本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
Amazon SQS 中 FIFO 队列的高吞吐量
Amazon SQS 中的高吞吐量 FIFO 队列可以有效地管理高消息吞吐量,同时保持严格的消息顺序,从而确保处理大量消息的应用程序的可靠性和可扩展性。该解决方案非常适合要求高吞吐量和有序消息传递的场景。
在严格的消息排序并不重要、传入消息量相对较低或偶尔发生的情况下,不需要使用 Amazon SQS 高吞吐量 FIFO 队列。例如,如果您有一个处理到达频率低或不需要按顺序处理的消息的小型应用程序,那么使用高吞吐量 FIFO 队列所产生的复杂性和成本不会带来足够的好处。此外,如果您的应用程序不需要高吞吐量 FIFO 队列提供的增强吞吐能力,那么选择标准 Amazon SQS 队列可能更具成本效益,并且更易于管理。
为了提高高吞吐量 FIFO 队列中的请求容量,建议增加消息组的数量。有关高吞吐量消息配额的更多信息,请参阅《Amazon Web Services 一般参考》中的 Amazon SQS 服务限额。
有关每个队列的配额和数据分配策略的信息,请参阅Amazon SQS 消息配额和SQS FIFO 队列高吞吐量的分区和数据分布。
Amazon SQS FIFO 队列的高吞吐量使用案例
以下应用场景重点介绍了高吞吐量 FIFO 队列的不同应用,展示了它们在各行业和场景中的有效性:
-
实时数据处理:处理实时数据流(例如事件处理或遥测数据摄取)的应用程序可以利用高吞吐量 FIFO 队列来处理不断涌入的消息,并在保证消息顺序的同时,进行准确分析。
-
电子商务订单处理:在电子商务平台中,保持客户交易顺序至关重要,高吞吐量 FIFO 队列可以确保订单按顺序处理并且不会出现延迟,即使在购物高峰期也是如此。
-
金融服务:金融机构在处理高频交易或交易数据时,依靠高吞吐量 FIFO 队列以最小的延迟处理市场数据和交易,同时遵守严格的消息顺序监管要求。
-
媒体流式传输:流媒体平台和媒体分发服务利用高吞吐量 FIFO 队列来管理媒体文件和流媒体内容的分发,确保用户获得流畅的播放体验,同时保持正确的内容分发顺序。
SQS FIFO 队列高吞吐量的分区和数据分布
Amazon SQS 以分区形式存储 FIFO 队列数据。分区是为队列分配的存储空间,该队列在一个 Amazon 区域内的多个可用区之间自动复制。您无需管理分区。相反,Amazon SQS 会负责分区管理。
对于 FIFO 队列,在以下情况下,Amazon SQS 会修改队列中的分区数量:
-
如果当前请求速率接近或超过现有分区所能支持的速率,则会分配其他分区,直到队列达到区域配额。有关配额的信息,请参阅Amazon SQS 消息配额。
-
如果当前分区的利用率较低,则分区的数量可能会减少。
分区管理在后台自动进行,对程序是透明的。您的队列和消息始终可用。
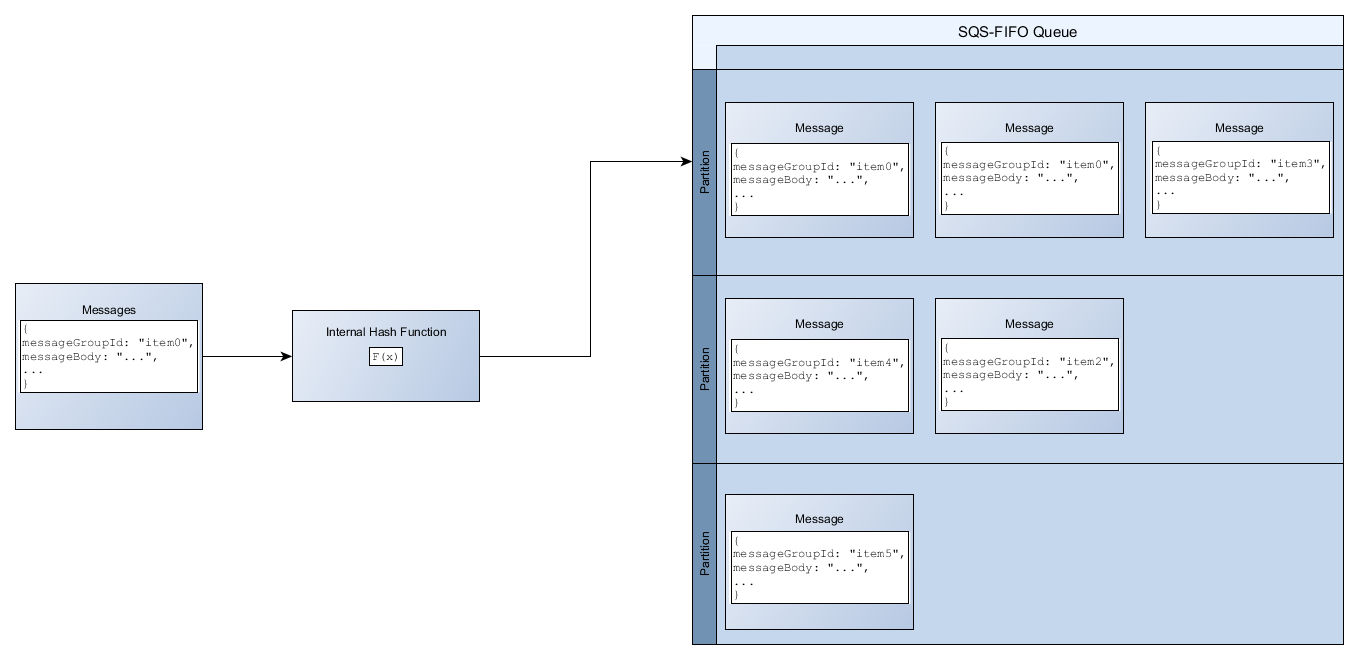
按消息组分发数据 IDs
为了将消息添加到 FIFO 队列,Amazon SQS 使用每条消息的消息组 ID 的值作为内部哈希函数的输入。散列函数的输出值决定了哪个分区会存储消息。
下图显示了跨越多个分区的队列。队列的消息组 ID 基于项编号。Amazon SQS 使用其哈希函数决定新项的存储位置;在本例中,它基于字符串 item0 的哈希值。请注意,这些项的存储顺序与它们添加到队列的顺序相同。每个项的位置由其消息组 ID 的哈希值决定。
注意
Amazon SQS 经过优化,可以在 FIFO 队列的分区中均匀分配项目,无论分区数量如何。 Amazon 建议您使用可 IDs 包含大量不同值的消息组。
优化分区利用率
在支持区域,每个分区支持每秒最多 3000 条消息进行批处理,或者支持每秒最多 300 条消息用于发送、接收和删除操作。有关高吞吐量消息配额的更多信息,请参阅《Amazon Web Services 一般参考》中的 Amazon SQS 服务限额。
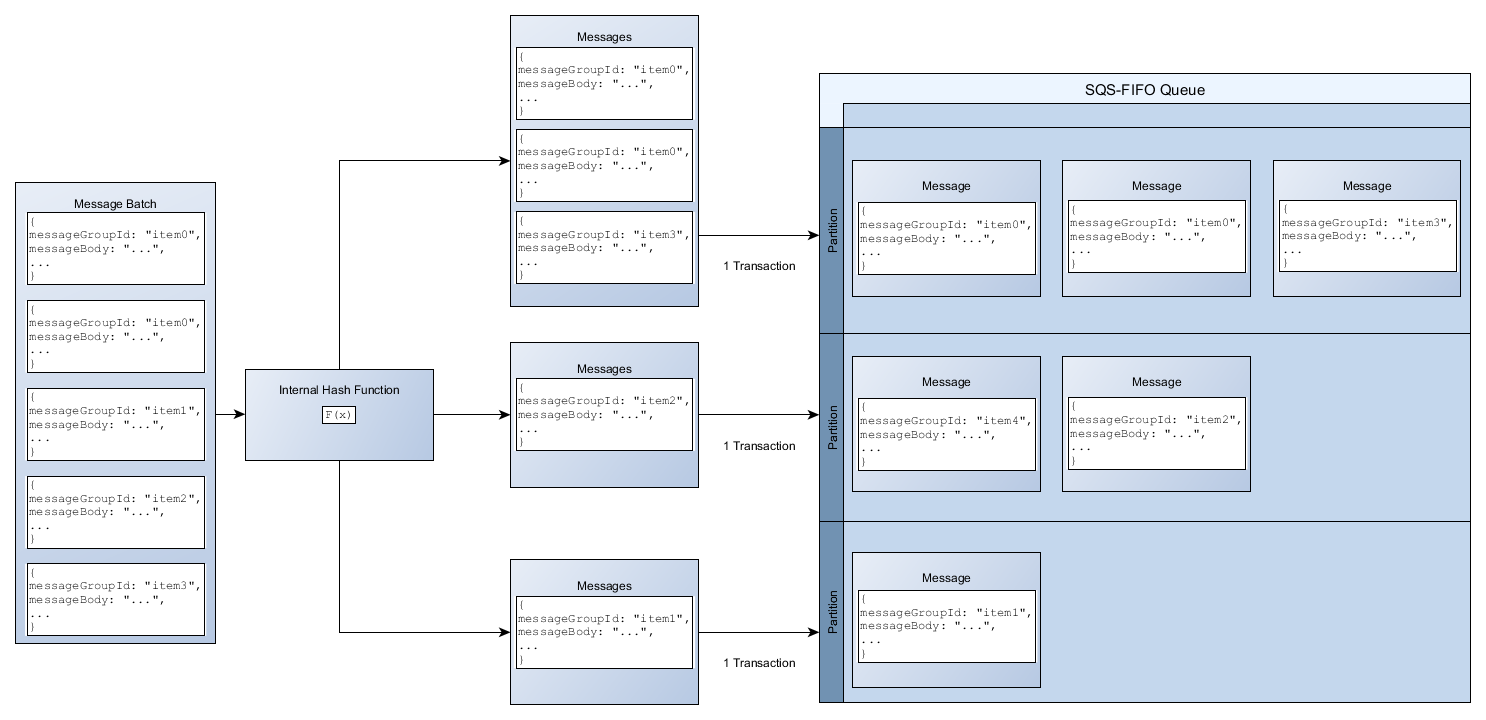
使用批处理时 APIs,每条消息都将根据中所按消息组分发数据 IDs述的过程进行路由。路由到同一分区的消息在单个事务中进行分组和处理。
为了优化 SendMessageBatch API 的分区利用率, Amazon 建议尽可能使用相同的消息组 IDs 对消息进行批处理。
要优化DeleteMessageBatch和的分区利用率 ChangeMessageVisibilityBatch APIs, Amazon 建议使用MaxNumberOfMessages参数设置为 10 的ReceiveMessage请求,并对单个请求返回的接收句柄进行批处理。ReceiveMessage
在以下示例中,发送了一批包含不同消息组 IDs 的消息。该批次分为三组,每组都计入分区的配额。
注意
Amazon SQS 仅保证将具有相同消息组 ID 的内部哈希函数的消息分组到批处理请求中。根据内部哈希函数的输出和分区数量, IDs 可能会对具有不同消息组的消息进行分组。由于哈希函数或分区数量可以随时更改,因此,在某一时刻分组的消息以后可能无法分组。