群和应用程序)。Amazon PrivateLink 在亚马逊网络上提供了 VPC 和Amazon服务之间的私有连接,这种连接具有高度的安全性。通过使用 Amazon PrivateLink,您可以创建 Amazon VPC 终端节点,这可让您根据 Amazon VPC 跨不同的账号和 VPC 连接到服务。有关 Amazon PrivateLink 的更多信息,请参阅 Amazon Virtual Private Cloud 用户指南中的 VPC 终端节点服务(Amazon PrivateLink)。
您可以使用 Amazon VPC 端点调用 RDS 数据 API(数据 API)。使用 Amazon VPC 端点可保持 Amazon VPC 中的应用程序与 Amazon 网络中数据 API 间的流量,而无需使用公有 IP 地址。Amazon VPC 终端节点可帮助您遵守与管理公共互联网连接有关的合规性和法规要求。例如,如果您使用 Amazon VPC 端点,则可保持 Amazon EC2 实例上运行的应用程序和包含端点的 VPC 中的数据 API 之间的流量。
创建 Amazon VPC 终端节点后,便能开始使用此终端节点,而无需在应用程序中进行任何代码或配置更改。
为数据 API 创建 Amazon VPC 端点
登录到Amazon Web Services Management Console并打开 Amazon VPC 控制台,网址:https://console.aws.amazon.com/vpc/
。 -
选择终端节点,然后选择创建终端节点。
-
在 Create Endpoint (创建终端节点) 页面上,为 Service category (服务类别) 选择 Amazon services (Amazon 服务)。对于 Service Name (服务名称),请选择 rds-data。
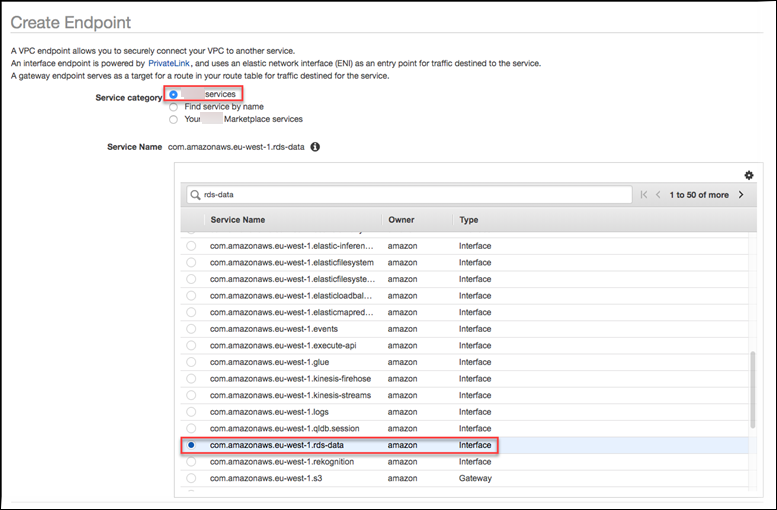
-
对于 VPC,选择要在其中创建终端节点的 VPC。
选择包含用于进行 Data API 调用的应用程序的 VPC。
-
对于 Subnets(子网),请为运行应用程序的 Amazon 服务所使用的每个可用区 (AZ) 选择子网。
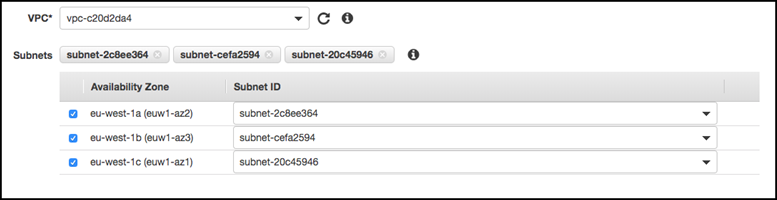
要创建 Amazon VPC 终端节点,请指定终端节点可在其中访问的私有 IP 地址范围。为此,请为每个可用区选择子网。执行此操作会将 VPC 终端节点限制为特定于每个可用区的私有 IP 地址范围,并且还会在每个可用区中创建一个 Amazon VPC 终端节点。
-
对于 Enable DNS Name (启用 DNS 名称),选择 Enable for this endpoint (为此终端节点启用)。

私有 DNS 会将标准 Data API DNS 主机名 (
https://rds-data.) 解析为与特定于 Amazon VPC 终端节点的 DNS 主机名关联的私有 IP 地址。因此,您可以使用 Amazon CLI 或 Amazon SDK 访问数据 API VPC 端点,而无需进行任何代码或配置更改来更新数据 API 的端点 URL。region.amazonaws.com -
对于安全组,选择要与 Amazon VPC 终端节点关联的安全组。
选择允许访问运行应用程序的 Amazon 服务的安全组。例如,如果 Amazon EC2 实例正在运行您的应用程序,请选择允许访问 Amazon EC2 实例的安全组。利用安全组,您可以控制从 VPC 中的资源发送到 Amazon VPC 终端节点的流量。
-
对于 Policy (策略),选择 Full Access (完全访问) 以允许 Amazon VPC 中的任何人通过此终端节点访问 Data API。或者,选择 Custom (自定义) 以指定限制访问的策略。
如果选择 Custom (自定义),请在策略创建工具中输入策略。
-
选择Create endpoint。
创建终端节点后,选择 Amazon Web Services Management Console中的链接以查看终端节点详细信息。
终端节点 Details (详细信息) 选项卡将显示在创建 Amazon VPC 终端节点时生成的 DNS 主机名。
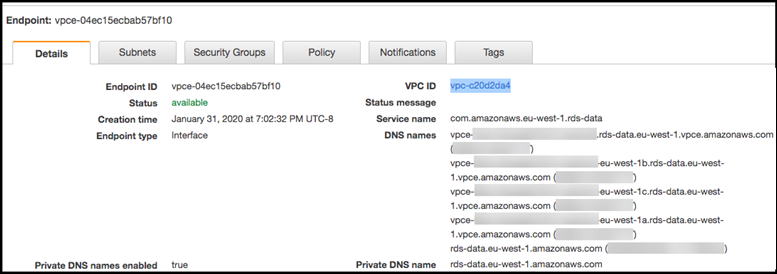
您可以使用标准终端节点 (rds-data.) 或特定于 VPC 的终端节点之一来调用 Amazon VPC 中的 Data API。标准 Data API 终端节点将自动路由到 Amazon VPC 终端节点。发生此路由的原因是,在创建 Amazon VPC 终端节点时启用了私有 DNS 主机名。region.amazonaws.com
在数据 API 调用中使用 Amazon VPC 端点时,应用程序和数据 API 之间的所有流量将保留在包含它们的 Amazon VPC 中。可以将 Amazon VPC 终端节点用于任何类型的 Data API 调用。有关调用数据 API 的信息,请参阅调用 RDS 数据 API。
调用 RDS 数据 API
在为 Aurora 数据库集群启用 RDS 数据 API(数据 API)后,您可以使用数据 API 或 Amazon CLI 在 Aurora 数据库集群上运行 SQL 语句。数据 API 支持 Amazon SDK 所支持的编程语言。有关更多信息,请参阅用于在Amazon上进行构建的工具
注意
目前,数据 API 不支持通用唯一标识符(UUID)数组。
数据 API 提供了以下操作以执行 SQL 语句。
|
Data API 操作 |
Amazon CLI command |
描述 |
|---|---|---|
|
对数据库运行 SQL 语句。 |
||
|
对数据数组运行批处理 SQL 语句,以执行批量更新和插入操作。您可以使用参数集数组运行数据操作语言 (DML) 语句。相比单个插入和更新语句,批处理 SQL 语句可提供显著的性能改进。 |
您可以使用任一操作来运行单独的 SQL 语句或运行事务。针对事务,数据 API 提供了以下操作。
|
Data API 操作 |
Amazon CLI command |
描述 |
|---|---|---|
|
开始 SQL 事务。 |
||
|
结束 SQL 事务并提交更改。 |
||
|
执行事务回滚。 |
执行 SQL 语句和支持事务的操作具有以下常用 Data API 参数和 Amazon CLI 选项。某些操作支持其他参数或选项。
|
Data API 操作参数 |
Amazon CLI 命令选项 |
必需 |
描述 |
|---|---|---|---|
|
|
|
是 |
Aurora 数据库集群的 Amazon 资源名称(ARN)。 |
|
|
|
是 |
允许访问数据库集群的密钥的名称或 ARN。 |
您可以在对 ExecuteStatement 和 BatchExecuteStatement 的 Data API 调用中使用参数,或在运行 Amazon CLI 命令 execute-statement 和 batch-execute-statement 时使用。要使用参数,请在 SqlParameter 数据类型中指定名称/值对。您可以使用 Field 数据类型指定值。下表将 Java 数据库连接 (JDBC) 数据类型映射到您在 Data API 调用中指定的数据类型。
|
JDBC 数据类型 |
Data API 数据类型 |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
其他类型(包括与日期和时间有关的类型) |
|
注意
您可以在 Data API 调用中为数据库返回的 LONG 值指定 LONG 或 STRING 数据类型。我们建议您这样操作,以避免在使用 JavaScript 时发生超大数字失去精准性的情况。
某些类型(例如 DECIMAL 和 TIME)需要提示,以便数据 API 将 String 值作为正确的类型传递给数据库。要使用提示,typeHint 数据类型中需要包含 SqlParameter 的值。typeHint 的可能值如下所示:
-
DATE– 相应的String参数值作为DATE类型的对象发送到数据库。接受的格式为YYYY-MM-DD。 -
DECIMAL– 相应的String参数值作为DECIMAL类型的对象发送到数据库。 -
JSON– 相应的String参数值作为JSON类型的对象发送到数据库。 -
TIME– 相应的String参数值作为TIME类型的对象发送到数据库。接受的格式为HH:MM:SS[.FFF]。 -
TIMESTAMP– 相应的String参数值作为TIMESTAMP类型的对象发送到数据库。接受的格式为YYYY-MM-DD HH:MM:SS[.FFF]。 UUID– 相应的String参数值作为UUID类型的对象发送到数据库。
注意
对于 Amazon Aurora PostgreSQL,数据 API 始终以 UTC 时区返回 Aurora PostgreSQL 数据类型 TIMESTAMPTZ。
使用 Amazon CLI 调用 RDS 数据 API
您可以使用 Amazon CLI 调用 RDS 数据 API(数据 API)。
以下示例将 Amazon CLI 用于数据 API。有关更多信息,请参阅 Data API 的 Amazon CLI 参考。
在每个示例中,将数据库集群的 Amazon 资源名称(ARN)替换为 Aurora 数据库集群的 ARN。另外,将密钥 ARN 替换为 Secrets Manager 中允许访问该数据库集群的密钥的 ARN。
注意
Amazon CLI 可以使用 JSON 设置响应格式。
启动 SQL 事务
您可以使用 aws rds-data
begin-transaction CLI 命令启动 SQL 事务。调用会返回事务标识符。
重要
如果三分钟之内没有任何调用使用其事务 ID,事务将超时。如果事务在提交之前超时,则会自动回滚。
事务内的数据定义语言 (DDL) 语句会导致隐式提交。我们建议您在单独的 execute-statement 命令中,采用 --continue-after-timeout 选项运行每个 DDL 语句。
除了常用选项之外,请指定提供数据库名称的 --database 选项。
例如,以下 CLI 命令开始 SQL 事务。
对于 Linux、macOS 或 Unix:
aws rds-data begin-transaction --resource-arn "arn:aws:rds:us-east-1:123456789012:cluster:mydbcluster" \ --database "mydb" --secret-arn "arn:aws:secretsmanager:us-east-1:123456789012:secret:mysecret"
对于 Windows:
aws rds-data begin-transaction --resource-arn "arn:aws:rds:us-east-1:123456789012:cluster:mydbcluster" ^ --database "mydb" --secret-arn "arn:aws:secretsmanager:us-east-1:123456789012:secret:mysecret"
以下为响应示例。
{
"transactionId": "ABC1234567890xyz"
}运行 SQL 语句
您可以使用 aws rds-data execute-statement CLI 命令运行 SQL 语句。
您可以采用 --transaction-id 选项指定事务标识符,从而在事务中运行 SQL 语句。您可以使用 aws rds-data begin-transaction CLI 命令开始事务。您可以使用 aws rds-data
commit-transaction CLI 命令结束并提交事务。
重要
如果未指定 --transaction-id 选项,则调用产生的更改将自动提交。
除常用选项之外,还可指定以下选项:
-
--sql(必需)– 在数据库集群上运行的 SQL 语句。 -
--transaction-id(可选)– 使用begin-transactionCLI 命令开始的事务的标识符。指定您希望包含 SQL 语句的事务的事务 ID。 -
--parameters(可选)– SQL 语句的参数。 -
--include-result-metadata | --no-include-result-metadata(可选)– 指定是否在结果中包含元数据的值。默认为--no-include-result-metadata。 -
--database(可选)– 数据库的名称。当您在先前的请求中运行
--sql "use之后运行 SQL 语句时,database_name;"--database选项可能不起作用。建议您使用--database选项,而不是运行--sql "use语句。database_name;" -
--continue-after-timeout | --no-continue-after-timeout(可选)– 指定在调用超时后是否继续运行语句的值。默认为--no-continue-after-timeout。对于数据定义语言 (DDL) 语句,我们建议在调用超时后继续运行语句,以避免错误以及数据结构损坏的可能性。
-
--format-records-as "JSON"|"NONE"– 一个可选值,它指定是否将结果集格式化为 JSON 字符串。默认为"NONE"。有关处理 JSON 结果集的使用信息,请参阅处理 JSON 格式的查询结果。
数据库集群为调用返回响应。
注意
响应大小限制为 1MiB。如果调用返回的响应数据超过 1MiB,则调用将终止。
对于 Aurora Serverless v1,每秒最大请求数为 1000。对于所有其它受支持的数据库,没有限制。
例如,以下 CLI 命令运行单个 SQL 语句,并在结果中省略元数据(默认设置)。
对于 Linux、macOS 或 Unix:
aws rds-data execute-statement --resource-arn "arn:aws:rds:us-east-1:123456789012:cluster:mydbcluster" \ --database "mydb" --secret-arn "arn:aws:secretsmanager:us-east-1:123456789012:secret:mysecret" \ --sql "select * from mytable"
对于 Windows:
aws rds-data execute-statement --resource-arn "arn:aws:rds:us-east-1:123456789012:cluster:mydbcluster" ^ --database "mydb" --secret-arn "arn:aws:secretsmanager:us-east-1:123456789012:secret:mysecret" ^ --sql "select * from mytable"
以下为响应示例。
{
"numberOfRecordsUpdated": 0,
"records": [
[
{
"longValue": 1
},
{
"stringValue": "ValueOne"
}
],
[
{
"longValue": 2
},
{
"stringValue": "ValueTwo"
}
],
[
{
"longValue": 3
},
{
"stringValue": "ValueThree"
}
]
]
}以下 CLI 命令通过指定 --transaction-id 选项,在事务中运行单个 SQL 语句。
对于 Linux、macOS 或 Unix:
aws rds-data execute-statement --resource-arn "arn:aws:rds:us-east-1:123456789012:cluster:mydbcluster" \ --database "mydb" --secret-arn "arn:aws:secretsmanager:us-east-1:123456789012:secret:mysecret" \ --sql "update mytable set quantity=5 where id=201" --transaction-id "ABC1234567890xyz"
对于 Windows:
aws rds-data execute-statement --resource-arn "arn:aws:rds:us-east-1:123456789012:cluster:mydbcluster" ^ --database "mydb" --secret-arn "arn:aws:secretsmanager:us-east-1:123456789012:secret:mysecret" ^ --sql "update mytable set quantity=5 where id=201" --transaction-id "ABC1234567890xyz"
以下为响应示例。
{
"numberOfRecordsUpdated": 1
}以下 CLI 命令使用参数运行单个 SQL 语句。
对于 Linux、macOS 或 Unix:
aws rds-data execute-statement --resource-arn "arn:aws:rds:us-east-1:123456789012:cluster:mydbcluster" \ --database "mydb" --secret-arn "arn:aws:secretsmanager:us-east-1:123456789012:secret:mysecret" \ --sql "insert intomytablevalues (:id,:val)" --parameters "[{\"name\": \"id\", \"value\": {\"longValue\":1}},{\"name\": \"val\", \"value\": {\"stringValue\": \"value1\"}}]"
对于 Windows:
aws rds-data execute-statement --resource-arn "arn:aws:rds:us-east-1:123456789012:cluster:mydbcluster" ^ --database "mydb" --secret-arn "arn:aws:secretsmanager:us-east-1:123456789012:secret:mysecret" ^ --sql "insert intomytablevalues (:id,:val)" --parameters "[{\"name\": \"id\", \"value\": {\"longValue\":1}},{\"name\": \"val\", \"value\": {\"stringValue\": \"value1\"}}]"
以下为响应示例。
{
"numberOfRecordsUpdated": 1
}以下 CLI 命令运行数据定义语言 (DDL) SQL 语句。DDL 语句将列 job 重命名为列 role。
重要
对于 DDL 语句,我们建议在调用超时后继续运行语句。如果 DDL 语句在结束运行之前终止,则可能导致错误以及数据结构损坏。要在调用超时后继续运行语句,请指定 --continue-after-timeout 选项。
对于 Linux、macOS 或 Unix:
aws rds-data execute-statement --resource-arn "arn:aws:rds:us-east-1:123456789012:cluster:mydbcluster" \ --database "mydb" --secret-arn "arn:aws:secretsmanager:us-east-1:123456789012:secret:mysecret" \ --sql "alter table mytable change column job role varchar(100)" --continue-after-timeout
对于 Windows:
aws rds-data execute-statement --resource-arn "arn:aws:rds:us-east-1:123456789012:cluster:mydbcluster" ^ --database "mydb" --secret-arn "arn:aws:secretsmanager:us-east-1:123456789012:secret:mysecret" ^ --sql "alter table mytable change column job role varchar(100)" --continue-after-timeout
以下为响应示例。
{
"generatedFields": [],
"numberOfRecordsUpdated": 0
}注意
Aurora PostgreSQL 不支持 generatedFields 数据。若要获取生成字段的值,请使用 RETURNING 子句。有关更多信息,请参阅 PostgreSQL 文档中的从已修改的行返回数据
对数据数组运行批处理 SQL 语句
您可以通过使用 aws rds-data batch-execute-statement CLI 命令,对数据数组运行批处理 SQL 语句。您可以使用该命令执行批量导入或更新操作。
您可以采用 --transaction-id 选项指定事务标识符,从而在事务中运行 SQL 语句。您可以使用 aws rds-data
begin-transaction CLI 命令开始事务。您可以使用 aws rds-data commit-transaction CLI 命令结束并提交事务。
重要
如果未指定 --transaction-id 选项,则调用产生的更改将自动提交。
除常用选项之外,还可指定以下选项:
-
--sql(必需)– 在数据库集群上运行的 SQL 语句。提示
对于与 MySQL 兼容的语句,不要在
--sql参数末尾包含分号。尾随的分号可能会导致语法错误。 -
--transaction-id(可选)– 使用begin-transactionCLI 命令开始的事务的标识符。指定您希望包含 SQL 语句的事务的事务 ID。 -
--parameter-set(可选)– 批处理操作的参数集。 -
--database(可选)– 数据库的名称。
数据库集群返回调用的响应。
注意
参数集数量没有固定的上限。但是,通过数据 API 提交的 HTTP 请求的最大大小为 4MiB。如果请求超出此限制,数据 API 将返回错误并且不处理请求。此 4MiB 限制包括 HTTP 标头的大小和请求中的 JSON 符号。因此,可以包含的参数集数取决于因素的组合,例如 SQL 语句的大小和每个参数集的大小。
响应大小限制为 1MiB。如果调用返回的响应数据超过 1MiB,则调用将终止。
对于 Aurora Serverless v1,每秒最大请求数为 1000。对于所有其它受支持的数据库,没有限制。
例如,以下 CLI 命令采用参数集对数据数组运行批处理 SQL 语句。
对于 Linux、macOS 或 Unix:
aws rds-data batch-execute-statement --resource-arn "arn:aws:rds:us-east-1:123456789012:cluster:mydbcluster" \ --database "mydb" --secret-arn "arn:aws:secretsmanager:us-east-1:123456789012:secret:mysecret" \ --sql "insert intomytablevalues (:id,:val)" \ --parameter-sets "[[{\"name\": \"id\", \"value\": {\"longValue\":1}},{\"name\": \"val\", \"value\": {\"stringValue\": \"ValueOne\"}}], [{\"name\": \"id\", \"value\": {\"longValue\":2}},{\"name\": \"val\", \"value\": {\"stringValue\": \"ValueTwo\"}}], [{\"name\": \"id\", \"value\": {\"longValue\":3}},{\"name\": \"val\", \"value\": {\"stringValue\": \"ValueThree\"}}]]"
对于 Windows:
aws rds-data batch-execute-statement --resource-arn "arn:aws:rds:us-east-1:123456789012:cluster:mydbcluster" ^ --database "mydb" --secret-arn "arn:aws:secretsmanager:us-east-1:123456789012:secret:mysecret" ^ --sql "insert intomytablevalues (:id,:val)" ^ --parameter-sets "[[{\"name\": \"id\", \"value\": {\"longValue\":1}},{\"name\": \"val\", \"value\": {\"stringValue\": \"ValueOne\"}}], [{\"name\": \"id\", \"value\": {\"longValue\":2}},{\"name\": \"val\", \"value\": {\"stringValue\": \"ValueTwo\"}}], [{\"name\": \"id\", \"value\": {\"longValue\":3}},{\"name\": \"val\", \"value\": {\"stringValue\": \"ValueThree\"}}]]"
注意
--parameter-sets 选项中请勿包括换行符。
提交 SQL 事务
通过使用 aws rds-data commit-transaction CLI 命令,您可以结束使用 aws rds-data
begin-transaction 开始的 SQL 事务并提交更改。
除常用选项之外,还可指定以下选项:
-
--transaction-id(必需)– 使用begin-transactionCLI 命令开始的事务的标识符。指定您希望结束并提交的事务的事务 ID。
例如,以下 CLI 命令结束 SQL 事务并提交更改。
对于 Linux、macOS 或 Unix:
aws rds-data commit-transaction --resource-arn "arn:aws:rds:us-east-1:123456789012:cluster:mydbcluster" \ --secret-arn "arn:aws:secretsmanager:us-east-1:123456789012:secret:mysecret" \ --transaction-id "ABC1234567890xyz"
对于 Windows:
aws rds-data commit-transaction --resource-arn "arn:aws:rds:us-east-1:123456789012:cluster:mydbcluster" ^ --secret-arn "arn:aws:secretsmanager:us-east-1:123456789012:secret:mysecret" ^ --transaction-id "ABC1234567890xyz"
以下为响应示例。
{
"transactionStatus": "Transaction Committed"
}回滚 SQL 事务
通过使用 aws rds-data rollback-transaction CLI 命令,您可以回滚使用 aws rds-data
begin-transaction 开始的 SQL 事务。回滚事务会取消其更改。
重要
如果事务 ID 已过期,事务将自动回滚。在此情况下,指定已过期事务 ID 的 aws rds-data rollback-transaction 命令将返回错误。
除常用选项之外,还可指定以下选项:
-
--transaction-id(必需)– 使用begin-transactionCLI 命令开始的事务的标识符。指定您希望回滚的事务的事务 ID。
例如,以下 Amazon CLI 命令回滚 SQL 事务。
对于 Linux、macOS 或 Unix:
aws rds-data rollback-transaction --resource-arn "arn:aws:rds:us-east-1:123456789012:cluster:mydbcluster" \ --secret-arn "arn:aws:secretsmanager:us-east-1:123456789012:secret:mysecret" \ --transaction-id "ABC1234567890xyz"
对于 Windows:
aws rds-data rollback-transaction --resource-arn "arn:aws:rds:us-east-1:123456789012:cluster:mydbcluster" ^ --secret-arn "arn:aws:secretsmanager:us-east-1:123456789012:secret:mysecret" ^ --transaction-id "ABC1234567890xyz"
以下为响应示例。
{
"transactionStatus": "Rollback Complete"
}从 Python 应用程序调用 RDS 数据 API
您可以从 Python 应用程序调用 RDS 数据 API(数据 API)。
以下示例使用适用于 Python 的 Amazon 开发工具包 (Boto)。有关 Boto 的更多信息,请参阅适用于 Python 的 Amazon 开发工具包 (Boto 3 ) 文档
在每个示例中,将数据库集群的 Amazon 资源名称(ARN)替换为您的 Aurora 数据库集群的 ARN。另外,将密钥 ARN 替换为 Secrets Manager 中允许访问该数据库集群的密钥的 ARN。
运行 SQL 查询
您可以运行 SELECT 语句并使用 Python 应用程序提取结果。
以下示例运行 SQL 查询。
import boto3
rdsData = boto3.client('rds-data')
cluster_arn = 'arn:aws:rds:us-east-1:123456789012:cluster:mydbcluster'
secret_arn = 'arn:aws:secretsmanager:us-east-1:123456789012:secret:mysecret'
response1 = rdsData.execute_statement(
resourceArn = cluster_arn,
secretArn = secret_arn,
database = 'mydb',
sql = 'select * from employees limit 3')
print (response1['records'])
[
[
{
'longValue': 1
},
{
'stringValue': 'ROSALEZ'
},
{
'stringValue': 'ALEJANDRO'
},
{
'stringValue': '2016-02-15 04:34:33.0'
}
],
[
{
'longValue': 1
},
{
'stringValue': 'DOE'
},
{
'stringValue': 'JANE'
},
{
'stringValue': '2014-05-09 04:34:33.0'
}
],
[
{
'longValue': 1
},
{
'stringValue': 'STILES'
},
{
'stringValue': 'JOHN'
},
{
'stringValue': '2017-09-20 04:34:33.0'
}
]
]运行 DML SQL 语句
您可以运行数据操作语言 (DML) 语句,在数据库中插入、更新或删除数据。在 DML 语句中也可以使用参数。
重要
如果调用由于未包含 transactionID 参数而不属于事务的一部分,则调用产生的更改将自动提交。
以下示例运行插入 SQL 语句并使用参数。
import boto3
cluster_arn = 'arn:aws:rds:us-east-1:123456789012:cluster:mydbcluster'
secret_arn = 'arn:aws:secretsmanager:us-east-1:123456789012:secret:mysecret'
rdsData = boto3.client('rds-data')
param1 = {'name':'firstname', 'value':{'stringValue': 'JACKSON'}}
param2 = {'name':'lastname', 'value':{'stringValue': 'MATEO'}}
paramSet = [param1, param2]
response2 = rdsData.execute_statement(resourceArn=cluster_arn,
secretArn=secret_arn,
database='mydb',
sql='insert into employees(first_name, last_name) VALUES(:firstname, :lastname)',
parameters = paramSet)
print (response2["numberOfRecordsUpdated"])运行 SQL 事务
您可以通过 Python 应用程序开始 SQL 事务、运行一个或多个 SQL 语句,然后提交更改。
重要
如果三分钟之内没有任何调用使用其事务 ID,事务将超时。如果事务在提交之前超时,则会自动回滚。
如果未指定事务 ID,则调用产生的更改将自动提交。
以下示例运行 SQL 事务在表中插入行。
import boto3
rdsData = boto3.client('rds-data')
cluster_arn = 'arn:aws:rds:us-east-1:123456789012:cluster:mydbcluster'
secret_arn = 'arn:aws:secretsmanager:us-east-1:123456789012:secret:mysecret'
tr = rdsData.begin_transaction(
resourceArn = cluster_arn,
secretArn = secret_arn,
database = 'mydb')
response3 = rdsData.execute_statement(
resourceArn = cluster_arn,
secretArn = secret_arn,
database = 'mydb',
sql = 'insert into employees(first_name, last_name) values('XIULAN', 'WANG')',
transactionId = tr['transactionId'])
cr = rdsData.commit_transaction(
resourceArn = cluster_arn,
secretArn = secret_arn,
transactionId = tr['transactionId'])
cr['transactionStatus']
'Transaction Committed'
response3['numberOfRecordsUpdated']
1注意
如果运行数据定义语言 (DDL) 语句,我们建议在调用超时后继续运行语句。如果 DDL 语句在结束运行之前终止,则可能导致错误以及数据结构损坏。要在调用超时后继续运行语句,请将 continueAfterTimeout 参数设置为 true。
从 Java 应用程序调用 RDS 数据 API
您可以从 Java 应用程序调用 RDS 数据 API(数据 API)。
以下示例使用适用于 Java 的 Amazon 开发工具包。有关更多信息,请参阅 Amazon SDK for Java 开发人员指南。
在每个示例中,将数据库集群的 Amazon 资源名称(ARN)替换为您的 Aurora 数据库集群的 ARN。另外,将密钥 ARN 替换为 Secrets Manager 中允许访问该数据库集群的密钥的 ARN。
运行 SQL 查询
您可以运行 SELECT 语句并使用 Java 应用程序提取结果。
以下示例运行 SQL 查询。
package com.amazonaws.rdsdata.examples;
import com.amazonaws.services.rdsdata.AWSRDSData;
import com.amazonaws.services.rdsdata.AWSRDSDataClient;
import com.amazonaws.services.rdsdata.model.ExecuteStatementRequest;
import com.amazonaws.services.rdsdata.model.ExecuteStatementResult;
import com.amazonaws.services.rdsdata.model.Field;
import java.util.List;
public class FetchResultsExample {
public static final String RESOURCE_ARN = "arn:aws:rds:us-east-1:123456789012:cluster:mydbcluster";
public static final String SECRET_ARN = "arn:aws:secretsmanager:us-east-1:123456789012:secret:mysecret";
public static void main(String[] args) {
AWSRDSData rdsData = AWSRDSDataClient.builder().build();
ExecuteStatementRequest request = new ExecuteStatementRequest()
.withResourceArn(RESOURCE_ARN)
.withSecretArn(SECRET_ARN)
.withDatabase("mydb")
.withSql("select * from mytable");
ExecuteStatementResult result = rdsData.executeStatement(request);
for (List<Field> fields: result.getRecords()) {
String stringValue = fields.get(0).getStringValue();
long numberValue = fields.get(1).getLongValue();
System.out.println(String.format("Fetched row: string = %s, number = %d", stringValue, numberValue));
}
}
}运行 SQL 事务
您可以通过 Java 应用程序开始 SQL 事务、运行一个或多个 SQL 语句,然后提交更改。
重要
如果三分钟之内没有任何调用使用其事务 ID,事务将超时。如果事务在提交之前超时,则会自动回滚。
如果未指定事务 ID,则调用产生的更改将自动提交。
以下示例运行 SQL 事务。
package com.amazonaws.rdsdata.examples;
import com.amazonaws.services.rdsdata.AWSRDSData;
import com.amazonaws.services.rdsdata.AWSRDSDataClient;
import com.amazonaws.services.rdsdata.model.BeginTransactionRequest;
import com.amazonaws.services.rdsdata.model.BeginTransactionResult;
import com.amazonaws.services.rdsdata.model.CommitTransactionRequest;
import com.amazonaws.services.rdsdata.model.ExecuteStatementRequest;
public class TransactionExample {
public static final String RESOURCE_ARN = "arn:aws:rds:us-east-1:123456789012:cluster:mydbcluster";
public static final String SECRET_ARN = "arn:aws:secretsmanager:us-east-1:123456789012:secret:mysecret";
public static void main(String[] args) {
AWSRDSData rdsData = AWSRDSDataClient.builder().build();
BeginTransactionRequest beginTransactionRequest = new BeginTransactionRequest()
.withResourceArn(RESOURCE_ARN)
.withSecretArn(SECRET_ARN)
.withDatabase("mydb");
BeginTransactionResult beginTransactionResult = rdsData.beginTransaction(beginTransactionRequest);
String transactionId = beginTransactionResult.getTransactionId();
ExecuteStatementRequest executeStatementRequest = new ExecuteStatementRequest()
.withTransactionId(transactionId)
.withResourceArn(RESOURCE_ARN)
.withSecretArn(SECRET_ARN)
.withSql("INSERT INTO test_table VALUES ('hello world!')");
rdsData.executeStatement(executeStatementRequest);
CommitTransactionRequest commitTransactionRequest = new CommitTransactionRequest()
.withTransactionId(transactionId)
.withResourceArn(RESOURCE_ARN)
.withSecretArn(SECRET_ARN);
rdsData.commitTransaction(commitTransactionRequest);
}
}注意
如果运行数据定义语言 (DDL) 语句,我们建议在调用超时后继续运行语句。如果 DDL 语句在结束运行之前终止,则可能导致错误以及数据结构损坏。要在调用超时后继续运行语句,请将 continueAfterTimeout 参数设置为 true。
运行批处理 SQL 操作
您可以使用 Java 应用程序,对数据数组运行批量插入和更新操作。您可以使用参数集数组运行 DML 语句。
重要
如果未指定事务 ID,则调用产生的更改将自动提交。
以下示例运行批处理插入操作。
package com.amazonaws.rdsdata.examples;
import com.amazonaws.services.rdsdata.AWSRDSData;
import com.amazonaws.services.rdsdata.AWSRDSDataClient;
import com.amazonaws.services.rdsdata.model.BatchExecuteStatementRequest;
import com.amazonaws.services.rdsdata.model.Field;
import com.amazonaws.services.rdsdata.model.SqlParameter;
import java.util.Arrays;
public class BatchExecuteExample {
public static final String RESOURCE_ARN = "arn:aws:rds:us-east-1:123456789012:cluster:mydbcluster";
public static final String SECRET_ARN = "arn:aws:secretsmanager:us-east-1:123456789012:secret:mysecret";
public static void main(String[] args) {
AWSRDSData rdsData = AWSRDSDataClient.builder().build();
BatchExecuteStatementRequest request = new BatchExecuteStatementRequest()
.withDatabase("test")
.withResourceArn(RESOURCE_ARN)
.withSecretArn(SECRET_ARN)
.withSql("INSERT INTO test_table2 VALUES (:string, :number)")
.withParameterSets(Arrays.asList(
Arrays.asList(
new SqlParameter().withName("string").withValue(new Field().withStringValue("Hello")),
new SqlParameter().withName("number").withValue(new Field().withLongValue(1L))
),
Arrays.asList(
new SqlParameter().withName("string").withValue(new Field().withStringValue("World")),
new SqlParameter().withName("number").withValue(new Field().withLongValue(2L))
)
));
rdsData.batchExecuteStatement(request);
}
}使用适用于 RDS 数据 API 的 Java 客户端库
您可以下载并使用适用于 RDS 数据 API(数据 API)的 Java 客户端库。此 Java 客户端库提供了使用数据 API 的另一种方法。使用该库,您可以将客户端类映射到数据 API 的请求和响应。这种映射支持可以简化与某些特定 Java 类型(如 Date、Time 和 BigDecimal)的集成。
下载适用于 Data API 的 Java 客户端库
Data API Java 客户端库是 GitHub 中是开源的,位于以下位置:
https://github.com/awslabs/rds-data-api-client-library-java
您可以从源文件手动构建该库,但最佳实践是使用 Apache Maven 依赖项管理来使用该库。将以下依赖项添加到 Maven POM 文件中。
对于与 Amazon SDK 2.x 兼容的版本 2.x,请使用以下命令:
<dependency> <groupId>software.amazon.rdsdata</groupId> <artifactId>rds-data-api-client-library-java</artifactId> <version>2.0.0</version> </dependency>
对于与 Amazon SDK 1.x 兼容的版本 1.x,请使用以下命令:
<dependency> <groupId>software.amazon.rdsdata</groupId> <artifactId>rds-data-api-client-library-java</artifactId> <version>1.0.8</version> </dependency>
Java 客户端库示例
在下面,您可以找到一些使用 Data API Java 客户端库的常见示例。这些示例假设您有一个包含两列(accountId 和 name)的表 accounts。您还拥有以下数据传输对象 (DTO)。
public class Account {
int accountId;
String name;
// getters and setters omitted
}该客户端库使您可以将 DTO 作为输入参数进行传递。以下示例展示了如何将客户 DTO 映射到输入参数集。
var account1 = new Account(1, "John");
var account2 = new Account(2, "Mary");
client.forSql("INSERT INTO accounts(accountId, name) VALUES(:accountId, :name)")
.withParamSets(account1, account2)
.execute();在某些情况下,使用简单值作为输入参数会更容易。可以使用以下语法来做到这一点。
client.forSql("INSERT INTO accounts(accountId, name) VALUES(:accountId, :name)")
.withParameter("accountId", 3)
.withParameter("name", "Zhang")
.execute();下面是另一个使用简单值作为输入参数的示例。
client.forSql("INSERT INTO accounts(accountId, name) VALUES(?, ?)", 4, "Carlos") .execute();
当返回结果时,客户端库提供到 DTO 的自动映射。以下示例展示了如何将结果映射到您的 DTO。
List<Account> result = client.forSql("SELECT * FROM accounts")
.execute()
.mapToList(Account.class);
Account result = client.forSql("SELECT * FROM accounts WHERE account_id = 1")
.execute()
.mapToSingle(Account.class);在很多情况下,数据库结果集只包含一个值。为了简化检索此类结果的过程,客户端库提供了以下 API:
int numberOfAccounts = client.forSql("SELECT COUNT(*) FROM accounts")
.execute()
.singleValue(Integer.class);注意
mapToList 函数将 SQL 结果集转换为用户定义的对象列表。我们不支持在对 Java 客户端库的 ExecuteStatement 调用中使用 .withFormatRecordsAs(RecordsFormatType.JSON) 语句,因为它具有相同的目的。有关更多信息,请参阅处理 JSON 格式的查询结果。
处理 JSON 格式的查询结果
当您调用 ExecuteStatement 操作时,可以选择将查询结果作为 JSON 格式的字符串返回。这样,您就可以使用编程语言的 JSON 解析功能来解释和重新格式化结果集。这样做有助于避免编写额外的代码来循环浏览结果集并解释每个列值。
要请求 JSON 格式的结果集,您需要传递值为 JSON 的可选 formatRecordsAs 参数。JSON 格式的结果集将在 ExecuteStatementResponse 结构的 formattedRecords 字段中返回。
BatchExecuteStatement 操作不返回结果集。因此,JSON 选项不适用于该操作。
要自定义 JSON 哈希结构中的键,请在结果集中定义列别名。为此,您可以使用 SQL 查询的列列表中的 AS 子句。
您可以使用 JSON 功能使结果集更易于阅读,并将其内容映射到特定于语言的框架。由于 ASCII 编码的结果集的卷大于默认表示形式,因此如果查询返回大量的行或较大的列值,占用的内存超过应用程序可用的内存,则您可以选择默认表示形式。
检索 JSON 格式的查询结果
要以 JSON 字符串的形式接收结果集,请在 ExecuteStatement 调用中包括 .withFormatRecordsAs(RecordsFormatType.JSON)。返回值在 formattedRecords 字段中以 JSON 字符串的形式返回。在本例中,columnMetadata 为 null。列标签是表示每行的对象的键。这些列名称在结果集中的每一行都会重复出现。列值是带引号的字符串、数值或表示 true、false 或 null 的特殊值。JSON 响应中不会保留列元数据,例如长度约束以及数字和字符串的精确类型。
如果您省略 .withFormatRecordsAs() 调用或指定 NONE 的参数,系统将使用 Records 和 columnMetadata 字段以二进制格式返回结果集。
数据类型映射
结果集中的 SQL 值映射到一组较小的 JSON 类型。这些值在 JSON 中表示为字符串、数字和一些特殊常量,例如 true、false 和null。您可以根据编程语言的不同,使用强类型或弱类型将这些值转换为应用程序中的变量。
|
JDBC 数据类型 |
JSON 数据类型 |
|---|---|
|
|
默认情况下为数字。如果 |
|
|
数字 |
|
|
默认情况下为字符串。如果 |
|
|
String |
|
|
布尔值 |
|
|
base64 编码的字符串。 |
|
|
String |
|
|
数组 |
|
|
|
|
其他类型(包括与日期和时间有关的类型) |
String |
排查问题
JSON 响应限制为 10 兆字节。如果响应超过此限制,则您的程序会收到 BadRequestException 错误。在这种情况下,您可以使用以下方法之一解决该错误:
-
减少结果集中的行数。为此,请添加
LIMIT子句。您可以通过提交多个带有LIMIT和OFFSET子句的查询,将一个大型结果集拆分为多个较小的结果集。如果结果集中包含被应用程序逻辑筛选掉的行,您可以通过在
WHERE子句中添加更多条件,从结果集中删除这些行。 -
减少结果集中的列数。为此,请从查询的选择列表中删除项目。
-
通过在查询中使用列别名来缩短列标签。对于结果集中的每一行,每个列名都会在 JSON 字符串中重复出现。因此,具有长列名和许多行的查询结果可能会超过大小限制。特别是,对复杂的表达式使用列别名,以避免在 JSON 字符串中重复整个表达式。
-
虽然在 SQL 中可以使用列别名来生成具有多个同名列的结果集,但在 JSON 中不允许有重复的键名。如果您请求 JSON 格式的结果集,并且多个列具有相同名称,则 RDS Data API 将返回错误。因此,请确保所有列标签都具有唯一的名称。
示例
以下 Java 示例演示了如何调用 ExecuteStatement 并将响应作为 JSON 格式的字符串,然后解释结果集。用适当的值替换 databaseName、secretStoreArn 和 clusterArn 参数。
以下 Java 示例演示了一个在结果集中返回十进制数值的查询。assertThat 调用会测试响应的字段是否具有基于 JSON 结果集规则的预期属性。
该示例适用于以下架构和示例数据:
create table test_simplified_json (a float); insert into test_simplified_json values(10.0);
public void JSON_result_set_demo() { var sql = "select * from test_simplified_json"; var request = new ExecuteStatementRequest() .withDatabase(databaseName) .withSecretArn(secretStoreArn) .withResourceArn(clusterArn) .withSql(sql) .withFormatRecordsAs(RecordsFormatType.JSON); var result = rdsdataClient.executeStatement(request); }
之前程序中的 formattedRecords 字段的值为:
[{"a":10.0}]
由于存在 JSON 结果集,响应中的 Records 和 ColumnMetadata 字段均为 null。
以下 Java 示例演示了一个在结果集中返回整数数值的查询。该示例调用 getFormattedRecords 以仅返回 JSON 格式的字符串,并忽略其他空白或为 null 的响应字段。该示例将结果反序列化为一个表示记录列表的结构。每条记录都有一些字段,字段名称对应于结果集中的列别名。此技术简化了解析结果集的代码。您的应用程序不必循环浏览结果集的行和列并将每个值转换为适当类型。
该示例适用于以下架构和示例数据:
create table test_simplified_json (a int); insert into test_simplified_json values(17);
public void JSON_deserialization_demo() { var sql = "select * from test_simplified_json"; var request = new ExecuteStatementRequest() .withDatabase(databaseName) .withSecretArn(secretStoreArn) .withResourceArn(clusterArn) .withSql(sql) .withFormatRecordsAs(RecordsFormatType.JSON); var result = rdsdataClient.executeStatement(request) .getFormattedRecords(); /* Turn the result set into a Java object, a list of records. Each record has a field 'a' corresponding to the column labelled 'a' in the result set. */ private static class Record { public int a; } var recordsList = new ObjectMapper().readValue( response, new TypeReference<List<Record>>() { }); }
之前程序中的 formattedRecords 字段的值为:
[{"a":17}]
要检索结果行 0 的 a 列,应用程序将引用 recordsList.get(0).a。
相比之下,以下 Java 示例显示了在不使用 JSON 格式的情况下,构建保存结果集的数据结构所需的代码类型。在这种情况下,结果集的每一行都包含一些字段,其中包含有关单个用户的信息。构建表示结果集的数据结构需要循环浏览这些行。对于每一行,代码会检索每个字段的值,执行适当的类型转换,并将结果分配给表示该行的对象中的相应字段。然后,代码将表示每个用户的对象添加到表示整个结果集的数据结构中。如果将查询更改为重新排序、添加或删除结果集中的字段,则也必须更改应用程序代码。
/* Verbose result-parsing code that doesn't use the JSON result set format */ for (var row: response.getRecords()) { var user = User.builder() .userId(row.get(0).getLongValue()) .firstName(row.get(1).getStringValue()) .lastName(row.get(2).getStringValue()) .dob(Instant.parse(row.get(3).getStringValue())) .build(); result.add(user); }
以下示例值显示了具有不同列数、列别名和列数据类型的结果集的 formattedRecords 字段的值。
如果结果集包含多行,则每一行都表示为一个作为数组元素的对象。结果集中的每一列都成为对象中的一个键。这些键在结果集中的每一行都会重复出现。因此,对于包含许多行和列的结果集,您可能需要定义短列别名,以避免超出整个响应的长度限制。
该示例适用于以下架构和示例数据:
create table sample_names (id int, name varchar(128)); insert into sample_names values (0, "Jane"), (1, "Mohan"), (2, "Maria"), (3, "Bruce"), (4, "Jasmine");
[{"id":0,"name":"Jane"},{"id":1,"name":"Mohan"}, {"id":2,"name":"Maria"},{"id":3,"name":"Bruce"},{"id":4,"name":"Jasmine"}]
如果结果集中的某一列被定义为表达式,则该表达式的文本将成为 JSON 键。因此,为查询的选择列表中的每个表达式定义一个描述性列别名通常很方便。例如,以下查询在其选择列表中包含诸如函数调用和算术运算之类的表达式。
select count(*), max(id), 4+7 from sample_names;
这些表达式将作为键传递到 JSON 结果集。
[{"count(*)":5,"max(id)":4,"4+7":11}]
添加带有描述性标签的 AS 列可以简化 JSON 结果集中键的解释。
select count(*) as rows, max(id) as largest_id, 4+7 as addition_result from sample_names;
在修订后的 SQL 查询中,使用由 AS 子句定义的列标签作为键名。
[{"rows":5,"largest_id":4,"addition_result":11}]
JSON 字符串中每个键值对的值可以是带引号的字符串。该字符串可能包含 Unicode 字符。如果该字符串包含转义序列或者 " 或 \ 字符,则这些字符前面必须有反斜杠转义字符。以下 JSON 字符串示例演示了这些可能性。例如,string_with_escape_sequences 结果包含特殊字符:退格符、换行符、回车符、制表符、换页符和 \。
[{"quoted_string":"hello"}] [{"unicode_string":"邓不利多"}] [{"string_with_escape_sequences":"\b \n \r \t \f \\ '"}]
JSON 字符串中每个键值对的值也可以表示一个数字。该数字可能是整数、浮点值、负值或以指数表示法表示的值。以下 JSON 字符串示例演示了这些可能性。
[{"integer_value":17}] [{"float_value":10.0}] [{"negative_value":-9223372036854775808,"positive_value":9223372036854775807}] [{"very_small_floating_point_value":4.9E-324,"very_large_floating_point_value":1.7976931348623157E308}]
布尔值和 null 值用不带引号的特殊关键字 true、false 和 null 表示。以下 JSON 字符串示例演示了这些可能性。
[{"boolean_value_1":true,"boolean_value_2":false}] [{"unknown_value":null}]
如果选择 BLOB 类型的值,则结果将在 JSON 字符串中表示为 base64 编码值。要将值转换回原始表示形式,可以使用应用程序语言中的相应解码函数。例如,在 Java 中调用函数 Base64.getDecoder().decode()。以下示例输出显示了选择 hello world 的 BLOB 值并将结果集作为 JSON 字符串返回的结果。
[{"blob_column":"aGVsbG8gd29ybGQ="}]
以下 Python 示例展示了如何访问调用 Python execute_statement 函数的结果中的值。结果集是字段 response['formattedRecords'] 中的字符串值。该代码通过调用 json.loads 函数,将 JSON 字符串转换为数据结构。然后,结果集的每一行都是数据结构中的一个列表元素,在每一行中,您可以按名称引用结果集的每个字段。
import json result = json.loads(response['formattedRecords']) print (result[0]["id"])
以下 JavaScript 示例展示了如何访问调用 JavaScript executeStatement 函数的结果中的值。结果集是字段 response.formattedRecords 中的字符串值。该代码通过调用 JSON.parse 函数,将 JSON 字符串转换为数据结构。然后,结果集的每一行都是数据结构中的一个数组元素,在每一行中,您可以按名称引用结果集的每个字段。
<script> const result = JSON.parse(response.formattedRecords); document.getElementById("display").innerHTML = result[0].id; </script>
排查 RDS 数据 API 问题
使用以下部分(标题为常见错误消息)帮助解决 RDS 数据 API(数据 API)问题。
未找到事务 <transaction_ID>
在此情况下,找不到 Data API 调用中指定的事务 ID。错误消息提供了导致此问题的原因,是以下原因之一:
-
事务可能已过期。确保每个事务调用在上一个事务调用之后的 3 分钟内运行。
也可能是指定的事务 ID 不是由 BeginTransaction 调用创建的。确保您的调用具有有效的事务 ID。
-
之前的一次调用导致您的事务终止。交易已经由您的
CommitTransaction或者RollbackTransaction调用。 -
由于之前的调用发生错误,事务已中止。检查您之前的电话是否引发了任何异常。
有关运行事务的信息,请参阅调用 RDS 数据 API。
用于查询的包太大
在此情况下,为行返回的结果集太大。数据库返回的结果集中的 Data API 大小限制为每行 64 KB。
要解决此问题,请确保结果集中的每一行都小于或等于 64 KB。
数据库响应超出大小限制
在此情况下,数据库返回的结果集太大。数据库返回的结果集中的 Data API 限制为 1MiB。
要解决此问题,请确保对数据 API 的调用返回 1MiB 或更少数据。如果需要返回 1MiB 以上的数据,您可以在查询中将多个 ExecuteStatement 调用与 LIMIT 子句结合使用。
有关 LIMIT 子句的更多信息,请参阅 MySQL 文档中的 SELECT 语法
没有为集群 <cluster_ID> 启用 HttpEndpoint
请查看以下可能导致该问题的原因:
-
Aurora 数据库集群不支持数据 API。例如,对于 Aurora MySQL,您只能将数据 API 与 Aurora Serverless v1 一起使用。有关 RDS 数据 API 支持的数据库集群类型的信息,请参阅区域和版本可用性。
-
未为 Aurora 数据库集群启用数据 API。要将数据 API 与 Aurora 数据库集群结合使用,必须为该数据库集群启用数据 API。有关启用数据 API 的信息,请参阅启用 RDS 数据 API。
-
在为数据库集群启用数据 API 之后,已重命名该数据库集群。在这种情况下,请关闭该集群的数据 API,然后再次启用它。
-
您指定的 ARN 与集群的 ARN 不完全匹配。请检查从另一个源返回的 ARN 或由程序逻辑构造的 ARN 是否与集群的 ARN 完全匹配。例如,请确保您使用的 ARN 的所有字母字符的大小写正确。