监控 Amazon Aurora Global Database
当您创建构成 Aurora 全局数据库的 Aurora 数据库集群时,您可以选择许多选项来监控数据库集群的性能。这些选项包含以下内容:
Amazon RDS 性能详情 – 在底层 Aurora 数据库引擎中启用性能架构。要了解有关性能详情和 Aurora 全局数据库的更多信息,请参阅 使用 Amazon RDS 性能详情监控 Amazon Aurora Global Database。
增强监控 – 生成 CPU 上的进程或线程利用率的指标。要了解有关增强型监控的信息,请参阅使用增强监控来监控操作系统指标。
Amazon CloudWatch Logs – 将指定日志类型发布到 CloudWatch Logs。默认情况下会发布错误日志,但您可以选择特定于 Aurora 数据库引擎的其他日志。
对于基于 Aurora MySQL– 的 Aurora 数据库集群,您可以导出审核日志、常规日志和慢查询日志。
对于基于 Aurora PostgreSQL 的 Aurora 数据库集群,您可以导出 PostgreSQL 日志。
对于基于 Aurora MySQL 的全局数据库,您可以查询特定的
information_schema表来检查 Aurora 全局数据库及其实例的状态。要了解如何操作,请参阅监控基于 Aurora MySQL 的全局数据库。对于基于 Aurora PostgreSQL 的全局数据库,您可以使用特定的函数来检查 Aurora 全局数据库及其实例的状态。要了解如何操作,请参阅监控基于 Aurora PostgreSQL 的全局数据库。
以下屏幕截图显示了 Aurora 全局数据库中的主 Aurora 数据库集群的 Monitoring (监控) 选项卡上的一些可用选项。
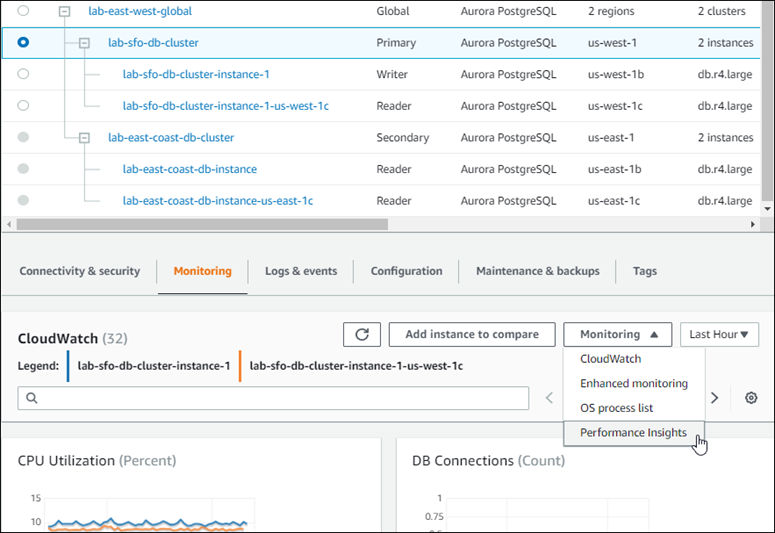
有关更多信息,请参阅 监控 Amazon Aurora 集群中的指标。
使用 Amazon RDS 性能详情监控 Amazon Aurora Global Database
您可以将 Amazon RDS 性能详情用于 Aurora 全局数据库。您可以为 Aurora 全局数据库中的每个数据 Aurora 库集群单独启用此特征。为此,您可以在 Create database (创建数据库) 页面的 Additional configuration (其他配置) 部分中选择 Enable Performance Insights (启用性能详情)。或者,您可以修改 Aurora 数据库集群,以便在其正常运行后使用此特征。您可以针对 Aurora 全局数据库中的每个集群启用或禁用性能详情功能。
性能详情创建的报告适用于全局数据库中的每个集群。在将新的辅助 Amazon Web Services 区域 添加到已在使用 Performance Insights 的 Aurora Global Database 时,确保在新添加的集群中启用 Performance Insights。此集群不能从现有全局数据库继承 Performance Insights 设置。
在查看附加到全局数据库的数据库实例的 Performance Insights 页面时,您可以切换 Amazon Web Services 区域。但是,您可能不能在切换 Amazon Web Services 区域 后立即看到性能信息。在各个 Amazon Web Services 区域 中,虽然数据库实例的名称可能会相同,但每个数据库实例的相关 Performance Insights URL 不同。在切换 Amazon Web Services 区域 后,可在 Performance Insights 导航窗格中重新选择数据库实例的名称。
对于与全局数据库关联的数据库实例,各 Amazon Web Services 区域 中影响性能的系数可能不同。例如,各 Amazon Web Services 区域 中数据库实例的容量可能不同。
要了解有关使用性能详情的更多信息,请参阅 在 Amazon Aurora 上使用性能详情监控数据库负载。
使用数据库活动流监控 Aurora Global Database
利用数据库活动流特征,您可以监控全局数据库中数据库集群的审计活动并为其设置告警。请分别在每个数据库集群上启动数据库活动流。每个集群在其自己的 Amazon Web Services 区域中将审计数据传送到其自己的 Kinesis 流。有关更多信息,请参阅 使用数据库活动流监控 Amazon Aurora。
监控基于 Aurora MySQL 的全局数据库
要查看基于 Aurora MySQL 的全局数据库的状态,请查询 information_schema.aurora_global_db_status 和 information_schema.aurora_global_db_instance_status 表。
注意
information_schema.aurora_global_db_status 和 information_schema.aurora_global_db_instance_status 表仅适用于 Aurora MySQL 版本 3.04.0 及更高版本和版本 8.4 及更高版本的全球数据库。
监控基于 Aurora MySQL 的全局数据库
-
使用 MySQL 客户端连接到全局数据库主集群端点。有关如何连接的更多信息,请参阅 连接到 Amazon Aurora Global Database。
-
在 mysql 命令中查询
information_schema.aurora_global_db_status表以列出主卷和辅助卷。此查询返回全局数据库辅助数据库集群的滞后时间,如以下示例所示。mysql> select * from information_schema.aurora_global_db_status;AWS_REGION | HIGHEST_LSN_WRITTEN | DURABILITY_LAG_IN_MILLISECONDS | RPO_LAG_IN_MILLISECONDS | LAST_LAG_CALCULATION_TIMESTAMP | OLDEST_READ_VIEW_TRX_ID -----------+---------------------+--------------------------------+------------------------+---------------------------------+------------------------ us-east-1 | 183537946 | 0 | 0 | 1970-01-01 00:00:00.000000 | 0 us-west-2 | 183537944 | 428 | 0 | 2023-02-18 01:26:41.925000 | 20806982 (2 rows)输出包含全局数据库的每个数据库集群行,其中包含以下列:
-
AWS_REGION – 此数据库集群所在的 Amazon Web Services 区域。有关按引擎列出 Amazon Web Services 区域的表,请参阅 区域可用性。
-
HIGHEST_LSN_WRITTEN – 当前在此数据库集群上写入的最高日志序列号(LSN)。
日志序列号 (LSN) 是标识数据库事务日志中的记录的唯一序列号。对 LSN 进行排序,以便较大的 LSN 表示较晚的事务。
-
DURABILITY_LAG_IN_MILLISECONDS – 辅助数据库集群上的
HIGHEST_LSN_WRITTEN与主数据库集群上的HIGHEST_LSN_WRITTEN之间的时间戳值差异。在 Aurora 全局数据库的主数据库集群上,该值始终为 0。 -
RPO_LAG_IN_MILLISECONDS – 恢复点目标(RPO)滞后。RPO 滞后是最近的用户事务在存储在 Aurora 全局数据库的主数据库集群上之后,执行 COMMIT 操作以便存储在辅助数据库集群上所需的时间。在 Aurora 全局数据库的主数据库集群上,该值始终为 0。
简而言之,该指标计算 Aurora 全局数据库中每个 Aurora MySQL 数据库集群的恢复点目标,也就是说,如果发生中断,可能会丢失多少数据。与滞后一样,RPO 是按时间计量的。
-
LAST_LAG_CALCULATION_TIMESTAMP – 最后为
DURABILITY_LAG_IN_MILLISECONDS和RPO_LAG_IN_MILLISECONDS计算值时指定的时间戳。时间值(如1970-01-01 00:00:00+00)表示这是主数据库集群。 -
OLDEST_READ_VIEW_TRX_ID – 写入器数据库实例可以清除到的最早事务的 ID。
-
-
查询
information_schema.aurora_global_db_instance_status表,以列出主数据库集群和辅助数据库集群的所有辅助数据库实例。mysql> select * from information_schema.aurora_global_db_instance_status;SERVER_ID | SESSION_ID | AWS_REGION | DURABLE_LSN | HIGHEST_LSN_RECEIVED | OLDEST_READ_VIEW_TRX_ID | OLDEST_READ_VIEW_LSN | VISIBILITY_LAG_IN_MSEC ---------------------+--------------------------------------+------------+-------------+----------------------+-------------------------+----------------------+------------------------ ams-gdb-primary-i2 | MASTER_SESSION_ID | us-east-1 | 183537698 | 0 | 0 | 0 | 0 ams-gdb-secondary-i1 | cc43165b-bdc6-4651-abbf-4f74f08bf931 | us-west-2 | 183537689 | 183537692 | 20806928 | 183537682 | 0 ams-gdb-secondary-i2 | 53303ff0-70b5-411f-bc86-28d7a53f8c19 | us-west-2 | 183537689 | 183537692 | 20806928 | 183537682 | 677 ams-gdb-primary-i1 | 5af1e20f-43db-421f-9f0d-2b92774c7d02 | us-east-1 | 183537697 | 183537698 | 20806930 | 183537691 | 21 (4 rows)输出包含全局数据库的每个数据库实例行,其中包含以下列:
-
SERVER_ID – 数据库实例的服务器标识符。
-
SESSION_ID – 当前会话的唯一标识符。
MASTER_SESSION_ID的值标识写入器(主要)数据库实例。 -
AWS_REGION – 此数据库实例所在的 Amazon Web Services 区域。有关按引擎列出 Amazon Web Services 区域的表,请参阅 区域可用性。
-
DURABLE_LSN – 存储中持久的 LSN。
-
HIGHEST_LSN_RECEIVED – 数据库实例从写入器数据库实例收到的最高 LSN。
-
OLDEST_READ_VIEW_TRX_ID – 写入器数据库实例可以清除到的最早事务的 ID。
-
OLDEST_READ_VIEW_LSN – 数据库实例从存储中读取所用的最早 LSN。
-
VISIBILITY_LAG_IN_MSEC – 对于主数据库集群中的读取器,此数据库实例滞后于写入器数据库实例的时间(以毫秒为单位)。对于辅助数据库集群中的读取器,此数据库实例滞后于辅助卷的时间(以毫秒为单位)。
-
要查看这些值如何随时间变化,请考虑以下事务块,其中表插入需要一个小时。
mysql> BEGIN;
mysql> INSERT INTO table1 SELECT Large_Data_That_Takes_1_Hr_To_Insert;
mysql> COMMIT;
在某些情况下,在 BEGIN 语句之后主数据库集群和辅助数据库集群之间的网络会断开连接。如果是这样,则辅助数据库集群的 DURABILITY_LAG_IN_MILLISECONDS 值开始增加。在 INSERT 语句结束时,DURABILITY_LAG_IN_MILLISECONDS 值为 1 小时。但是,RPO_LAG_IN_MILLISECONDS 值为 0,因为在主数据库集群和辅助数据库集群之间提交的所有用户数据仍然相同。一旦 COMMIT 语句完成,RPO_LAG_IN_MILLISECONDS 值就会增加。
监控基于 Aurora PostgreSQL 的全局数据库
要查看基于 Aurora PostgreSQL 的全局数据库的状态,请使用 aurora_global_db_status 和 aurora_global_db_instance_status 函数。
注意
仅 Aurora PostgreSQL 支持 aurora_global_db_status 和 aurora_global_db_instance_status 函数。
监控基于 Aurora PostgreSQL 的全局数据库
-
使用 PostgreSQL 实用工具(如 psql)连接到全局数据库主集群终端节点。有关如何连接的更多信息,请参阅 连接到 Amazon Aurora Global Database。
-
在 psql 命令中使用
aurora_global_db_status函数列出主卷和辅助卷。这显示全局数据库辅助数据库集群的滞后时间。postgres=> select * from aurora_global_db_status();aws_region | highest_lsn_written | durability_lag_in_msec | rpo_lag_in_msec | last_lag_calculation_time | feedback_epoch | feedback_xmin ------------+---------------------+------------------------+-----------------+----------------------------+----------------+--------------- us-east-1 | 93763984222 | -1 | -1 | 1970-01-01 00:00:00+00 | 0 | 0 us-west-2 | 93763984222 | 900 | 1090 | 2020-05-12 22:49:14.328+00 | 2 | 3315479243 (2 rows)输出包含全局数据库的每个数据库集群行,其中包含以下列:
-
aws_region - 此数据库集群所在的 Amazon Web Services 区域。有关按引擎列出 Amazon Web Services 区域的表,请参阅 区域可用性。
-
highest_lsn_written – 当前在此数据库集群上写入的最高日志序列号 (LSN)。
日志序列号 (LSN) 是标识数据库事务日志中的记录的唯一序列号。对 LSN 进行排序,以便较大的 LSN 表示较晚的事务。
-
durability_lag_in_msec – 辅助数据库集群上写入的最高日志序列号 (
highest_lsn_written) 与主数据库集群上的highest_lsn_written之间的时间戳差异。 -
rpo_lag_in_msec – 恢复点目标 (RPO) 滞后。此滞后是存储在辅助数据库集群上的最新用户事务提交与存储在主数据库集群上的最新用户事务提交之间的时差。
-
last_lag_calculation_time – 最后为
durability_lag_in_msec和rpo_lag_in_msec计算值的时间戳。 -
feedback_epoch – 辅助数据库集群在生成热备用服务器信息时使用的纪元。
热备用 是指在服务器处于恢复或备用模式时,数据库集群可以进行连接和查询。热备用反馈是有关处于热备用状态的数据库集群的信息。有关更多信息,请参阅 PostgreSQL 文档中的热备用
。 -
feedback_xmin – 辅助数据库集群使用的最小(最早)活动事务 ID。
-
-
使用
aurora_global_db_instance_status函数列出主数据库集群和辅助数据库集群的所有辅助数据库实例。postgres=> select * from aurora_global_db_instance_status();server_id | session_id | aws_region | durable_lsn | highest_lsn_rcvd | feedback_epoch | feedback_xmin | oldest_read_view_lsn | visibility_lag_in_msec --------------------------------------------+--------------------------------------+------------+-------------+------------------+----------------+---------------+----------------------+------------------------ apg-global-db-rpo-mammothrw-elephantro-1-n1 | MASTER_SESSION_ID | us-east-1 | 93763985102 | | | | | apg-global-db-rpo-mammothrw-elephantro-1-n2 | f38430cf-6576-479a-b296-dc06b1b1964a | us-east-1 | 93763985099 | 93763985102 | 2 | 3315479243 | 93763985095 | 10 apg-global-db-rpo-elephantro-mammothrw-n1 | 0d9f1d98-04ad-4aa4-8fdd-e08674cbbbfe | us-west-2 | 93763985095 | 93763985099 | 2 | 3315479243 | 93763985089 | 1017 (3 rows)输出包含全局数据库的每个数据库实例行,其中包含以下列:
-
server_id – 数据库实例的服务器标识符。
-
session_id – 当前会话的唯一标识符。
-
aws_region - 此数据库实例所在的 Amazon Web Services 区域。有关按引擎列出 Amazon Web Services 区域的表,请参阅 区域可用性。
-
durable_lsn – 存储中持久的 LSN。
-
highest_lsn_rcvd – 数据库实例从写入器数据库实例收到的最高 LSN。
-
feedback_epoch – 数据库实例在生成热备用信息时使用的纪元。
热备用服务器是指在服务器处于恢复或备用模式时,数据库实例可以进行连接和查询。热备用反馈是有关处于热备用状态的数据库实例的信息。有关更多信息,请参阅有关热备用
的 PostgreSQL 文档。 -
feedback_xmin – 数据库实例使用的最小(最早)活动事务 ID。
-
oldest_read_view_lsn – 数据库实例用于从存储中读取的最早 LSN。
-
visibility_lag_in_msec – 此数据库实例落后于写入器数据库实例的程度。
-
要查看这些值如何随时间变化,请考虑以下事务块,其中表插入需要一个小时。
psql> BEGIN;
psql> INSERT INTO table1 SELECT Large_Data_That_Takes_1_Hr_To_Insert;
psql> COMMIT;在某些情况下,在 BEGIN 语句之后主数据库集群和辅助数据库集群之间的网络会断开连接。如果是这样,辅助数据库集群的 durability_lag_in_msec 值开始增加。在 INSERT 语句的末尾,durability_lag_in_msec 值为 1 小时。但是,rpo_lag_in_msec 值为 0,因为在主数据库集群和辅助数据库集群之间提交的所有用户数据仍然相同。在 COMMIT 语句完成后,rpo_lag_in_msec 值会立即增加。