io/aurora_redo_log_flush
在会话向 Amazon Aurora 存储中写入持久数据时,将发生 io/aurora_redo_log_flush 事件。
支持的引擎版本
以下引擎版本支持此等待事件信息:
-
Aurora MySQL 版本 2
上下文
io/aurora_redo_log_flush 事件用于 Aurora MySQL 中的写入输入/输出 (I/O) 操作。
注意
在 Aurora MySQL 版本 3 中,此等待事件名为 io/redo_log_flush。
等待次数增加的可能原因
对于数据持久性,提交需要对稳定存储进行持久写入操作。如果数据库执行的提交太多,写入输入/输出操作会出现等待事件,即 io/aurora_redo_log_flush 等待事件。
在以下示例中,使用 db.r5.xlarge 数据库实例类将 50000 条记录插入到 Aurora MySQL 数据库集群中:
-
在第一个示例中,每个会话逐行插入 10000 条记录。预设情况下,如果数据操纵语言 (DML) 命令不在事务中,Aurora MySQL 将使用隐式提交。自动提交已开启。这意味着每行插入都有一个提交。性能详情显示,连接的大部分时间都花在等待
io/aurora_redo_log_flush等待事件上。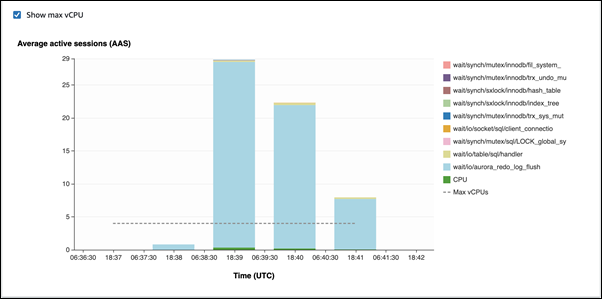
这是由于使用的简单插入语句造成的。
50000 条记录需要 3.5 分钟才能插入。
-
在第二个示例中,插入分 1000 个批次进行,也就是说每个连接执行 10 次提交,而不是 10000 次。性能详情显示,连接不会将大部分时间花在
io/aurora_redo_log_flush等待事件上。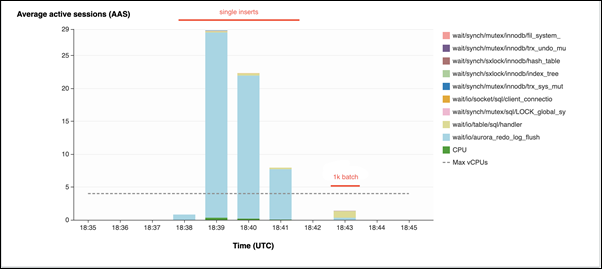
50000 条记录需要 4 秒钟才能插入。
操作
根据等待事件的原因,我们建议采取不同的操作。
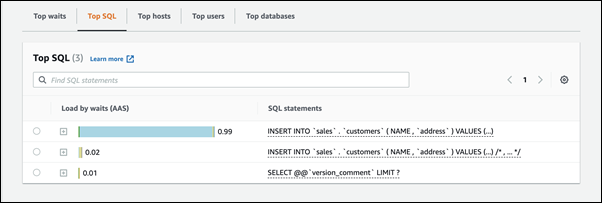
识别有问题的会话和查询
如果数据库实例遇到瓶颈,您的首要任务是查找导致瓶颈的会话和查询。对于有用 Amazon 数据库博客文章,请参阅利用性能详情分析 Amazon Aurora MySQL 工作负载
识别导致瓶颈的会话和查询
登录 Amazon Web Services 管理控制台 并通过以下网址打开 Amazon RDS 控制台:https://console.aws.amazon.com/rds/
。 -
在导航窗格中,选择性能详情。
-
选择您的数据库实例。
-
在 Database load(数据库负载)中,选择 Slice by wait(按等待切片)。
-
在页面底部,选择 Top SQL(主要 SQL)。
列表顶部的查询导致数据库负载最高。
对写入操作进行分组
以下示例会触发 io/aurora_redo_log_flush 等待事件。(自动提交已开启。)
INSERT INTO `sampleDB`.`sampleTable` (sampleCol2, sampleCol3) VALUES ('xxxx','xxxxx'); INSERT INTO `sampleDB`.`sampleTable` (sampleCol2, sampleCol3) VALUES ('xxxx','xxxxx'); INSERT INTO `sampleDB`.`sampleTable` (sampleCol2, sampleCol3) VALUES ('xxxx','xxxxx'); .... INSERT INTO `sampleDB`.`sampleTable` (sampleCol2, sampleCol3) VALUES ('xxxx','xxxxx'); UPDATE `sampleDB`.`sampleTable` SET sampleCol3='xxxxx' WHERE id=xx; UPDATE `sampleDB`.`sampleTable` SET sampleCol3='xxxxx' WHERE id=xx; UPDATE `sampleDB`.`sampleTable` SET sampleCol3='xxxxx' WHERE id=xx; .... UPDATE `sampleDB`.`sampleTable` SET sampleCol3='xxxxx' WHERE id=xx; DELETE FROM `sampleDB`.`sampleTable` WHERE sampleCol1=xx; DELETE FROM `sampleDB`.`sampleTable` WHERE sampleCol1=xx; DELETE FROM `sampleDB`.`sampleTable` WHERE sampleCol1=xx; .... DELETE FROM `sampleDB`.`sampleTable` WHERE sampleCol1=xx;
为了减少等待 io/aurora_redo_log_flush 等待事件所花费的时间,将写入操作按逻辑分组为单个提交,以减少对存储的持久调用。
关闭自动提交
在进行不在事务范围内的大型更改之前,请关闭自动提交,如以下示例所示。
SET SESSION AUTOCOMMIT=OFF; UPDATE `sampleDB`.`sampleTable` SET sampleCol3='xxxxx' WHERE sampleCol1=xx; UPDATE `sampleDB`.`sampleTable` SET sampleCol3='xxxxx' WHERE sampleCol1=xx; UPDATE `sampleDB`.`sampleTable` SET sampleCol3='xxxxx' WHERE sampleCol1=xx; .... UPDATE `sampleDB`.`sampleTable` SET sampleCol3='xxxxx' WHERE sampleCol1=xx; -- Other DML statements here COMMIT; SET SESSION AUTOCOMMIT=ON;
使用事务
您可使用事务,如以下示例所示。
BEGIN INSERT INTO `sampleDB`.`sampleTable` (sampleCol2, sampleCol3) VALUES ('xxxx','xxxxx'); INSERT INTO `sampleDB`.`sampleTable` (sampleCol2, sampleCol3) VALUES ('xxxx','xxxxx'); INSERT INTO `sampleDB`.`sampleTable` (sampleCol2, sampleCol3) VALUES ('xxxx','xxxxx'); .... INSERT INTO `sampleDB`.`sampleTable` (sampleCol2, sampleCol3) VALUES ('xxxx','xxxxx'); DELETE FROM `sampleDB`.`sampleTable` WHERE sampleCol1=xx; DELETE FROM `sampleDB`.`sampleTable` WHERE sampleCol1=xx; DELETE FROM `sampleDB`.`sampleTable` WHERE sampleCol1=xx; .... DELETE FROM `sampleDB`.`sampleTable` WHERE sampleCol1=xx; -- Other DML statements here END
使用批处理
您还可以对批处理进行更改,如以下示例所示。但是,使用过大的批处理可能会导致性能问题,尤其是在只读副本中或执行时间点恢复 (PITR) 时。
INSERT INTO `sampleDB`.`sampleTable` (sampleCol2, sampleCol3) VALUES ('xxxx','xxxxx'),('xxxx','xxxxx'),...,('xxxx','xxxxx'),('xxxx','xxxxx'); UPDATE `sampleDB`.`sampleTable` SET sampleCol3='xxxxx' WHERE sampleCol1 BETWEEN xx AND xxx; DELETE FROM `sampleDB`.`sampleTable` WHERE sampleCol1<xx;