使用 Amazon X-Ray 可视化 Lambda 函数调用
您可以使用 Amazon X-Ray 来可视化应用程序的组件、确定性能瓶颈以及对导致错误的请求进行故障排除。您的 Lambda 函数会将跟踪数据发送到 X-Ray,X-Ray 将处理这些数据以生成服务地图和可搜索的跟踪摘要。
Lambda 支持两种 X-Ray 跟踪模式:Active 和 PassThrough。使用 Active 跟踪,Lambda 会自动为函数调用创建跟踪段,并将其发送到 X-Ray。另一方面,PassThrough 模式只会将跟踪上下文传播到下游服务。如果已为函数启用 Active 跟踪,则 Lambda 会自动将采样请求的跟踪发送到 X-Ray。通常,上游服务(例如 Amazon API Gateway 或托管在 Amazon EC2 上并使用 X-Ray SDK 进行检测的应用程序)会决定是否应跟踪传入请求,然后将该采样决策添加为跟踪标头。Lambda 使用该标头来决定是否发送跟踪。上游消息创建者(例如 Amazon SQS)的跟踪会自动链接到下游 Lambda 函数的跟踪,从而创建整个应用程序的端到端视图。有关更多信息,请参阅《Amazon X-Ray 开发人员指南》中的 Tracing event-driven applications(跟踪事件驱动型应用程序)。
注意
目前,使用 Amazon Managed Streaming for Apache Kafka(Amazon MSK)、自行管理的 Apache Kafka、具有 ActiveMQ 及 RabbitMQ 或 Amazon DocumentDB 事件源映射的 Amazon MQ 的 Lambda 函数,不支持 X-Ray 跟踪。
要使用控制台切换 Lambda 函数的活动跟踪,请按照以下步骤操作:
打开活跃跟踪
打开 Lamba 控制台的 Functions
(函数)页面。 -
选择函数。
选择 Configuration(配置),然后选择 Monitoring and operations tools(监控和操作工具)。
在其他监控工具下,选择编辑。
-
在 CloudWatch 应用程序信号和 Amazon X-Ray 下,为 Lambda 服务跟踪选择启用。
-
选择保存。
您的函数需要权限才能将跟踪数据上载到 X-Ray。在 Lambda 控制台中激活跟踪后,Lambda 会将所需权限添加到函数的执行角色。如果没有,请将 AWSXRayDaemonWriteAccess
X-Ray 无法跟踪对应用程序的所有请求。X-Ray 将应用采样算法确保跟踪有效,同时仍会提供所有请求的一个代表性样本。采样率是每秒 1 个请求和 5% 的其他请求。您无法为函数配置此 X-Ray 采样率。
了解 X-Ray 跟踪
在 X-Ray 中,跟踪记录有关由一个或多个服务处理的请求的信息。Lambda 会每个跟踪记录 2 个分段,这些分段将在服务图上创建两个节点。下图突出显示了这两个节点:
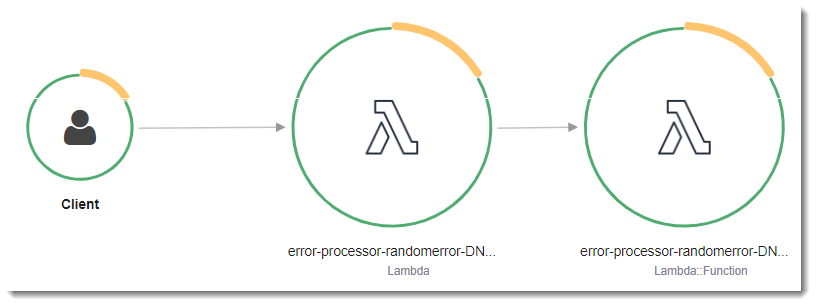
位于左侧的第一个节点表示接收调用请求的 Lambda 服务。第二个节点表示特定的 Lambda 函数。
针对 Lambda 服务记录的分段 AWS::Lambda 涵盖了准备 Lambda 执行环境所需的所有步骤。这包括调度 MicroVM、使用已配置的资源创建或解冻执行环境、下载函数代码和所有层。
AWS::Lambda::Function 分段表示函数完成的工作。
注意
Amazon 目前正在实施对 Lambda 服务的更改。由于这些更改,您可能会看到 Amazon Web Services 账户 中不同 Lambda 函数发出的系统日志消息和跟踪分段的结构和内容之间存在细微差异。
此更改会影响函数段的子分段。以下段落介绍了这些子分段的新旧格式。
这些更改将在未来几周内实施,除中国和 GovCloud 区域外,所有 Amazon Web Services 区域 的函数都将过渡到使用新格式的日志消息和跟踪分段。
旧式 Amazon X-Ray Lambda 分段结构
AWS::Lambda 分段的旧式 X-Ray 结构如下所示:

在此格式中,函数分段包含 Initialization、Invocation 和 Overhead 的子分段。(仅限 Lambda SnapStart)还有一个 Restore 子分段(此示意图中未显示)。
该 Initialization 子分段表示 Lambda 执行环境生命周期的初始化阶段。在此阶段,Lambda 将初始化扩展、初始化运行时并运行函数的初始化代码。
Invocation 子段表示 Lambda 调用函数处理程序的调用阶段。这从运行时和扩展注册开始,在运行时准备好发送响应时结束。
(仅限 Lambda SnapStart)Restore 子分段会显示 Lambda 还原快照、加载运行时,以及运行任何还原后运行时挂钩所花费的时间。恢复快照的过程可能包含在 MicroVM 之外的活动上花费的时间。该时间在 Restore 子分段中报告。您无需为在 microVM 之外还原快照所花费的时间付费。
Overhead 子段表示在运行时发送响应和下次调用信号之间出现的阶段。在此期间,运行时会完成与调用相关的所有任务,并准备冻结沙盒。
重要
您可以使用 X-Ray SDK 扩展 Invocation 子分段以及进行下游调用、注释和元数据的额外子分段。您无法直接访问函数分段,也无法记录在处理程序调用范围之外完成的工作。
有关 Lambda 执行环境阶段的更多信息,请参阅 了解 Lambda 执行环境生命周期。
该示意图显示了使用旧式 X-Ray 结构的示例跟踪。

注意示例中的两个分段。两者都命名为 my-function,但其中一个函数具有 AWS::Lambda 源,另一个则具有 AWS::Lambda::Function 源。如果 AWS::Lambda 分段显示错误,则表示 Lambda 服务存在问题。如果 AWS::Lambda::Function 分段显示错误,则说明函数存在问题。
注意
新式 Amazon X-Ray Lambda 分段结构
AWS::Lambda 分段的新式 X-Ray 结构如下所示:

在此新格式中,Init 子分段像以前一样表示 Lambda 执行环境生命周期的初始化阶段。
新格式中没有调用分段。而是将客户子分段直接附加到 AWS::Lambda::Function 分段 此分段包含以下指标作为注释:
-
aws.responseLatency:函数运行所用的时间 -
aws.responseDuration:将响应传递给客户所用的时间 -
aws.runtimeOverhead:运行时完成所需的额外时间 -
aws.extensionOverhead:扩展完成所需的额外时间
该示意图显示了使用新式 X-Ray 结构的示例跟踪。

注意示例中的两个分段。两者都命名为 my-function,但其中一个函数具有 AWS::Lambda 源,另一个则具有 AWS::Lambda::Function 源。如果 AWS::Lambda 分段显示错误,则表示 Lambda 服务存在问题。如果 AWS::Lambda::Function 分段显示错误,则说明函数存在问题。
有关 Lambda 中特定于语言的跟踪简介,请参阅以下主题:
有关支持活动检测的服务的完整列表,请参阅《Amazon X-Ray 开发人员指南》中的受支持的 Amazon Web Services 服务。
Lambda 中的默认跟踪行为
如果未开启 Active 跟踪,Lambda 会默认为 PassThrough 跟踪模式。
在 PassThrough 模式下,Lambda 将 X-Ray 跟踪标头转发到下游服务,但不会自动发送跟踪。即使跟踪标头包含对请求进行采样的决定,情况也是如此。如果上游服务未提供 X-Ray 跟踪标头,则 Lambda 会生成一个标头并决定不进行采样。但是,您可以通过从函数代码中调用跟踪库来发送您自己的跟踪。
注意
以前,当上游服务(例如 Amazon API Gateway)添加跟踪标头时,Lambda 会自动发送跟踪。通过不自动发送跟踪,Lambda 让您可以控制跟踪对您来说重要的函数。如果解决方案依赖于此被动跟踪行为,请切换到 Active 跟踪。
执行角色权限
Lambda 需要以下权限才能将跟踪数据发送到 X-Ray。将这些权限添加到您的函数的执行角色中。
这些权限包含在 AWSXRayDaemonWriteAccess
使用 Lambda API 启用 Active 跟踪
要使用 Amazon CLI 或 Amazon 开发工具包管理跟踪配置,请使用以下 API 操作:
以下示例 Amazon CLI 命令对名为 my-function 的函数启用活跃跟踪。
aws lambda update-function-configuration --function-name my-function \ --tracing-config Mode=Active
跟踪模式是发布函数版本时版本特定配置的一部分。您无法更改已发布版本上的跟踪模式。
使用 Amazon CloudFormation 启用 Active 跟踪
要对 Amazon CloudFormation 模板中的 AWS::Lambda::Function 资源激活跟踪,请使用 TracingConfig 属性。
例 function-inline.yml
Resources: function: Type: AWS::Lambda::Function Properties:TracingConfig: Mode: Active...
对于 Amazon Serverless Application Model (Amazon SAM) AWS::Serverless::Function 资源,请使用 Tracing 属性。
例 template.yml
Resources: function: Type: AWS::Serverless::Function Properties:Tracing: Active...