Amazon Aurora 数据库集群
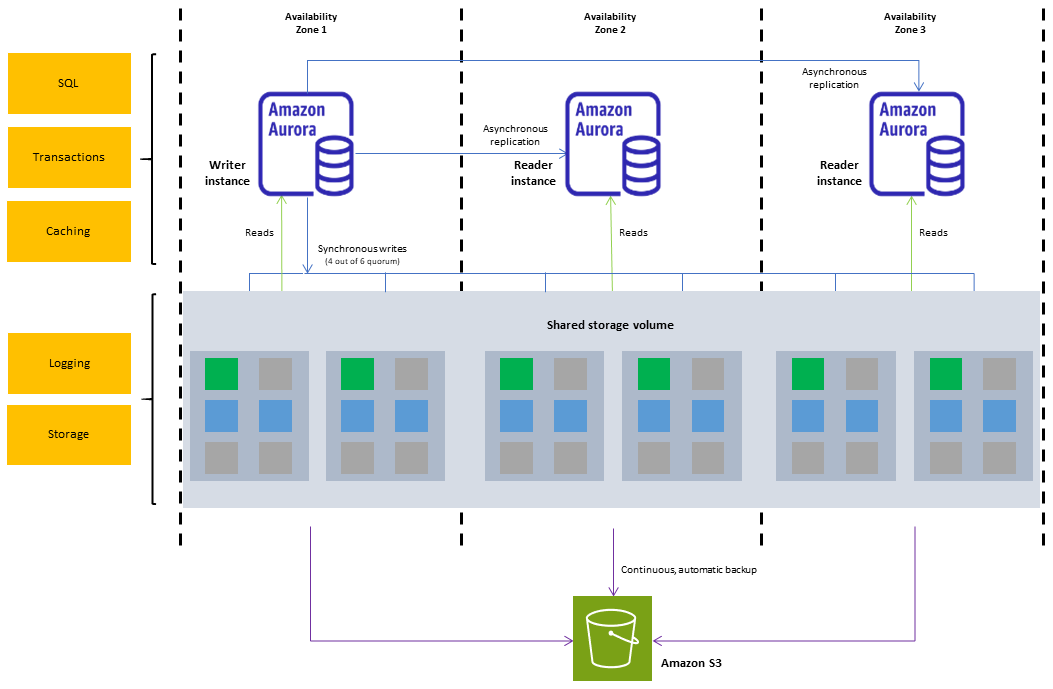
Amazon Aurora 数据库集群包含一个或多个数据库实例以及一个管理这些数据库实例的数据的集群卷。Aurora 集群卷 是一个跨多个可用区的虚拟数据库存储卷,每个可用区具有一个数据库集群数据副本。Aurora 数据库集群由两类数据库实例组成:
-
主(写入器)数据库实例 – 支持读取和写入操作,并执行针对集群卷的所有数据修改。每个 Aurora 数据库集群均有一个主数据库实例。
-
Aurora 副本(读取器数据库实例)– 连接到同一存储卷作为主数据库实例,但仅支持读取操作。除主数据库实例之外,每个 Aurora 数据库集群最多可拥有 15 个 Aurora 副本。通过将 Aurora 副本放在单独的可用区中维护高可用性。当主数据库实例不可用时,Aurora 自动故障转移到 Aurora 副本。您可以为 Aurora 副本指定故障转移优先级。Aurora 副本还可以从主数据库实例分载读取工作负载。
下图说明了 Aurora 数据库集群中的集群卷、写入器数据库实例和读取器数据库实例之间的关系。
注意
上述信息适用于所有 Aurora 数据库集群:预置、并行查询、Aurora Global Database、Aurora Serverless、Aurora MySQL 兼容和 Aurora PostgreSQL 兼容。
此 Aurora 数据库集群说明了计算容量和存储的分离。例如,仅具有单个数据库实例的 Aurora 配置仍是集群,因为基础存储卷涉及跨多个可用区 (AZ) 分布的多个存储节点。
Aurora 数据库集群中的输入/输出(I/O)操作以相同的方式计数,无论它们是在写入器还是读取器数据库实例上。有关更多信息,请参阅 Amazon Aurora 数据库集群的存储配置。