CloudWatch 解决方案:Amazon EC2 上的 NVIDIA GPU 工作负载
此解决方案可帮助您使用 CloudWatch 代理为在 EC2 实例上运行的 NVIDIA GPU 工作负载配置开箱即用的指标收集。此外,它还可以帮助您设置预配置的 CloudWatch 控制面板。有关所有 CloudWatch 可观测性解决方案的一般信息,请参阅 CloudWatch 可观测性解决方案。
要求
此解决方案适用于以下情况:
-
计算:Amazon EC2
-
在给定的 Amazon Web Services 区域中跨所有 EC2 实例支持最多 500 个 GPU
-
最新版本的 CloudWatch 代理
-
EC2 实例上已安装 SSM 代理
-
EC2 实例必须已经安装 NVIDIA 驱动程序。某些亚马逊机器映像(AMI)上已经预装 NVIDIA 驱动程序。如果没有安装,您可以手动安装该驱动程序。有关更多信息,请参见在 Linux 实例上安装 NVIDIA 驱动程序。
注意
Amazon Systems Manager(SSM Agent)预装在由 Amazon 和受信任的第三方提供的一些亚马逊机器映像(AMI)上。如果未安装代理,您可以根据操作系统类型使用程序手动安装。
优势
该解决方案提供 NVIDIA 监测,为以下用例提供宝贵的见解:
-
分析 GPU 和内存使用情况,了解性能瓶颈或对额外资源的需求。
-
监测温度和功耗,确保 GPU 在安全范围内运行。
-
评估 GPU 视频工作负载的编码器性能。
-
验证 PCIe 连接是否符合预期的生成和宽度。
-
监测 GPU 时钟速度以检测缩放和限制问题。
以下是该解决方案的主要优点:
-
使用 CloudWatch 代理配置自动收集 NVIDIA 指标,无需手动检测。
-
为 NVIDIA 指标提供预配置的整合 CloudWatch 控制面板。控制面板将自动处理使用该解决方案配置的新 NVIDIA EC2 实例的指标,即使这些指标在您首次创建控制面板时不存在。
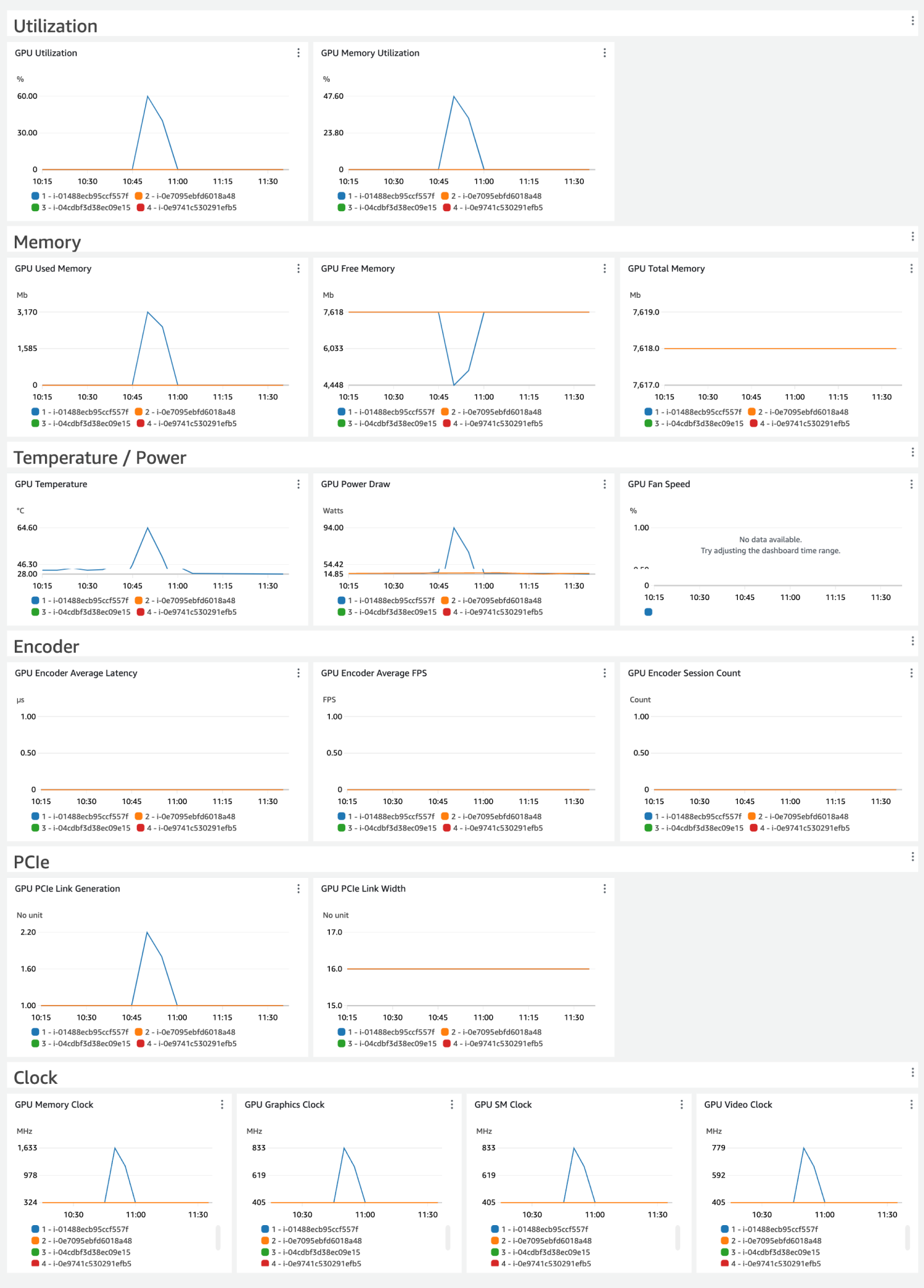
下图是此解决方案控制面板的示例。
成本
此解决方案在您的账户中创建和使用资源。您需要为标准使用量付费,包括以下各项:
-
CloudWatch 代理收集的所有指标按自定义指标收费。此解决方案使用的指标数量取决于 EC2 主机的数量。
-
为该解决方案配置的每台 EC2 主机每个 GPU 总共发布 17 个指标。
-
-
一个自定义控制面板。
-
CloudWatch 代理请求用于发布指标的 API 操作。使用此解决方案的默认配置,CloudWatch 代理每分钟为每台 EC2 主机调用一次 PutMetricData。这意味着每台 EC2 主机将在 30 天(一个月)内调用 PutMetricData API
30*24*60=43,200次。
有关 CloudWatch 定价的信息,请参阅 Amazon CloudWatch 定价
定价计算器可帮助您估算使用此解决方案的每月大致费用。
使用定价计算器估算每月解决方案成本
-
对于选择区域,选择要在其中部署解决方案的区域。
-
在指标部分中,对于指标数量,输入
17 * average number of GPUs per EC2 host * number of EC2 instances configured for this solution。 -
在 API 部分中,对于 API 请求的数量,输入
43200 * number of EC2 instances configured for this solution。 -
默认情况下,CloudWatch 代理每分钟为每台 EC2 主机执行一次 PutMetricData 操作。
-
在控制面板和警报部分中,对控制面板数量输入
1。 -
您可以在定价计算器底部查看每月估算成本。
此解决方案的 CloudWatch 代理配置
CloudWatch 代理是在您的服务器和容器化环境中持续自主运行的软件。它从您的基础设施和应用程序收集指标、日志和跟踪,并将其发送到 CloudWatch 和 X-Ray。
有关 CloudWatch 代理的更多信息,请参阅使用 CloudWatch 代理采集指标、日志和跟踪数据。
此解决方案中的代理配置收集一组指标,以帮助您开始监测和观察 NVIDIA GPU。可以将 CloudWatch 代理配置为收集比控制面板默认显示更多的 NVIDIA GPU 指标。有关您可以收集的所有 NVIDIA GPU 指标的列表,请参阅收集 NVIDIA GPU 指标。
此解决方案的代理配置
代理收集的指标在代理配置中定义。该解决方案提供代理配置,以收集建议的指标,并为解决方案的控制面板提供合适的维度。
在装有 NVIDIA GPU 的 EC2 实例上使用以下 CloudWatch 代理配置。配置将作为参数存储在 SSM 的 Parameter Store 中,稍后将在步骤 2:在 Systems Manager Parameter Store 中存储建议的 CloudWatch 代理配置文件中详细介绍。
{ "metrics": { "namespace": "CWAgent", "append_dimensions": { "InstanceId": "${aws:InstanceId}" }, "metrics_collected": { "nvidia_gpu": { "measurement": [ "utilization_gpu", "temperature_gpu", "power_draw", "utilization_memory", "fan_speed", "memory_total", "memory_used", "memory_free", "pcie_link_gen_current", "pcie_link_width_current", "encoder_stats_session_count", "encoder_stats_average_fps", "encoder_stats_average_latency", "clocks_current_graphics", "clocks_current_sm", "clocks_current_memory", "clocks_current_video" ], "metrics_collection_interval": 60 } } }, "force_flush_interval": 60 }
为您的解决方案部署代理
安装 CloudWatch 代理有几种方法,具体视用例而定。对于此解决方案,我们建议使用 Systems Manager。它提供了控制台体验,使在单个 Amazon 账户中管理一组托管服务器变得更加简单。本节中的说明使用 Systems Manager,适用于没有使用现有配置运行 CloudWatch 代理的情况。您可以按照验证 CloudWatch 代理是否正在运行中的步骤检查 CloudWatch 代理是否正在运行。
如果您已经在部署工作负载的 EC2 主机上运行 CloudWatch 代理并管理代理配置,则可以跳过本节中的说明并按照现有部署机制更新配置。请务必将 NVIDIA GPU 的代理配置与现有的代理配置合并,然后部署合并的配置。如果您使用 Systems Manager 存储和管理 CloudWatch 代理的配置,则可以将配置合并到现有参数值。有关更多信息,请参阅 Managing CloudWatch agent configuration files。
注意
使用 Systems Manager 部署以下 CloudWatch 代理配置,将替换或覆盖 EC2 实例上任何现有的 CloudWatch 代理配置。您可以修改此配置以适应您独有的环境或用例。配置中定义的指标是提供解决方案的控制面板所需的最低要求。
部署过程包括以下步骤:
-
步骤 1:确保目标 EC2 实例具有所需的 IAM 权限。
-
步骤 2:在 Systems Manager Parameter Store 中存储建议的代理配置文件。
-
步骤 3:使用 Amazon CloudFormation 堆栈在一个或多个 EC2 实例上安装 CloudWatch 代理。
-
步骤 4:验证代理设置是否正确配置。
步骤 1:确保目标 EC2 实例具有所需的 IAM 权限
您必须授予 Systems Manager 安装和配置 CloudWatch 代理的权限。您还必须授予 CloudWatch 代理将遥测数据从 EC2 实例发布到 CloudWatch 的权限。确保附加到实例的 IAM 角色已附加 CloudWatchAgentServerPolicy 和 AmazonSSMManagedInstanceCore IAM 策略。
-
创建角色后,将该角色附加到 EC2 实例。要将角色附加到 EC2 实例,请按照将 IAM 角色附加到实例中的步骤进行操作。
步骤 2:在 Systems Manager Parameter Store 中存储建议的 CloudWatch 代理配置文件
Parameter Store 通过安全地存储和管理配置参数,简化了 CloudWatch 代理在 EC2 实例上的安装,而无需硬编码值。这可确保更加安全灵活的部署过程,从而实现集中管理,并且可以更轻松地跨多个实例更新配置。
使用以下步骤将建议的 CloudWatch 代理配置文件作为参数存储在 Parameter Store 中。
创建 CloudWatch 代理配置文件作为参数
访问 https://console.aws.amazon.com/systems-manager/
,打开 Amazon Systems Manager 控制台。 -
确认控制台上的所选区域是运行 NVIDIA GPU 工作负载的区域。
-
从导航窗格中,依次选择应用程序管理、Parameter Store。
-
按照以下步骤为配置创建新参数。
-
选择创建参数。
-
在名称框中,输入您将在后续步骤中用来引用 CloudWatch 代理配置文件的名称。例如
AmazonCloudWatch-NVIDIA-GPU-Configuration。 -
(可选)在描述框中,键入参数的描述。
-
对于参数层,选择标准。
-
对于类型,选择字符串。
-
对于数据类型,选择文本。
-
在值框中,粘贴 此解决方案的代理配置中列出的相应 JSON 块。
-
选择创建参数。
-
步骤 3:安装 CloudWatch 代理并使用 Amazon CloudFormation 模板应用配置
您可以使用 Amazon CloudFormation 安装代理,并将其配置为使用您在前面步骤中创建的 CloudWatch 代理配置。
为此解决方案安装和配置 CloudWatch 代理
-
使用以下链接打开 Amazon CloudFormation 快速创建堆栈向导:https://console.aws.amazon.com/cloudformation/home?#/stacks/quickcreate?templateURL=https://aws-observability-solutions-prod-us-east-1.s3.us-east-1.amazonaws.com/CloudWatchAgent/CFN/v1.0.0/cw-agent-installation-template-1.0.0.json
。 -
确认控制台上的所选区域是运行 NVIDIA GPU 工作负载的区域。
-
对于堆栈名称,输入用于识别此堆栈的名称,如
CWAgentInstallationStack。 -
在参数部分中,指定以下各项:
-
对于 CloudWatchAgentConfigSSM,请输入您之前创建的代理配置的 Systems Manager 参数名称,例如
AmazonCloudWatch-NVIDIA-GPU-Configuration。 -
要选择目标实例,您有两种选择。
-
对于 InstanceIds,请指定一个以逗号分隔的实例 ID 列表,其中包含希望使用此配置安装 CloudWatch 代理的实例 ID。您可以列出一个或多个实例。
-
如果要大规模部署,则可以指定 TagKey 和相应的 TagValue,以将具有此标签和值的所有 EC2 实例作为目标。如果指定 TagKey,则必须指定相应的 TagValue。(对于自动扩缩组,为 TagKey 指定
aws:autoscaling:groupName并为 TagValue 指定自动扩缩组名称,以部署到自动扩缩组内的所有实例。)
-
-
-
检查设置,然后选择创建堆栈。
如果要先编辑模板文件进行自定义,请选择创建堆栈向导下的上传模板文件选项,上传编辑后的模板。有关更多信息,请参阅在 Amazon CloudFormation 控制台上创建堆栈。
注意
完成此步骤后,此 Systems Manager 参数将与目标实例中运行的 CloudWatch 代理相关联。这意味着:
-
如果删除 Systems Manager 参数,代理将停止。
-
如果编辑了 Systems Manager 参数,则配置更改将按计划频率(默认为 30 天)自动应用到代理。
-
如果要立即应用对此 Systems Manager 参数的更改,则必须再次运行此步骤。有关关联的更多信息,请参阅在 Systems Manager 中使用关联。
步骤 4:验证代理设置是否正确配置
您可以按照验证 CloudWatch 代理是否正在运行中的步骤验证 CloudWatch 代理是否已安装。如果 CloudWatch 代理尚未安装和运行,请确保已正确设置所有内容。
-
请确保您已为 EC2 实例附加具有正确权限的角色,如步骤 1:确保目标 EC2 实例具有所需的 IAM 权限中所述。
如果一切设置正确,那么您应该会看到 NVIDIA GPU 指标发布到 CloudWatch。您可以查看 CloudWatch 控制台以验证这些指标是否已发布。
验证 NVIDIA GPU 指标是否已发布到 CloudWatch
通过 https://console.aws.amazon.com/cloudwatch/
打开 CloudWatch 控制台。 -
选择指标、所有指标。
-
确保您已选择部署解决方案的区域,然后选择自定义命名空间、CWAgent。
-
搜索 此解决方案的代理配置中提及的指标,例如
nvidia_smi_utilization_gpu。如果您看到这些指标的结果,则表明这些指标已发布到 CloudWatch。
创建 NVIDIA GPU 解决方案控制面板
此解决方案提供的控制面板通过聚合和显示所有实例的指标来显示 NVIDIA GPU 指标。控制面板显示每个指标排名靠前的贡献者(每个指标的前 10 名小部件)明细。这可以帮助您快速识别对观测指标有显著影响的异常值或实例。
要创建控制面板的操作,可以使用以下选项:
使用 CloudWatch 控制台创建控制面板。
使用 Amazon CloudFormation 控制台部署控制面板。
以 Amazon CloudFormation 基础设施即代码,并将其作为持续集成(CI)自动化的一部分进行集成。
通过使用 CloudWatch 控制台创建控制面板,您可以在实际创建和收费之前预览控制面板。
注意
此解决方案中使用 Amazon CloudFormation 创建的控制面板显示解决方案部署区域的指标。请务必在发布 NVIDIA GPU 指标的区域创建 Amazon CloudFormation 堆栈。
如果您在 CloudWatch 代理配置中指定了 CWAgent 以外的自定义命名空间,则必须更改控制面板的 Amazon CloudFormation 模板,将 CWAgent 替换为您使用的自定义命名空间。
使用 CloudWatch 控制台创建控制面板
-
使用以下链接打开 CloudWatch 控制台创建控制面板:https://console.aws.amazon.com/cloudwatch/home?#dashboards?dashboardTemplate=NvidiaGpuOnEc2&referrer=os-catalog
。 -
确认控制台上的所选区域是运行 NVIDIA GPU 工作负载的区域。
-
输入控制面板的名称,然后选择创建控制面板。
为了便于将此控制面板与其他区域的类似控制面板区分开来,我们建议在控制面板名称中包含区域名称,例如
NVIDIA-GPU-Dashboard-us-east-1。 -
预览控制面板并选择保存以创建控制面板。
通过 Amazon CloudFormation 创建控制面板
-
使用以下链接打开 Amazon CloudFormation 快速创建堆栈向导:https://console.aws.amazon.com/cloudformation/home?#/stacks/quickcreate?templateURL=https://aws-observability-solutions-prod-us-east-1.s3.us-east-1.amazonaws.com/NVIDIA_GPU_EC2/CloudWatch/CFN/v1.0.0/dashboard-template-1.0.0.json
。 -
确认控制台上的所选区域是运行 NVIDIA GPU 工作负载的区域。
-
对于堆栈名称,输入用于识别此堆栈的名称,如
NVIDIA-GPU-DashboardStack。 -
在参数部分,在 DashboardName 参数下指定控制面板的名称。
-
为了便于将此控制面板与其他区域的类似控制面板区分开来,我们建议在控制面板名称中包含区域名称,例如
NVIDIA-GPU-Dashboard-us-east-1。 -
在功能和转换下确认转换的访问功能。请注意,Amazon CloudFormation 不会添加任何 IAM 资源。
-
检查设置,然后选择创建堆栈。
-
堆栈状态为 CREATE_COM PLETE 后,选择创建的堆栈下的资源选项卡,然后选择物理 ID 下的链接转至控制面板。您也可以通过在控制台左侧导航窗格中选择控制面板,然后在自定义控制面板下找到控制面板名称,在 CloudWatch 控制台中访问控制面板。
如果要编辑模板文件以出于任何目的对其进行自定义,则可以使用创建堆栈向导下的上传模板文件选项来上传编辑后的模板。有关更多信息,请参阅在 Amazon CloudFormation 控制台上创建堆栈。您可以使用以下链接下载模板:https://aws-observability-solutions-prod-us-east-1.s3.us-east-1.amazonaws.com/NVIDIA_GPU_EC2/CloudWatch/CFN/v1.0.0/dashboard-template-1.0.0.json
开始使用 NVIDIA GPU 控制面板
您可以使用新的 NVIDIA GPU 控制面板尝试以下几项任务。这些任务允许您验证控制面板是否正常运行,并为您提供使用它来监测 NVIDIA GPU 的一些实践经验。在尝试这些任务的过程中,您将熟悉如何浏览控制面板和解读可视化指标。
查看 GPU 利用率
从利用率部分,找到 GPU 利用率和内存利用率小部件。这些小部件分别显示了 GPU 主动用于计算的时间百分比以及正在读取或写入的全局内存百分比。高利用率可能表示潜在的性能瓶颈或需要额外的 GPU 资源。
分析 GPU 内存使用情况
在内存部分,找到总内存、已用内存和可用内存小部件。这些小部件可以深入了解 GPU 的总体内存容量以及当前消耗或可用的内存量。内存压力可能会导致性能问题或内存不足错误,因此监测这些指标并确保有足够的内存可用于工作负载非常重要。
监测温度和功耗
在温度/功率部分,找到 GPU 温度和功耗小部件。这些指标对于确保您的 GPU 在安全的散热和功率限制内运行至关重要。
确定编码器性能
在编码器部分,找到编码器会话计数、平均 FPS 和平均延迟小部件。这些指标在 GPU 上运行视频编码工作负载的情况。监测这些指标,确保您的编码器以最佳状态运行,并识别任何潜在的瓶颈或性能问题。
检查 PCIe 链路状态
在 PCIe 部分,找到 PCIe 链路生成和 PCIe 链路宽度小部件。这些指标提供了有关将 GPU 连接到主机系统的 PCIe 链路的信息。确保链路以预期的生成和宽度运行,以避免因 PCIe 瓶颈而导致潜在的性能限制。
查看 GPU 时钟
在时钟部分,找到图形时钟、SM 时钟、内存时钟和视频时钟小部件。这些指标显示了各种 GPU 组件当前的运行频率。监测这些时钟可以帮助确定可能影响性能的 GPU 时钟缩放或频率限制的潜在问题。