本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
使用 Amazon A SageMaker I 进行机器学习概述
本节介绍典型的机器学习 (ML) 工作流程,并介绍如何使用 Amazon A SageMaker I 完成这些任务。
在机器学习中,您指导计算机进行预测或推理。首先,您使用一种算法和示例数据来训练模型。然后,您将模型集成到应用程序中,以实时且大规模地生成推理。
下图显示了创建 ML 模型的典型工作流程。它包括循环流中的三个阶段,我们将在下图中详细介绍:
-
生成示例数据
-
训练模型
-
部署模型
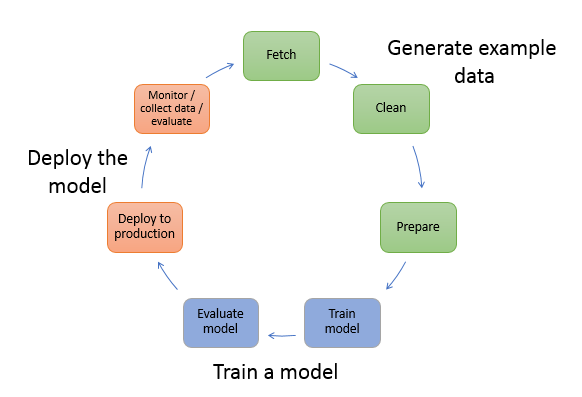
下图显示了如何在大多数典型场景中执行以下任务:
-
生成示例数据:要训练模型,您需要示例数据。所需数据的类型取决于您希望模型解决的业务问题。这与您希望模型生成的推理有关。例如,如果您要创建一个模型从输入的手写数字映像中预测一个数字。要训练此类模型,您需要手写体数字的示例映像。
数据科学家在使用示例数据进行模型训练之前,通常会花时间探索和预处理这些数据。要对数据进行预处理,您通常执行以下操作:
-
获取数据:您可能拥有内部示例数据存储库,或者您可能使用公开可用的数据集。通常,您将一个或多个数据集提取到单个存储库中。
-
清理数据:要改进模型训练,请检查数据并根据需要进行清理。例如,如果您的数据具有值为
United States和US的country name属性,您可以编辑数据以保持一致。 -
准备或转换数据:要提高性能,您可以执行额外的数据转换。例如,您可能会为一个预测飞机除冰条件的模型选择组合属性。您可以将温度和湿度属性合并为一种新的属性以获得更好的模型,而不是单独使用这些属性。
在 SageMaker AI 中,你可以在集成开发环境 (IDE) 中使用 SageMaker Python SDK
使用 SageMaker API 对示例数据进行预处理。使用 Python 的 SDK (Boto3),您可以获取、浏览和准备用于模型训练的数据。有关数据准备、处理和转换数据的信息,请参阅 在 SageMaker AI 中选择正确的数据准备工具的建议、带 SageMaker 处理功能的数据转换工作负载、和 使用特征存放区创建、存储和共享功能。 -
-
训练模型:模型训练包括训练和评测模型,如下所示:
-
训练模型:要训练模型,您需要一种算法或预训练的基本模型。您选择的算法取决于许多因素。对于内置解决方案,您可以使用 SageMaker 提供的算法之一。有关提供的算法列表 SageMaker 和相关注意事项,请参阅Built-in Amazon 中的算法和预训练模型 SageMaker。有关提供算法和模型的 UI-based 训练解决方案,请参阅SageMaker JumpStart 预训练模型。
您还需要适用于训练的计算资源。您的资源使用情况取决于训练数据集的大小和需要结果的速度。您可以使用从单个通用实例到分布式 GPU 实例集群等各种资源。有关更多信息,请参阅 使用 Amazon 训练模型 SageMaker。
-
评测模型:训练模型之后,您对其进行评测,以确定推理的准确性是否可接受。要训练和评估您的模型,请使用 SageMaker Python SDK
通过其中一个可用的 IDE 向模型发送推断请求。有关评测模型的更多信息,请参阅 使用 Amazon 模型监视器监控数据和 SageMaker 模型质量。
-
-
部署模型:通常,您会对模型进行一些重新设计,以将其与应用程序集成并部署。借 SageMaker 助 AI 托管服务,您可以独立部署模型,从而将其与应用程序代码分离。有关更多信息,请参阅 部署模型用于推理。
机器学习是连续的周期。部署模型后,您监控推理,收集更多高质量的数据并评测模型以识别偏差。然后,您可以更新训练数据以包含新收集的高质量的数据,从而提高推理准确性。随着更多的示例数据变得可用,您继续重新训练模型以提高准确性。