分区和数据分布
Amazon DynamoDB 将数据存储在分区。分区是为表格分配的存储,由固态硬盘 (SSD) 提供支持,并可在 Amazon 区域内的多个可用区中自动进行复制。分区管理由 DynamoDB 全权负责,您从不需要亲自管理分区。
在您创建表时,表的初始状态为 CREATING。在此期间,DynamoDB 会向表分配足够的分区,以便满足预置吞吐量需求。表的状态变为 ACTIVE 后,您可开始读取和写入表数据。
在以下情况下,DynamoDB 会向表分配额外的分区:
-
您增加的表的预置吞吐量设置超出了现有分区的支持能力。
-
现有分区填充已达到容量上限,并且需要更多的存储空间。
分区管理在后台自动进行,对程序是透明的。您的表将保留可用吞吐量并完全支持预置吞吐量需求。
有关更多详细信息,请参阅分区键设计。
DynamoDB 中的全局二级索引还包含分区。全局二级索引中的数据将与其基表中的数据分开存储,但索引分区与表分区的行为方式几乎相同。
数据分布:分区键
如果表具有简单主键(只有分区键),DynamoDB 将根据其分区键值存储和检索各个项目。
DynamoDB 使用分区键的值作为内部散列函数的输入值,从而将项目写入表中。散列函数的输出值决定了项目将要存储在哪个分区。
要从表读取项目,必须指定项目的分区键值。DynamoDB 使用此值作为其哈希函数的输入值,得到可从中找到该项目的分区。
下图显示了名为 Pets 的表,该表跨多个分区。表的主键是 AnimalType(仅显示此关键属性)。DynamoDB 使用其哈希函数决定新项目的存储位置,在这种情况下,会根据字符串 Dog 的哈希值。请注意,项目并非按排序顺序存储的。每个项目的位置由其分区键的哈希值决定。
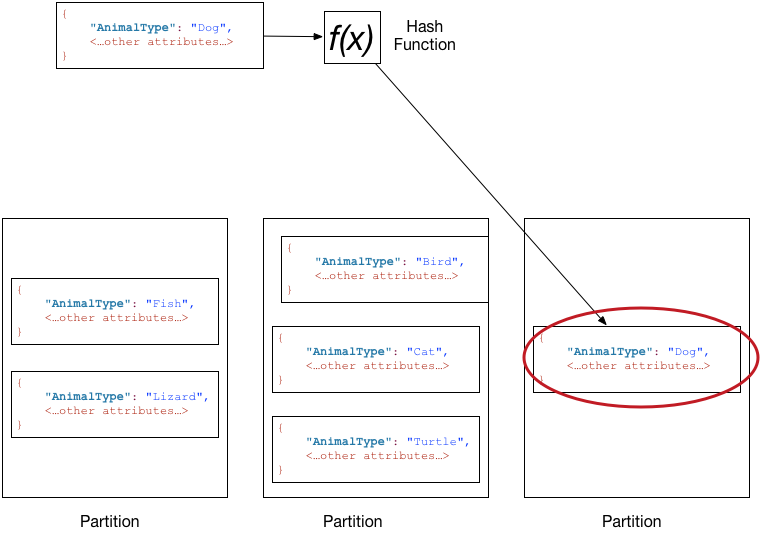
注意
DynamoDB 经过优化,不论表有多少个分区,都可在这些分区上统一分配项目。我们建议您选择具有较多非重复值(相对于表中的项目数)的分区键。
数据分布:分区键和排序键
如果表具有复合主键(分区键和排序键),DynamoDB 将采用与 数据分布:分区键 中所述的方式相同的方式来计算分区键的哈希值。但是,它倾向于将具有相同分区键值的项目保留在一起,并按排序键属性的值排序。具有相同分区键值的一组项目称为项目集。对项目集进行了优化,可以有效地检索项目集中的项目范围。如果您的表没有本地二级索引,DynamoDB 将根据需要自动将您的项目集拆分到任意数量的分区中,以存储数据并提供读取和写入吞吐量。
为将某个项目写入表中,DynamoDB 会计算分区键的散列值以确定该项目的存储分区。在该分区中,可能有几个具有相同分区键值的项目。因此,DynamoDB 会按排序键的升序将该项目存储在具有相同分区键的其他项目中。
要从表中读取项目,必须指定分区键值和排序键值。DynamoDB 计算分区键的哈希值,得出可从中找到该项目的分区。
如果您想要的项目具有相同的分区键值,则可以通过单一操作 (Query) 读取表中的多个项目。DynamoDB 返回具有该分区键值的所有项目。或者,您也可以对排序键应用某个条件,以便它仅返回特定值范围内的项目。
假设 Pets 表具有由 AnimalType(分区键)和 Name(排序键)构成的复合主键。下图显示了 DynamoDB 写入项目的过程,分区键值为 Dog、排序键值为 Fido。
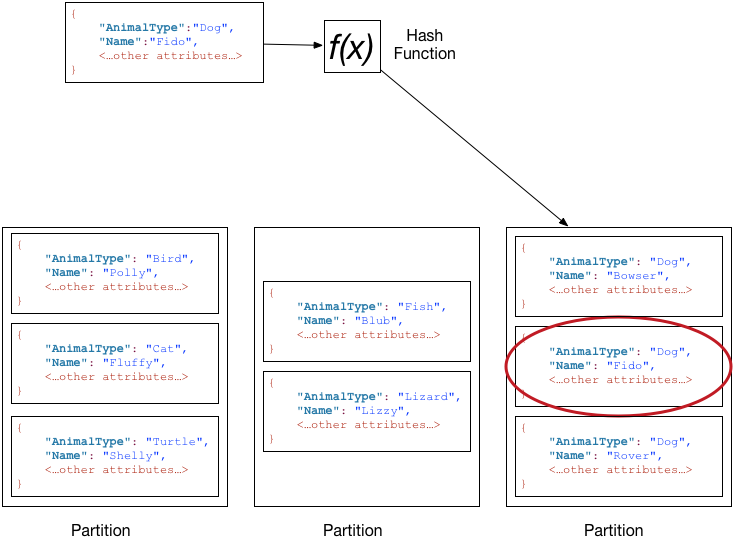
为读取 Pets 表中的同一项目,DynamoDB 会计算 Dog 的哈希值,从而生成这些项目的存储分区。然后,DynamoDB 扫描排序键属性值,直到找到 Fido。
要读取 AnimalType 为 Dog 的所有项目,您可以执行 Query 操作,无需指定排序键条件。默认情况下,这些项目会按存储顺序 (即按排序键的升序) 返回。或者,您也可以请求以降序返回。
若要仅查询某些 Dog 项目,您可以对排序键应用某个条件(例如,仅使用 Name 以 A 到 K 范围的字母开始的 Dog 项目。
注意
在 DynamoDB 表中,每个分区键值的非重复排序键值无数量上限。如果要在 Pets 表中存储数十亿 Dog 项目,DynamoDB 会分配足够的存储空间来自动处理此要求。