克隆 Amazon Aurora 数据库集群卷
使用 Aurora 克隆功能,您可以创建一个新集群,该集群最初与原始集群共享相同的数据页,但它是一个单独且独立的卷。该过程旨在快速且经济高效。我们将新集群及其关联的数据卷称为克隆。与使用其他技术(如还原快照)实际复制数据相比,创建克隆速度更快且空间利用效率更高。
主题
Aurora 克隆概述
Aurora 使用写入时复制协议创建克隆。此机制占用最少的额外空间来创建初始克隆。首次创建克隆时,Aurora 会保留源 Aurora 数据库集群和新(克隆的)Aurora 数据库集群使用的数据的单个副本。只有当源 Aurora 数据库集群或 Aurora 数据库集群克隆对数据(在 Aurora 存储卷上)进行更改时,才会分配额外的存储空间。如需了解有关写入时复制协议的更多信息,请参阅 Aurora 克隆的工作原理。
Aurora 克隆非常适合使用您的生产数据快速设置测试环境,且不会有损坏数据的风险。您可以将克隆用于多种类型的应用程序,例如:
-
对潜在的变化(例如模式变化和参数组变化)进行试验,以评估所有影响。
-
执行工作负载密集型操作,例如导出数据或在克隆上运行分析查询。
-
为开发、测试或其他用途创建生产数据库集群的副本。
您可以从同一个 Aurora 数据库集群创建多个克隆。您还可以从另一个克隆创建多个克隆。
创建 Aurora 克隆后,您可以以不同于源 Aurora 数据库集群的方式配置 Aurora 数据库实例。例如,您可能不需要用于开发目的的克隆来满足与源生产 Aurora 数据库集群相同的高可用性要求。在这种情况下,您可以使用单个 Aurora 数据库实例来配置克隆,而不是使用 Aurora 数据库集群使用的多个数据库实例。
当您使用与源不同的部署配置创建克隆时,将使用源的 Aurora 数据库引擎的最新次要版本创建克隆。
当您从 Aurora 数据库集群创建克隆时,将在您的Amazon账户中创建克隆,该账户即是拥有源 Aurora 数据库集群的账户。但是,您也可以与其它 Amazon 账户共享 Aurora serverless 和预调配 Aurora 数据库集群和克隆。有关更多信息,请参阅 使用 Amazon RAM 与 Amazon Aurora 进行跨账户克隆。
当克隆完成测试、开发等使用目的时,您可以将其删除。
Aurora 克隆的限制
Aurora 克隆具有以下限制:
-
您可以根据需要创建任意数量的克隆,最多为 Amazon Web Services 区域中允许的最大数据库集群数。
-
您可以使用写入时复制协议创建多达 15 个克隆。在具有 15 个克隆后,您创建的下一个克隆是完整副本。完全复制协议的作用类似于时间点恢复。
-
您不能在与源 Aurora 数据库集群不同的 Amazon 区域中创建克隆。
-
不支持并行查询功能的 Aurora 数据库集群无法创建克隆到使用并行查询的集群。要将数据传输到使用并行查询的集群,请创建原始集群的快照,并将其还原到使用并行查询功能的集群。
-
您无法从没有数据库实例的 Aurora 数据库集群创建克隆。您只能克隆具有至少一个数据库实例的 Aurora 数据库集群。
-
您可以在与 Aurora 数据库集群不同的 Virtual Private Cloud (VPC) 中创建克隆。不过,这些 VPC 的子网必须映射到相同的可用区。
-
您可以从预置的 Aurora 数据库集群创建 Aurora 预置的克隆。
-
具有 Aurora serverless 实例的集群遵循与预置集群相同的规则。
Aurora 克隆的工作原理
Aurora 克隆运行于 Aurora 数据库集群的存储层。它使用写入时复制协议,该协议在支持 Aurora 存储卷的底层持久介质方面既快速又节省空间。有关 Aurora 集群卷的更多信息,请参阅 Amazon Aurora 存储概述。
了解写入时复制协议
Aurora 数据库集群将数据存储在底层 Aurora 存储卷中的页面中。
例如,在下图中,您可以找到拥有四个数据页(1、2、3 和 4)的 Aurora 数据库集群(A)。假设从 Aurora 数据库集群创建了一个克隆 B。创建克隆时,未复制任何数据。相反,克隆指向与源 Aurora 数据库集群相同的页面集。
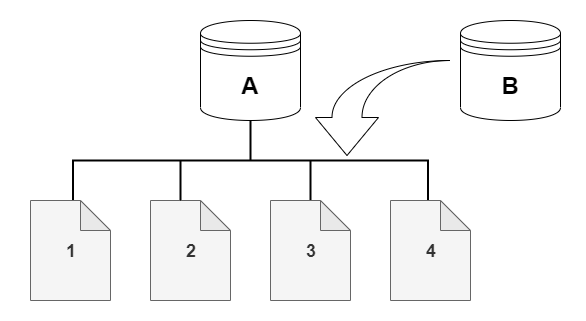
创建克隆时,通常不需要额外的存储空间。写入时复制协议在物理存储介质上使用与源段相同的数据段。只有当源段的容量不足以容纳整个克隆段时,才需要额外的存储空间。如果是这种情况,源段将被复制到另一个物理设备。
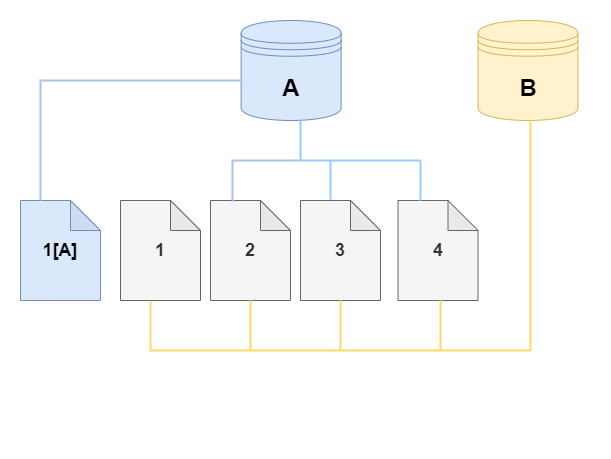
在下图中,您可以找到使用相同集群 A 及其克隆 B 的写入操作时复制协议的示例,如前所示。如果您对 Aurora 数据库集群(A)进行更改,那么第 1 页上保存的数据也将随之而发生改变。Aurora 没有写入原始页面 1,而是创建了一个新页面 1[A]。集群(A)的 Aurora 数据库集群卷现在指向页面 1[A]、2、3 和 4,而克隆(B)仍引用原始页面。
在克隆上,对存储卷的第 4 页进行了更改。Aurora 没有写入原始页面 4,而是创建了一个新页面 4[B]。克隆现在指向页面 1、2、3 和页面 4[B],而集群(A)继续指向 1[A]、2、3 和 4。
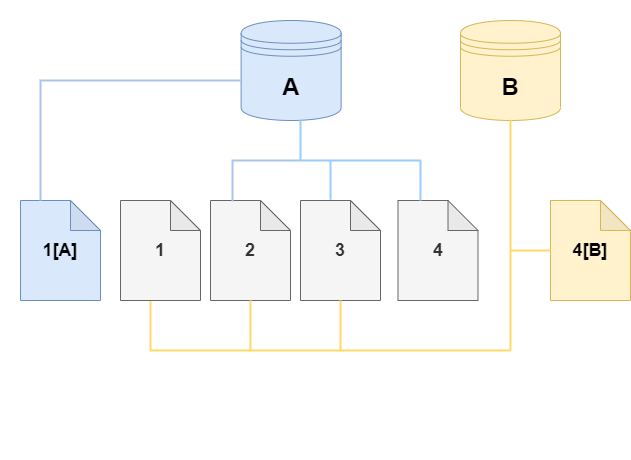
随着时间推移,当源 Aurora 集群卷和克隆上出现了更多更改时,因此需要更多存储空间来捕获和存储更改。
删除源集群卷
最初,克隆卷与从中创建克隆的原始卷共享相同的数据页面。只要原始卷存在,克隆卷就只能被视为克隆创建或修改的页面的拥有者。因此,克隆卷的 VolumeBytesUsed 指标起初很小,只会随着原始集群和克隆之间的数据差异而增长。对于源卷和克隆之间相同的页面,存储费用仅适用于原始集群。有关 VolumeBytesUsed 指标的更多信息,请参阅Amazon Aurora 的集群级指标。
删除与一个或多个克隆关联的源集群卷时,不会更改克隆的集群卷中的数据。Aurora 保留以前由源集群卷拥有的页面。Aurora 会重新分配已删除集群所拥有的页面的存储计费。例如,假设一个原始集群有两个克隆,然后删除了原始集群。现在,原始集群拥有的数据页面中有一半将归一个克隆所拥有。另一半页面将归另一个克隆所拥有。
如果您删除原始集群,则当您创建或删除更多克隆时,Aurora 将继续在共享相同页面的所有克隆间重新分配数据页面的拥有权。因此,您可能会发现,克隆的集群卷的 VolumeBytesUsed 指标值发生变化。随着创建的克隆越来越多以及页面拥有权分布在更多集群中,此指标的值可能会降低。随着删除克隆以及页面拥有权分配给更少数量的集群,此指标的值也可能增加。有关写入操作如何影响克隆卷上的数据页面的信息,请参阅了解写入时复制协议。
当原始集群和克隆归同一个 Amazon 账户拥有时,这些集群的所有存储费用都适用于该同一个 Amazon 账户。如果某些集群是跨账户克隆,则删除原始集群可能会导致对拥有跨账户克隆的 Amazon 账户收取额外的存储费用。
例如,假设一个集群卷在您创建任何克隆之前具有 1000 个已用数据页面。克隆该集群时,最初克隆卷的已用页面数为零。如果克隆对 100 个数据页面进行修改,则只有这 100 个页面会存储在克隆卷上并标记为已用。父卷中其它 900 个未更改的页面由这两个集群共享。在这种情况下,将对父集群收取 1000 个页面的存储费用,而对克隆卷收取 100 个页面的存储费用。
如果您删除源卷,则克隆的存储费用包括它更改的 100 个页面,再加上原始卷中的 900 个共享页面,总共 1000 个页面。
创建 Amazon Aurora 克隆
您可以在与源 Aurora 数据库集群相同的Amazon账户中创建克隆。为此,您可以使用 Amazon Web Services 管理控制台 或 Amazon CLI 并按照以下步骤进行操作。
若要允许其他 Amazon 账户创建克隆或与其他 Amazon 账户共享克隆,请遵照 使用 Amazon RAM 与 Amazon Aurora 进行跨账户克隆 中的步骤。
以下过程介绍了如何使用 Amazon Web Services 管理控制台 克隆 Aurora 数据库集群。
在含有一个 Aurora 数据库实例的 Aurora 数据库集群中使用 Amazon Web Services 管理控制台 结果创建克隆。
这些说明适用于创建克隆的同一 Amazon 账户所拥有的数据库集群。如果数据库集群由其他 Amazon 账户拥有,请改为参阅 使用 Amazon RAM 与 Amazon Aurora 进行跨账户克隆。
使用 Amazon 创建 Amazon Web Services 管理控制台 账户拥有的数据库集群的克隆
登录Amazon Web Services 管理控制台并通过以下网址打开 Amazon RDS 控制台:https://console.aws.amazon.com/rds/
。 在导航窗格中,选择 Databases (数据库)。
从列表中选择您的 Aurora 数据库集群,从 Actions (操作) 中选择 Create clone (创建克隆)。
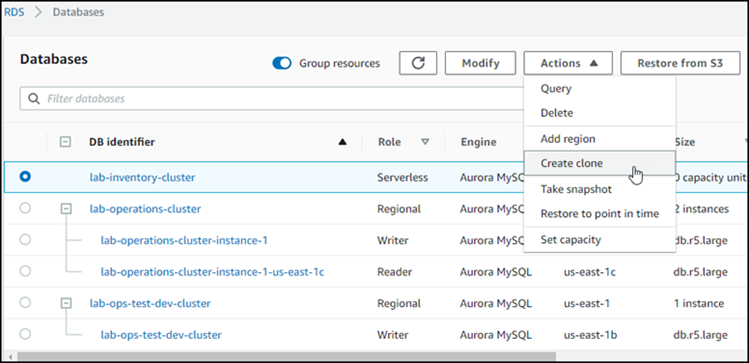
“创建克隆”页面打开后,您可以配置 Aurora 数据库集群克隆的设置、连接和其他选项。
-
对于数据库实例标识符,请输入您要为克隆的 Aurora 数据库集群拟定的名称。
-
对于 Aurora serverless 或预调配数据库集群,请为集群存储配置选择 Aurora I/O-Optimized 或 Aurora Standard。
有关更多信息,请参阅 Amazon Aurora 数据库集群的存储配置。
-
选择数据库实例大小或数据库集群容量:
-
对于预调配克隆,请选择数据库实例类。
您可以使用所提供的设置,也可以为克隆使用不同的数据库实例类。
-
对于 Aurora serverless 克隆,选择容量设置。
您可以使用提供的设置,也可以根据您的克隆更改此类设置。
-
-
根据需要为克隆选择其它设置。要了解有关 Aurora 数据库集群和实例设置的更多信息,请参阅 创建 Amazon Aurora 数据库集群。
-
选择创建克隆。
克隆创建完成后,它将会与您的其他 Aurora 数据库集群一起列在控制台 Databases (数据库) 部分,而且其当前状态也会一起显示。当其状态为可用时,您的克隆即可以使用。
使用 Amazon CLI 克隆 Aurora 数据库集群涉及用于创建克隆集群和向集群添加一个或多个数据库实例的单独步骤。
您使用的 restore-db-cluster-to-point-in-time Amazon CLI 命令将导致 Aurora 数据库集群具有与原始集群相同的存储数据,但没有 Aurora 数据库实例。在克隆可用之后,可以单独创建数据库实例。可以选择数据库实例的数量及其实例类别,来为克隆指定多于或者少于原始集群的计算容量。该过程的步骤如下所示:
-
使用 restore-db-cluster-to-point-in-time CLI 命令创建克隆。
-
使用 create-db-instance CLI 命令创建克隆的写入器数据库实例。
-
(可选)再运行一个 create-db-instance CLI 命令,用于将一个或多个读取器实例添加到克隆集群。使用读取器实例有助于提高克隆的高可用性和读取可扩展性。如果只要将克隆用于开发和测试,则可以跳过此步骤。
创建克隆
使用 restore-db-cluster-to-point-in-time CLI 命令创建初始克隆集群。
从源 Aurora 数据库集群创建克隆
-
使用
restore-db-cluster-to-point-in-timeCLI 命令。为以下参数指定值。在这种典型情况下,克隆使用与原始集群相同的引擎模式:要么是预置,要么是 Aurora serverless。-
--db-cluster-identifier:为克隆选择一个有意义的名称。使用 restore-db-cluster-to-point-in-time CLI 命令命名克隆。然后在 create-db-instance CLI 命令中传递克隆的名称。 -
--restore-type– 使用copy-on-write创建源数据库集群的克隆。如果没有此参数,restore-db-cluster-to-point-in-time将还原 Aurora 数据库集群,而不会创建克隆。 -
--source-db-cluster-identifier– 使用要克隆的源 Aurora 数据库集群的名称。 -
--use-latest-restorable-time– 此值指向源数据库集群的最新可还原卷数据。使用它来创建克隆。
-
以下示例从名为 my-source-cluster 的集群创建一个名为 my-clone 的克隆。
对于 Linux、macOS 或 Unix:
aws rds restore-db-cluster-to-point-in-time \ --source-db-cluster-identifiermy-source-cluster\ --db-cluster-identifiermy-clone\ --restore-type copy-on-write \ --use-latest-restorable-time
对于:Windows
aws rds restore-db-cluster-to-point-in-time ^ --source-db-cluster-identifiermy-source-cluster^ --db-cluster-identifiermy-clone^ --restore-type copy-on-write ^ --use-latest-restorable-time
该命令返回包含克隆详细信息的 JSON 对象。在尝试为您的克隆创建数据库实例之前,请检查以确保您的克隆数据库集群可用。有关更多信息,请参阅 检查状态并获取克隆的详细信息。
例如,假设您有一个名为 tpch100g 的集群需要克隆。下面的 Linux 示例创建了一个名为 tpch100g-clone 的克隆集群,并为该新集群创建了一个名为 tpch100g-clone-instance 的 Aurora serverless 写入器实例和一个名为 tpch100g-clone-instance-2 的预置读取器实例。
有些参数并不需要提供,例如 --master-username 和 --master-user-password。Aurora 会自动从原始集群中确定那些参数。您需要指定的是要使用的数据库引擎。因此,该示例测试新集群以确定要用于 --engine 参数的正确值。
此示例还在创建克隆集群时包括 --serverless-v2-scaling-configuration 选项。这样,即使原始集群未使用 Aurora serverless,您也可以向克隆中添加 Aurora serverless 实例。
$aws rds restore-db-cluster-to-point-in-time \ --source-db-cluster-identifier tpch100g \ --db-cluster-identifier tpch100g-clone \ --serverless-v2-scaling-configuration MinCapacity=0.5,MaxCapacity=16\ --restore-type copy-on-write \ --use-latest-restorable-time$aws rds describe-db-clusters \ --db-cluster-identifier tpch100g-clone \ --query '*[].[Engine]' \ --output textaurora-mysql$aws rds create-db-instance \ --db-instance-identifier tpch100g-clone-instance \ --db-cluster-identifier tpch100g-clone \ --db-instance-class db.serverless \ --engine aurora-mysql$aws rds create-db-instance \ --db-instance-identifier tpch100g-clone-instance-2 \ --db-cluster-identifier tpch100g-clone \ --db-instance-class db.r6g.2xlarge \ --engine aurora-mysql
检查状态并获取克隆的详细信息
可以使用以下命令来检查新创建的克隆集群的状态。
$aws rds describe-db-clusters --db-cluster-identifiermy-clone--query '*[].[Status]' --output text
或者,您可以使用下面的 Amazon CLI 查询获取为您的克隆创建数据库实例所需的状态和其他值。
对于 Linux、macOS 或 Unix:
aws rds describe-db-clusters --db-cluster-identifiermy-clone\ --query '*[].{Status:Status,Engine:Engine,EngineVersion:EngineVersion,EngineMode:EngineMode}'
对于:Windows
aws rds describe-db-clusters --db-cluster-identifiermy-clone^ --query "*[].{Status:Status,Engine:Engine,EngineVersion:EngineVersion,EngineMode:EngineMode}"
此查询返回类似于下述信息的输出:
[ { "Status": "available", "Engine": "aurora-mysql", "EngineVersion": "8.0.mysql_aurora.3.04.1", "EngineMode": "provisioned" } ]
为克隆创建 Aurora 数据库实例
使用 create-db-instance CLI 命令为您的 Aurora serverless 或预调配克隆创建数据库实例。
数据库实例从源数据库集群继承 --master-username 和 --master-user-password 属性。
以下示例为预调配克隆创建数据库实例。
对于 Linux、macOS 或 Unix:
aws rds create-db-instance \ --db-instance-identifiermy-new-db\ --db-cluster-identifiermy-clone\ --db-instance-classdb.r6g.2xlarge\ --engine aurora-mysql
对于:Windows
aws rds create-db-instance ^ --db-instance-identifiermy-new-db^ --db-cluster-identifiermy-clone^ --db-instance-classdb.r6g.2xlarge^ --engine aurora-mysql
以下示例为克隆(此克隆使用支持 Aurora serverless 的引擎版本)创建 Aurora serverless 数据库实例。
对于 Linux、macOS 或 Unix:
aws rds create-db-instance \ --db-instance-identifiermy-new-db\ --db-cluster-identifiermy-clone\ --db-instance-class db.serverless \ --engine aurora-postgresql
对于:Windows
aws rds create-db-instance ^ --db-instance-identifiermy-new-db^ --db-cluster-identifiermy-clone^ --db-instance-class db.serverless ^ --engine aurora-mysql
用于克隆的参数
下表总结了与 restore-db-cluster-to-point-in-time 一起用于克隆 Aurora 数据库集群的各种参数。
| 参数 | 说明 |
|---|---|
|
|
使用要克隆的源 Aurora 数据库集群的名称。 |
|
|
使用 |
|
|
将 |
|
|
此值指向源数据库集群的最新可还原卷数据。使用它来创建克隆。 |
|
|
(支持 Aurora serverless 的较新版本)使用此参数可配置 Aurora serverless 克隆的最小和最大容量。如果未指定此参数,则在修改集群来添加此属性之前,无法在克隆集群中创建任何 Aurora serverless 实例。 |
有关跨 VPC 和跨账户克隆的信息,请参阅以下各节。