服务级别目标(SLO)
您可以使用 Application Signals 为关键业务操作或依赖项的服务创建服务级别目标。创建这些服务的 SLO 后,您即可在 SLO 控制面板上对其进行跟踪,一目了然地了解自己最重要的运营。
除了创建快速视图供运营商查看关键运营的当前状态,您还可以使用 SLO 跟踪服务的长期性能,从而确保其符合您的预期。如果您与客户签订了服务级别协议,SLO 则是确保符合这些协议的绝佳工具。
使用 SLO 评估服务的运行状况,首先要根据关键性能指标(服务级别指标(SLI)))设定清晰且可衡量的目标。SLO 会根据您设置的阈值和目标跟踪 SLI 性能,并报告您的应用程序性能与阈值的差异。
Application Signals 帮助您设置关键性能指标的 SLO。Application Signals 自动收集其发现的各项服务和操作的 Latency 和 Availability 指标,这些指标通常很适合用作 SLI。您可以通过 SLO 创建向导将这些指标用于 SLO。然后,您可以使用 Application Signals 控制面板跟踪所有 SLO 的状态。
您可以为您的服务调用或使用的特定操作或依赖项设置 SLO。除了使用 Latency 和 Availability 指标外,您还可以将任何 CloudWatch 指标或指标表达式用作 SLI。
创建 SLO 对于充分利用 CloudWatch Application Signals 至关重要。创建 SLO 后,您可以在 Application Signals 控制台中查看其状态,以快速查看哪些关键服务和操作运行正常或不正常。由 SLO 进行跟踪的主要好处如下:
您的服务运营商可以更轻松地查看根据 SLI 衡量的关键服务的当前运行状况。然后即可快速对运行不正常的服务和操作进行分类和识别。
您可以根据可衡量的业务目标,长期跟踪您的服务性能。
通过选择要设置 SLO 的对象,您可以确定重要内容的优先级。Application Signals 控制面板会自动显示有关您已确定优先级的信息。
在创建 SLO 时,您还可以选择通过同时创建 CloudWatch 警报来监控 SLO。您可以通过设置警报监控超出阈值的情况,也可以设置监控警告级别的警报。如果 SLO 指标超出所设阈值或接近警告阈值,这些警报可以自动通知您。例如,如果 SLO 接近警告阈值,您便可以得知,您的团队可能需要减慢应用程序的流失速度,以确保实现长期性能目标。
主题
SLO 概念
SLO 包括以下组件:
服务级别指标(SLI),即您指定的关键性能指标。代表了您的应用程序所需的性能水平。Application Signals 会自动收集其发现的各项服务和操作的关键指标
Latency和Availability,这些指标通常很适合用作 SLI。您可以选择用于 SLI 的阈值。例如,延迟时间为 200 毫秒。
目标或达标率目标,即预计 SLI 在各个时间间隔内达到阈值的时间或请求的百分比。时间间隔可以短至几小时,也可以长达一年。
间隔可以是日历间隔,也可以是滚动间隔。
日历间隔与日历一致,例如每月跟踪的 SLO。CloudWatch 会根据一个月的天数自动调整运行状况、预算和达标数量。日历间隔更适合用于按照日历进行衡量的业务目标。
滚动间隔采用滚动计算。滚动间隔更适合用于跟踪应用程序的近期用户体验。
周期是较短的时间长度,许多周期构成一个间隔。将应用程序在间隔内各个周期的性能与 SLI 进行比较。在各个周期确定应用程序已达到或未达到必要的性能水平。
例如,日历间隔为一天、周期为 1 分钟的 99% 目标,意味着应用程序必须在当日的所有 1 分钟周期中,有 99% 的周期达到或实现成功阈值。这样才能实现当日的 SLO。次日即为新的评估间隔,应用程序必须在次日有 99% 的 1 分钟周期达到或实现成功阈值才能实现次日的 SLO。
SLI 可以基于 Application Signals 收集的其中一项新标准应用程序指标。或者可以使用任何 CloudWatch 指标或指标表达式。可用于 SLI 的标准应用程序指标为 Latency 和 Availability。Availability 表示成功响应除以请求总数的结果。计算方法为 (1 - 故障率)*100,其中故障响应为 5xx 错误。成功响应表示没有 5XX 错误的响应。4XX 响应视为成功响应。
除了针对服务的单个操作或所有操作创建 SLO 之外,还可以创建用于监控服务操作子集的复合 SLO。复合 SLO 可聚合多个操作的 Availability 指标,让您可以统一了解一组相关操作的可靠性。可以选择 2 至 20 个操作以包含在复合 SLO 中。有关更多信息,请参阅 针对多个操作创建复合 SLO。
计算基于周期的 SLO 的错误预算和达标率
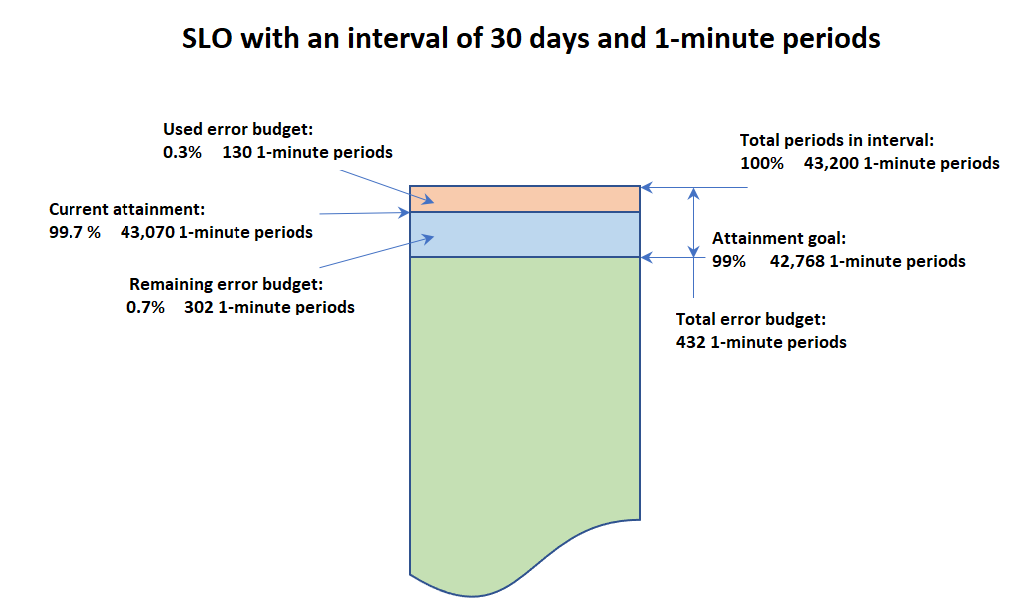
在查看 SLO 相关信息时,您会看到其当前运行状况和错误预算。错误预算是在间隔内可以超出阈值但仍能达到 SLO 的时间长度。总错误预算是在整个间隔内容许的总超限时间。剩余错误预算是当前间隔内容许的剩余超限时间。这一数据为从总错误预算中扣除已发生超限时间的结果。
下图说明了间隔为 30 天、周期为 1 分钟、达标率目标为 99% 时的达标率和错误预算概念。30 天包括 43200 个 1 分钟周期。43200 的 99% 为 42768,因此当月必须有 42768 分钟处于运行正常状态才能达到 SLO。到目前为止,在当前间隔内,有 130 个运行不正常的 1 分钟周期。
确定每个周期是否成功
在每个周期内,SLI 数据会根据用于 SLI 的统计数据聚合到单个数据点中。此数据点表示周期的整个长度。将单个数据点与 SLI 阈值进行比较,以确定该周期运行是否正常。在控制面板上看到当前时间范围内运行不正常的周期后,您的服务运营商便得知需要对服务进行分类。
如果确定该周期运行不正常,则会根据错误预算将整个周期长度全部计为失败。您可以通过跟踪错误预算,了解服务是否长时间达到所需性能水平。
时间窗口排除项
时间窗口排除项是具有定义的开始和结束日期的时间段。该时间段不包含在 SLO 的绩效指标中,您可以安排一次性或重复的时间排除窗口。例如,计划维护。
注意
对于基于周期的 SLO,排除窗口中的 SLI 数据被视为无违规。
对于基于请求的 SLO,排除窗口中的所有善意请求和恶意请求都将被排除。
如果完全排除基于请求的 SLO 间隔,则会发布 100% 的默认达标率指标。
您只能将开始日期指定为未来的时间窗口。
计算基于请求的 SLO 的错误预算和达标率
创建 SLO 后,您可以检索其错误预算报告。错误预算是指您的应用程序可能不符合 SLO 的目标但仍能达到目标的请求量。对于基于请求的 SLO,剩余的错误预算是动态的,可能会增加或减少,具体取决于良好请求数与请求总数的比率
下表说明了基于请求的 SLO 的计算,间隔为 5 天,目标达成率为 85%。在此示例中,我们假设第 1 天之前没有流量。SLO 在第 10 天没有实现目标。
| 时间 | 请求总数 | 错误请求数 | 过去 5 天内累计请求总数 | 过去 5 天内累计良好请求总数 | 基于请求的达标率 | 预算请求总数 | 其余预算请求数 |
|---|---|---|---|---|---|---|---|
|
第 1 天 |
10 | 1 |
10 |
9 |
9/10 = 90% |
1.5 |
0.5 |
|
第 2 天 |
5 |
1 |
15 |
13 |
13/15 = 86% |
2.3 |
0.3 |
|
第 3 天 |
1 |
1 |
16 |
13 |
13/16 = 81% |
2.4 |
-0.6 |
|
第 4 天 |
24 |
0 |
40 |
37 |
37/40 = 92% |
6.0 |
3.0 |
|
第 5 天 |
20 |
5 |
60 |
52 |
52/60 = 87% |
9.0 |
1.0 |
|
第 6 天 |
6 |
2 |
56 |
47 |
47/56 = 84% |
8.4 |
-0.6 |
|
第 7 天 |
10 |
3 |
61 |
50 |
50/61 = 82% |
9.2 |
-1.8 |
|
第 8 天 |
15 |
6 |
75 |
59 |
59/75 = 79% |
11.3 |
-4.7 |
| 第 9 天 |
12 |
1 |
63 |
46 |
46/63 = 73% |
9.5 |
-7.5 |
|
第 10 天 |
5 |
57 |
40 |
40/57 = 70% |
8.5 |
-8.5 | |
|
最近 5 天的达标率 |
|
70% |
计算消耗率并可选择设置消耗率警报
您可以使用 Application Signals 来计算服务级别目标的消耗率。消耗率是一种指标,用于指示相对于 SLO 的达标率目标,服务消耗错误预算的速度。它以基线错误率的倍数形式表示。
消耗率根据基线错误率计算,而基线错误率取决于达标率目标。达标率目标是为实现 SLO 目标而必须达到的正常运行时间段或成功请求的百分比。基线错误率为(100% - 达标率目标百分比),此数字将在 SLO 时间间隔结束时恰好耗尽全部错误预算。因此,达标率目标为 99% 的 SLO 的基线错误率将为 1%。
监测消耗率可以告诉我们离基线错误率还有多远。再以 99% 的达标率目标为例,以下各项是正确的:
消耗率 = 1:如果消耗率一直恰好保持在基准错误率,则我们将准确达到 SLO 目标。
消耗率 < 1:如果消耗率低于基线错误率,则我们有望超越 SLO 目标。
消耗率 > 1:如果消耗率高于基线错误率,我们有可能无法实现 SLO 目标。
在创建 SLO 的消耗率时,您还可以选择通过同时创建 CloudWatch 警报来监测消耗率。您可以设置消耗率的阈值,如果消耗率指标超出您设置的阈值,警报可以自动通知您。例如,如果消耗率接近其阈值,您便可以得知,SLO 消耗错误预算的速度超出您团队可以容忍的速度,您的团队可能需要减慢应用程序的流失速度,以确保实现长期性能目标。
创建警报会产生费用。有关 CloudWatch 定价的信息,请参阅 Amazon CloudWatch 定价
计算消耗率
要计算消耗率,必须指定回顾时间窗口。回顾时间窗口是测量错误率的持续时间。
burn rate = error rate over the look-back window / (100% - attainment goal)
注意
当没有消耗率周期的数据时,Application Signals 会根据目标实现情况计算消耗率。
错误率的计算方法是消耗率时间窗口内不良事件数量与事件总数之比:
对于基于时段的 SLO,错误率的计算方法是不良时段除以总时段。总时段表示回顾时间窗口期间的全部时段。
对于基于请求的 SLO,这是将不良请求数除以请求总数的度量。请求总数是回顾时间窗口期间的请求数量。
回顾时间窗口必须是 SLO 时段时间的倍数,并且必须小于 SLO 间隔。
确定消耗率警报的相应阈值
配置消耗率警报时,需要选择消耗率值作为警报阈值。该阈值的值取决于 SLO 间隔时长和回顾时间窗口,也取决于您的团队想要采用哪种方法或思维模型。有两种主要的方法可用来确定阈值。
方法 1:确定您的团队愿意在回顾时间窗口内消耗的估计总错误预算百分比。
如果您想在上一消耗率回顾时段内花费估计错误预算的 X% 时收到警报,则消耗率阈值如下:
burn rate threshold = X% * SLO interval length / look-back window size
例如,一小时内 30 天(720 小时)错误预算花费的 5% 所需消耗率为 5% * 720 / 1 = 36。因此,如果消耗速率回顾时间窗口为 1 小时,我们将消耗速率阈值设置为 36。
您可以通过此方法使用 CloudWatch 控制台创建消耗率警报。您可以指定数字 X,然后使用上述公式确定阈值。
SLO 间隔时长根据 SLO 间隔类型确定:
对于具有滚动间隔的 SLO,其间隔时长以小时为单位。
对于具有基于日历的间隔的 SLO:
如果单位是天或周,则间隔时长以小时为单位。
如果单位为月,则我们以 30 天作为估计时长,然后将其转换为小时数。
方法 2:确定下一个间隔预算耗尽之前的时间
要让警报在最近一次回顾时间窗口内的当前错误率表明距离预算耗尽的时间少于 X 小时(假设当前剩余预算为 100%)时通知您,您可以使用以下公式来确定消耗率阈值。
burn rate threshold = SLO interval length / X
我们要强调的是,在上述公式中,直到预算耗尽(X)的时间假设当前剩余总预算为 100%,因此它没有考虑到在这段时间内已经消耗的预算量。我们也可以将其视为下一个间隔的预算耗尽的时间。
消耗率警报演练
举例来说,假设我们采用滚动间隔为 28 天的 SLO。为此 SLO 设置消耗率警报涉及两个步骤:
设置消耗率和回顾时间窗口。
创建用于监测消耗率的 CloudWatch 警报。
首先,请确定该服务愿意在特定时间范围内消耗多少总错误预算。换句话说,用这句话来陈述您的目标:“我想在 M 分钟内消耗总错误预算的 X% 时收到警报。”
例如,您可能需要将目标设置为在 60 分钟内消耗总错误预算的 2% 时收到警报。
要设置消耗率,首先要定义回顾时间窗口。回顾时间窗口为 M,在本例中为 60 分钟。
接下来,您将创建 CloudWatch 警报。执行此操作时,必须指定消耗率的阈值。如果消耗率超过此阈值,警报将通知您。要计算阈值,请使用以下公式:
burn rate threshold = X% * SLO interval length/ look-back window size
在本例中,X 为 2,因为我们想要在 60 分钟内消耗 2% 的错误预算时收到警报。间隔时长为 40320 分钟(28 天),回顾时间窗口为 60 分钟,因此答案是:
burn rate threshold = 2% * 40,320 / 60 = 13.44.
在本例中,您可以将 13.44 设置为警报阈值。
具有不同时间窗口的多个警报
通过对多个回顾时间窗口设置警报,您可以快速检测到较短时间窗口内错误率的急剧增加,同时检测出较小的错误率增加,如果这些没有引起注意,最终会耗尽错误预算。
此外,您可以设置较长时间窗口的消耗率和较短时间窗口(较长时间窗口的 1/12)的消耗率的复合警报,并且只有两个消耗率都突破阈值时才会收到通知。这样,您就可以确保只对仍在发生的情况发出警报。有关 CloudWatch 中复合警报的更多信息,请参阅创建复合告警。
注意
在创建消耗率时,您可以设置消耗率的指标警报。要设置多个消耗率警报的复合警报,必须按照创建复合告警中的说明进行操作。
Google Site Reliability Engineering workbook
一个复合警报可监测一对警报:一个 1 小时的时间窗口和一个 5 分钟的时间窗口。
第二个复合警报可监测一对警报:一个 6 小时的时间窗口和一个 30 分钟的时间窗口。
第三个复合警报可监测一对警报:一个 3 天的时间窗口和一个 6 小时的时间窗口。
完成此设置的步骤如下:
-
创建 5 种消耗率,时间窗口为 5 分钟、30 分钟、1 小时、6 小时和 3 天。
创建以下三对 CloudWatch 警报。每对包括一个较长时间窗口和一个较短时间窗口(即较长时间窗口的 1/12),阈值使用确定消耗率警报的相应阈值中的步骤确定。计算警报对中每个警报的阈值时,请在计算中使用警报对中较长的回顾时间窗口。
1 小时和 5 分钟消耗率的警报(阈值由总预算的 2% 确定)
6 小时和 30 分钟消耗率的警报(阈值由总预算的 5% 确定)
3 天和 6 小时消耗率的警报(阈值由总预算的 10% 确定)
对于每对警报,创建一个复合警报,以便在两个单独的警报都进入“警报”状态时收到警报。有关创建复合警报更多信息,请参阅创建复合告警。
例如,如果第一对警报(1 小时时间窗口和 5 分钟时间窗口)名为
OneHourBurnRate和FiveMinuteBurnRate,则 CloudWatch 复合警报规则将为ALARM(OneHourBurnRate) AND ALARM(FiveMinuteBurnRate)
之前的策略仅适用于间隔时长至少为三小时的 SLO。对于间隔时长较短的 SLO,我们建议您从一对消耗率警报开始,其中一个警报的回顾时间窗口为另一个警报回顾时间窗口的 1/12。然后,基于这对警报设置复合警报。
创建 SLO
我们建议您同时设置关键应用程序的延迟和可用性 SLO。Application Signals 收集的这些指标与共同业务目标一致。
您还可以根据任何 CloudWatch 指标或任何生成单个时间序列的指标数学表达式设置 SLO。
当您首次在账户中创建 SLO 时,CloudWatch 会自动在您的账户中创建 AWSServiceRoleForCloudWatchApplicationSignals 服务相关角色(如果该角色尚不存在)。此服务相关角色允许 CloudWatch 收集 CloudWatch Logs 数据、X-Ray 跟踪数据、CloudWatch 指标数据,以及您账户中应用程序的标记数据。有关 CloudWatch 服务相关角色的更多信息,请参阅 为 CloudWatch 使用服务相关角色。
创建 SLO 时,您可以指定它是基于周期的 SLO 还是基于请求的 SLO。每种类型的 SLO 都有不同的方式来评估应用程序的性能是否符合达标率目标。
基于周期的 SLO 在指定的总时间间隔内使用定义的时间段。在每个时间段内,Application Signals 决定应用程序是否实现了目标。达标率的计算方法为
number of good periods/number of total periods。例如,对于基于周期的 SLO,达到 99.9% 的达标率目标意味着在您的时间间隔内,您的应用程序必须在至少 99.9% 的时间段内达到性能目标。
基于请求的 SLO 不使用预定义的时间段。相反,SLO 在时间间隔期间测量
number of good requests/number of total requests。您可以随时找出在指定时间戳之前的时间间隔内良好请求数与请求总数的比率,并根据您的 SLO 中设定的目标来测量该比率。
创建基于周期的 SLO
请使用以下过程创建基于周期的 SLO。
创建基于周期的 SLO
通过 https://console.aws.amazon.com/cloudwatch/
打开 CloudWatch 控制台。 在导航窗格中,选择服务级别目标(SLO)。
请选择创建 SLO。
对于设置服务级别指标(SLI),执行以下任一操作:
要使用标准应用程序指标
Latency或Availability,针对某个服务操作、服务的所有操作或服务依赖项设置 SLO,请执行以下操作:对于类型,选择服务。
选择一个此 SLO 将监控的账户。
选择此 SLO 将监控的服务。
对于类型,选择以下选项之一:
服务操作:针对某个服务操作、所有操作或操作子集创建 SLO。
服务依赖项:针对服务依赖项创建 SLO。
如果选择了服务操作,请选择此 SLO 将监控的操作。要创建用于监控所有操作中服务的整体运行状况的服务级别 SLO,请选择所有操作。否则,请选择要监控的特定操作。
要创建用于监控操作子集的 SLO,请参阅针对多个操作创建复合 SLO。
如果选择了服务依赖项,请执行以下操作:
在选择操作下,选择一个特定操作或选择所有操作,以使用该服务调用依赖项时所有操作的指标。
在选择依赖项下,搜索并选择要测量其可靠性的所需依赖项。
选择依赖项后,您可以根据依赖项查看更新的图表和历史数据。
对于选择计算方法,选择周期。
选择服务和选择操作下拉列表中填充了过去 24 小时处于活动状态的服务和操作。
选择可用性或延迟,然后设置阈值。
为任何 CloudWatch 指标或 CloudWatch 指标数学表达式设置 SLO:
对于类型,选择 CloudWatch 指标。
选择选择 CloudWatch 指标。
出现选择指标屏幕。使用浏览或查询选项卡查找所需指标或创建指标数学表达式。
选择所需指标后,选择图表化指标选项卡,然后选择要用于 SLO 的统计数据和周期。然后选择 Select metric(选择指标)。
有关这些屏幕的信息,请参阅 绘制指标图表 和 向 CloudWatch 图表中添加数学表达式。
对于选择计算方法,选择周期。
在设置条件中,选择 SLO 的比较运算符和阈值作为成功指标。
如果您在步骤 4 中选择了服务,请设置此 SLO 的周期长度。
输入 SLO 的名称。纳入服务或操作的名称以及适当的关键字(例如延迟或可用性)有助于您在分类期间快速识别 SLO 状态所表示的含义。
设置 SLO 的间隔和达标率目标。有关间隔和达标率目标以及二者如何协同工作的更多信息,请参阅 SLO 概念。
(可选)如需设置 SLO 消耗率,请执行以下操作:
设置消耗率回顾时间窗口的时长(以分钟为单位)。有关如何选择此时长的信息,请参阅消耗率警报演练。
要为此 SLO 创建更多消耗率,请选择添加更多消耗率,然后设置其他消耗率的回顾时间窗口。
(可选)通过执行以下操作创建消耗率警报:
在设置消耗率警报下,选中要为其创建警报的每个消耗率对应的复选框。对于每个警报,执行以下操作:
指定当警报进入“警报”状态时用于通知的 Amazon SNS 主题。
设置消耗率阈值,或指定要保持低于上次回顾时间窗口内估计的消耗总预算百分比。如果您设置了估计消耗总预算的百分比,则会为您计算消耗率阈值并将其用于警报。要确定设置的阈值或了解如何使用此选项来计算消耗率阈值,请参阅确定消耗率警报的相应阈值。
(可选)为 SLO 设置一个或多个 CloudWatch 警报或警告阈值。
如果根据应用程序的 SLI 性能判断其运行不正常,则 CloudWatch 警报可以使用 Amazon SNS 主动通知您。
要创建警报,请选中任一警报复选框,然后输入或创建 Amazon SNS 主题,以便在警报进入
ALARM状态时用于发送通知。有关 CloudWatch 警报的更多信息,请参阅 使用 Amazon CloudWatch 告警。创建警报会产生费用。有关 CloudWatch 定价的信息,请参阅 Amazon CloudWatch 定价。 如果您设置了警告阈值,其将显示在 Application Signals 屏幕中,从而帮助您识别可能无法实现的 SLO(即使此类 SLO 当前运行正常)。
要设置警告阈值,请在警告阈值中输入阈值。当 SLO 的错误预算低于警告阈值时,多个 Application Signals 屏幕中的 SLO 都会标有警告标记。警告阈值还会显示在错误预算图形中。您也可以创建基于警告阈值的 SLO 警告警报。
(可选)如需设置 SLO 时间窗口排除项,请执行以下操作:
在排除时间窗口下,设置要从 SLO 性能指标中排除的时间窗口。
您可以选择设置时间窗口并输入每小时或每月的开始窗口,也可以选择使用 CRON 设置时间窗口并输入 CRON 表达式。
在重复下,设置此时间窗口排除项是否重复。
(可选)在添加原因下,您可以选择输入排除时间窗口的原因。例如,计划维护。
选择添加时间窗口,最多可添加 10 个时间排除窗口。
要向此 SLO 添加标签,请选择标签选项卡,然后选择添加新标签。标签有助于您管理、识别、组织、搜索和筛选 资源。有关标记的更多信息,请参阅标记您的 Amazon 资源。
注意
如果与此 SLO 相关的应用程序已在 Amazon Service Catalog AppRegistry 中注册,则可以使用
awsApplication标签将此 SLO 与 AppRegistry 中的该应用程序关联。有关更多信息,请参阅 What is AppRegistry?请选择创建 SLO。如果您还选择了创建一个或多个警报,为体现这一点,按钮名称会变更。
创建基于请求的 SLO
请使用以下过程创建基于周期的 SLO。
创建基于请求的 SLO
通过 https://console.aws.amazon.com/cloudwatch/
打开 CloudWatch 控制台。 在导航窗格中,选择服务级别目标(SLO)。
请选择创建 SLO。
对于设置服务级别指标(SLI),执行以下任一操作:
要使用标准应用程序指标
Latency或Availability,针对某个服务操作、服务的所有操作或服务依赖项设置 SLO,请执行以下操作:对于类型,选择服务。
选择此 SLO 将监控的服务。
对于类型,选择以下选项之一:
服务操作:针对某个服务操作、所有操作或操作子集创建 SLO。
服务依赖项:针对服务依赖项创建 SLO。
如果选择了服务操作,请选择此 SLO 将监控的操作。要创建用于监控所有操作中服务的整体运行状况的服务级别 SLO,请选择所有操作。否则,请选择要监控的特定操作。
要创建用于监控操作子集的 SLO,请参阅针对多个操作创建复合 SLO。
如果选择了服务依赖项,请执行以下操作:
在选择操作下,选择一个特定操作或选择所有操作,以使用该服务调用依赖项时所有操作的指标。
在选择依赖项下,搜索并选择要测量其可靠性的所需依赖项。
选择依赖项后,您可以根据依赖项查看更新的图表和历史数据。
对于选择计算方法,选择请求。
-
选择服务和选择操作下拉列表中填充了过去 24 小时处于活动状态的服务和操作。
选择可用性或延迟。如果选择延迟,请设置阈值。
为任何 CloudWatch 指标或 CloudWatch 指标数学表达式设置 SLO:
对于类型,选择 CloudWatch 指标。
-
对于定义目标请求,请执行以下操作:
选择是要测量良好请求还是错误请求。
-
选择选择 CloudWatch 指标。该指标将是目标请求数与请求总数的比率的分子。如果您使用延迟指标,请使用切尾计数(TC)统计数据。如果阈值为 9 毫秒,并且您使用的是小于 (<) 比较运算符,则使用阈值 TC (:threshold - 1)。有关 SRR 的更多信息,请参阅语法。
出现选择指标屏幕。使用浏览或查询选项卡查找所需指标或创建指标数学表达式。
-
对于定义请求总数,选择要用于来源的 CloudWatch 指标。该指标将是目标请求数与请求总数的比率的分母。
出现选择指标屏幕。使用浏览或查询选项卡查找所需指标或创建指标数学表达式。
选择所需指标后,选择图表化指标选项卡,然后选择要用于 SLO 的统计数据和周期。然后选择 Select metric(选择指标)。
如果您使用的延迟指标为每个请求发出一个数据点,请使用样本计数统计数据来计算请求总数。
有关这些屏幕的信息,请参阅 绘制指标图表 和 向 CloudWatch 图表中添加数学表达式。
输入 SLO 的名称。纳入服务或操作的名称以及适当的关键字(例如延迟或可用性)有助于您在分类期间快速识别 SLO 状态所表示的含义。
设置 SLO 的间隔和达标率目标。有关间隔和达标率目标以及二者如何协同工作的更多信息,请参阅 SLO 概念。
(可选)如需设置 SLO 消耗率,请执行以下操作:
设置消耗率回顾时间窗口的时长(以分钟为单位)。有关如何选择此时长的信息,请参阅消耗率警报演练。
要为此 SLO 创建更多消耗率,请选择添加更多消耗率,然后设置其他消耗率的回顾时间窗口。
(可选)通过执行以下操作创建消耗率警报:
在设置消耗率警报下,选中要为其创建警报的每个消耗率对应的复选框。对于每个警报,执行以下操作:
指定当警报进入“警报”状态时用于通知的 Amazon SNS 主题。
设置消耗率阈值,或指定要保持低于上次回顾时间窗口内估计的消耗总预算百分比。如果您设置了估计消耗总预算的百分比,则会为您计算消耗率阈值并将其用于警报。要确定设置的阈值或了解如何使用此选项来计算消耗率阈值,请参阅确定消耗率警报的相应阈值。
(可选)为 SLO 设置一个或多个 CloudWatch 警报或警告阈值。
如果根据应用程序的 SLI 性能判断其运行不正常,则 CloudWatch 警报可以使用 Amazon SNS 主动通知您。
要创建警报,请选中任一警报复选框,然后输入或创建 Amazon SNS 主题,以便在警报进入
ALARM状态时用于发送通知。有关 CloudWatch 警报的更多信息,请参阅 使用 Amazon CloudWatch 告警。创建警报会产生费用。有关 CloudWatch 定价的信息,请参阅 Amazon CloudWatch 定价。 如果您设置了警告阈值,其将显示在 Application Signals 屏幕中,从而帮助您识别可能无法实现的 SLO(即使此类 SLO 当前运行正常)。
要设置警告阈值,请在警告阈值中输入阈值。当 SLO 的错误预算低于警告阈值时,多个 Application Signals 屏幕中的 SLO 都会标有警告标记。警告阈值还会显示在错误预算图形中。您也可以创建基于警告阈值的 SLO 警告警报。
(可选)如需设置 SLO 时间窗口排除项,请执行以下操作:
在排除时间窗口下,设置要从 SLO 性能指标中排除的时间窗口。
您可以选择设置时间窗口并输入每小时或每月的开始窗口,也可以选择使用 CRON 设置时间窗口并输入 CRON 表达式。
在重复下,设置此时间窗口排除项是否重复。
(可选)在添加原因下,您可以选择输入排除时间窗口的原因。例如,计划维护。
选择添加时间窗口,最多可添加 10 个时间排除窗口。
要向此 SLO 添加标签,请选择标签选项卡,然后选择添加新标签。标签有助于您管理、识别、组织、搜索和筛选 资源。有关标记的更多信息,请参阅标记您的 Amazon 资源。
注意
如果与此 SLO 相关的应用程序已在 Amazon Service Catalog AppRegistry 中注册,则可以使用
awsApplication标签将此 SLO 与 AppRegistry 中的该应用程序关联。有关更多信息,请参阅 What is AppRegistry?请选择创建 SLO。如果您还选择了创建一个或多个警报,为体现这一点,按钮名称会变更。
在应用程序监视器上创建 SLO
您可以创建 SLO 来监控 CloudWatch RUM 应用程序监视器的性能。这使您可以跟踪实际的用户体验指标,确保您的 Web 和移动应用程序达到性能目标。应用程序监视器上的 SLO 使用基于请求的评估,来衡量良好请求数与总请求数的比率。
在应用程序监视器上创建 SLO
通过 https://console.aws.amazon.com/cloudwatch/
打开 CloudWatch 控制台。 在导航窗格中,选择服务级别目标(SLO)。
请选择创建 SLO。
在设置服务级别指标(SLI)中,请选择 RUM AppMonitor。
从下拉列表中选择此 SLO 将监控的应用程序监视器。该列表显示了应用监视器名称以及支持的平台(Web、iOS 或 Android)。
(可选)选择要监控的特定页面或屏幕。如果您未选择页面,SLO 将监控应用程序监视器的所有页面。
在选择指标中,选择要用于 SLI 的指标。可用指标取决于平台:
对于 Web 应用程序:
PerformanceNavigationDuration、JSErrorCount、Http4xxCount和Http5xxCount对于移动应用程序(iOS 和 Android):
ScreenLoadTime、CrashCount、Http4xxCount和Http5xxCount
在设置条件中,选择 SLO 的比较运算符和阈值作为成功指标。
输入 SLO 的名称。纳入应用程序监视器名称和适当的关键字,有助于您在分类期间快速识别 SLO 状态所表示的含义。
设置 SLO 的间隔和达标率目标。有关更多信息,请参阅 SLO 概念。
(可选)根据需要配置消耗速率和警报。有关更多信息,请参阅 计算消耗率并可选择设置消耗率警报。
(可选)根据需要设置时间窗口排除项。
(可选)添加标签以帮助组织和识别此 SLO。
请选择创建 SLO。
在金丝雀上创建 SLO
您可以创建 SLO 来监控 CloudWatch Synthetics 金丝雀的性能。这使您可以跟踪综合监控结果,并确保端点和 API 满足可用性和性能目标。金丝雀上的 SLO 使用基于周期的评估,其中每次金丝雀运行都被视为一个离散的评估期。
在金丝雀上创建 SLO
通过 https://console.aws.amazon.com/cloudwatch/
打开 CloudWatch 控制台。 在导航窗格中,选择服务级别目标(SLO)。
请选择创建 SLO。
在设置服务级别指标(SLI)中,请选择 Synthetics 金丝雀。
从下拉列表中选择此 SLO 将监控的金丝雀。
在选择指标中,请选择
SuccessPercent或Duration:SuccessPercent衡量金丝雀运行的成功百分比Duration衡量每次金丝雀运行需要多长时间才能完成
在设置条件中,选择 SLO 的比较运算符和阈值作为成功指标。
输入 SLO 的名称。纳入金丝雀名称和适当的关键字,有助于您在分类期间快速识别 SLO 状态所表示的含义。
设置 SLO 的间隔和达标率目标。有关更多信息,请参阅 SLO 概念。
(可选)根据需要配置消耗速率和警报。有关更多信息,请参阅 计算消耗率并可选择设置消耗率警报。
(可选)根据需要设置时间窗口排除项。
(可选)添加标签以帮助组织和识别此 SLO。
请选择创建 SLO。
针对多个操作创建复合 SLO
您可以创建复合 SLO 来监控服务操作子集中的 Availability 指标。想要同时跟踪一组相关操作的可靠性,而不是监控单个操作或所有操作时,这很有用。
复合 SLO 支持基于周期的评估和基于请求的评估。可以选择包含 2 至 20 个操作。选择操作的方法有两种:
显式选择:从下拉列表中手动选择单个操作。
模式匹配:使用前缀或正则表达式按名称自动匹配操作。
注意
复合 SLO 仅支持 Availability 指标。Latency 指标不适用于复合 SLO。
创建复合 SLO
通过 https://console.aws.amazon.com/cloudwatch/
打开 CloudWatch 控制台。 在导航窗格中,选择服务级别目标(SLO)。
请选择创建 SLO。
对于设置服务级别指标(SLI)、类型,选择服务。
选择此 SLO 将监控的服务。
对于类型,选择服务操作。
选择要包含在此复合 SLO 中的操作。请执行以下操作之一:
要手动选择操作,请从操作下拉列表中选择多个操作。可以在2至20个操作之间进行选择。
所选操作在下拉列表下方显示为标记。可以通过选择操作标记上的关闭图标来移除该操作。
要按模式选择操作,请选中使用模式匹配复选框。然后执行以下操作:
对于模式类型,选择前缀或正则表达式。
前缀匹配名称以您输入的文本开头的所有操作。例如,输入
Invoke可匹配名为InvokeFunction、InvokeAsync等的操作。正则表达式匹配名称与您输入的正则表达式模式匹配的所有操作。例如,输入
^Invoke.*可匹配与前缀示例相同的操作。
在模式字段中输入模式。控制台将匹配的操作作为标记显示在字段下方,以便您可以验证结果。
选择操作后,该指标将自动设置为可用性。
对于选择计算方法,选择周期或请求。
如果选择了周期,请为此 SLO 设置周期长度和可用性阈值。
为 SLO 输入名称,或者使用自动生成的名称。自动生成的名称包括服务名称和“复合”一词,可帮助您识别它。
设置 SLO 的间隔和达标率目标。有关间隔和达标率目标以及二者如何协同工作的更多信息,请参阅 SLO 概念。
(可选)根据需要配置消耗速率和警报。有关更多信息,请参阅 计算消耗率并可选择设置消耗率警报。
(可选)为 SLO 设置一个或多个 CloudWatch 警报或警告阈值。
(可选)根据需要设置时间窗口排除项。
(可选)添加标签以帮助组织和识别此 SLO。
请选择创建 SLO。
使用 SLO 建议
Application Signals 可以根据过去 30 天的历史指标数据,为您的 SLO 配置提供建议。您提供有关服务和要创建的 SLO 类型的基本信息后,Application Signals 会分析您的指标数据,并建议指标阈值、SLO 目标和消耗速率窗口的最佳值。
要获得 SLO 建议,您必须提供以下信息:
选择服务操作或服务依赖项:
对于服务操作,请指定服务和操作
对于服务依赖项,请指定服务、操作(或所有操作)和依赖项
SLO 评估类型:基于周期或基于请求
标准应用程序指标的类型:
Latency或Availability
根据这些信息和服务的历史性能数据,Application Signals 建议使用以下 SLO 配置参数:
指标阈值 – SLI 的性能阈值,根据服务在过去 30 天的实际性能计算得出。
SLO 目标 – 建议的实现目标百分比,与服务的历史可靠性保持一致。
消耗速率窗口 – 推荐的回顾窗口持续时间,用于监控您的服务消耗错误预算的速度。
您可以接受建议值,也可以根据特定业务要求进行调整。这些建议为配置反映服务实际性能特征的 SLO 提供了数据驱动的起点。
查看 SLO 状态并对其进行分类
您可以使用 CloudWatch 控制台中的服务级别目标或服务选项快速查看 SLO 的运行状况。服务视图提供运行不正常的服务比率的概览视图,该比率根据您设置的 SLO 计算得出。有关使用服务选项的更多信息,请参阅 使用 Application Signals 监控应用程序的运行状况。
服务级别目标视图提供了您的组织的宏观视图。您可以整体查看已实现和未实现的 SLO。这有助于您了解,根据所选 SLI,有多少服务和操作的性能长期达到您的预期。
使用服务级别目标视图查看所有 SLO
-
通过 https://console.aws.amazon.com/cloudwatch/
打开 CloudWatch 控制台。 在导航窗格中,选择服务级别目标(SLO)。
随即显示服务级别目标(SLO)列表。
您可以在 SLI 状态列中快速查看 SLO 的当前状态。要对 SLI 进行排序,以便将所有运行不正常的 SLI 位于列表顶部,请选择 SLI 状态列,直到运行不正常的 SLI 均位于顶部。
SLO 表格默认包含以下各列。您可以通过选择列表上方的齿轮图标调整显示列。有关目标、SLI、达标率和间隔的更多信息,请参阅 SLO 概念。
SLO 的名称。
目标列显示各个间隔内必须成功达到 SLI 阈值才能达到 SLO 目标的周期百分比。此列还会显示 SLO 的间隔长度。
SLI 状态显示应用程序的当前运行状态是否正常。如果 SLO 在当前选定时间范围内的任何时段运行不正常,SLI 状态则显示为运行不正常。
如果此 SLO 配置为监控依赖项,则依赖项和远程操作列将显示有关该依赖项的详细信息。
最终达标率是指截至选定时间范围结束达到的达标水平。按此列排序,查看最有可能无法达到的 SLO。
达标率增量是选定时间范围开始和结束时达标水平的差值。增量为负意味着该指标呈下降趋势。按此列排序,查看 SLO 的最新变化趋势。
最终误差预算(%)是该时段内可能有运行不正常的周期但仍能成功实现 SLO 的总时间百分比。如果您将其设为 5%,并且 SLI 在该间隔剩余周期的 5% 或更短的时间内处于运行不正常状态,仍能成功实现 SLO。
误差预算增量是选定时间范围的开始和结束的误差预算差值。增量为负意味着该指标呈衰退趋势。
结束误差预算(时间)是间隔内可能运行不正常但仍能成功实现 SLO 的实际时间。例如,假设为 14 分钟,则如果在剩余间隔内 SLI 运行不正常的时间少于 14 分钟,则仍能成功实现 SLO。
-
结束误差预算(请求)是时间间隔内可能运行不正常但仍能成功实现 SLO 的请求数。对于基于请求的 SLO,此值是动态的,可能会随着累积的请求总数随时间的变化而波动。
服务、操作和类型列显示设置此 SLO 的服务和操作的信息。
要查看 SLO 的达标率和错误预算图形,请选择 SLO 名称旁边的单选按钮。
页面顶部的图形显示 SLO 达标率和错误预算状态。此外还显示与此 SLO 关联的 SLI 指标的图形。
要对未达到目标的 SLO 进一步分类,请选择该 SLO 的关联服务名称、操作名称或依赖项名称。您将进入详细信息页面,您可以在此进行进一步分类。有关更多信息,请参阅 通过服务详细信息页面查看详细的服务活动和运行状况。
要更改页面所示图表和表格的时间范围,请在屏幕顶部附近选择新的时间范围。
编辑现有 SLO
按照以下步骤编辑现有 SLO。编辑 SLO 时,只能更改阈值、间隔、达标率目标和标签。要更改服务、操作或指标等其他方面,请创建新的 SLO,而非编辑现有 SLO。
更改部分 SLO 核心配置(例如周期或阈值)后,之前有关达标率和运行状况的所有数据点和评估均会失效。可通过这一操作有效删除并重新创建 SLO。
注意
如果您编辑 SLO,则该 SLO 的关联警报不会自动更新。您可能需要更新警报以使其与 SLO 保持同步。
编辑现有 SLO
-
通过 https://console.aws.amazon.com/cloudwatch/
打开 CloudWatch 控制台。 在导航窗格中,选择服务级别目标(SLO)。
选择要编辑的 SLO 旁边的单选按钮,然后选择操作、编辑 SLO。
进行更改,然后选择保存更改。
删除 SLO
按照以下步骤删除现有 SLO。
注意
如果您删除 SLO,则该 SLO 的关联警报不会自动删除。您需要自行将其删除。有关更多信息,请参阅 管理警报。
删除 SLO
-
通过 https://console.aws.amazon.com/cloudwatch/
打开 CloudWatch 控制台。 在导航窗格中,选择服务级别目标(SLO)。
选择要编辑的 SLO 旁边的单选按钮,然后选择操作、删除 SLO。
选择确认。