创建 Babelfish for Aurora PostgreSQL 数据库集群
所有支持的 Aurora PostgreSQL 版本、13 及更高版本均支持适用于 Aurora PostgreSQL 的 Babelfish。
您可以通过 Amazon Web Services 管理控制台 或 Amazon CLI,使用 Babelfish 创建 Aurora PostgreSQL 集群。
注意
在 Aurora PostgreSQL 集群中,系统会为 Babelfish 预留 babelfish_db 数据库名称。在 Babelfish for Aurora PostgreSQL 上自行创建名为 babelfish_db 的数据库会阻止 Aurora 成功预置 Babelfish。
在使用 Amazon Web Services 管理控制台 运行 Babelfish 的情况下创建一个集群
-
从 https://console.aws.amazon.com/rds/
打开 Amazon RDS 控制台,然后选择 Create database(创建数据库)。 
-
对于选择数据库创建方法,请执行以下操作之一:
-
要指定详细的引擎选项,请选择 Standard create(标准创建)。
-
要使用支持 Aurora 集群最佳实践的预配置选项,请选择 Easy create(轻松创建)。
-
-
对于引擎类型,选择 Aurora(PostgreSQL 兼容)。
-
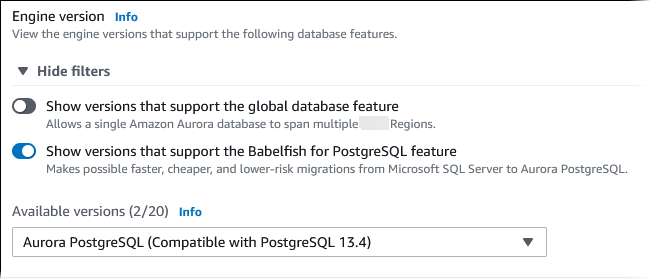
对于可用的版本,选择一个 Aurora PostgreSQL 版本。要获得最新的 Babelfish 功能,请选择最高的 Aurora PostgreSQL 主要版本。所有支持的 Aurora PostgreSQL 版本、13 及更高版本均支持 Babelfish。
-
对于 Templates(模板),选择与您的使用案例匹配的模板。
-
对于数据库集群标识符,输入稍后可以在数据库集群列表中轻松找到的名称。
-
对于主用户名中,输入管理员用户名。Aurora PostgreSQL 的原定设置值为
postgres。您可以接受原定设置,也可以选择其他名称。例如,要遵循 SQL Server 数据库中使用的命名约定,可以为主用户名输入sa(系统管理员)。如果您在此时尚未创建名为
sa的用户,您可以稍后用自己选择的客户端创建一个。创建用户后,使用ALTER SERVER ROLE命令将其添加到集群的sysadmin组(角色)。警告
主用户名必须始终使用小写字符,否则数据库集群将无法通过 TDS 端口连接到 Babelfish。
-
对于 Master password(主密码),创建一个强密码并确认密码。
-
对于接下来的选项,指定数据库集群设置,直到 Babelfish 设置部分。有关每项设置的信息,请参阅Aurora 数据库集群的设置。
-
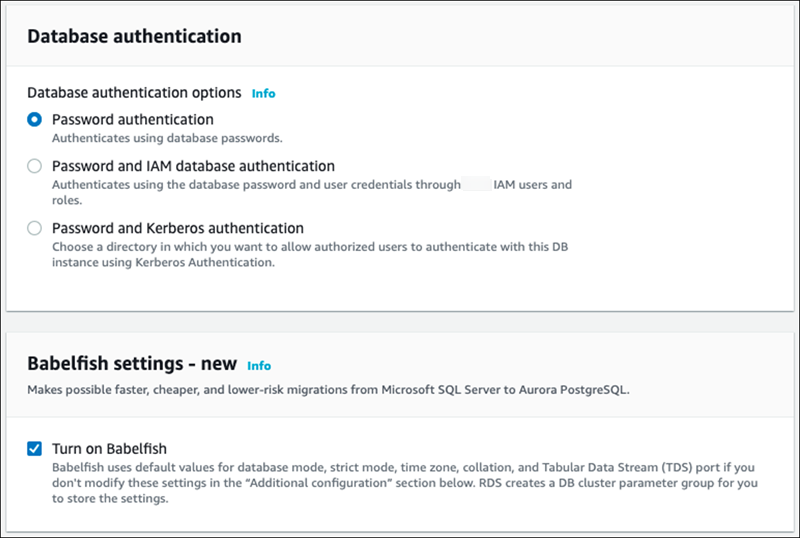
要使 Babelfish 功能可用,请选择 Turn on Babelfish(打开 Babelfish)框。
-
对于数据库集群参数组,请执行以下操作之一:
-
选择 Create new(新建)以在打开 Babelfish 的情况下创建新的参数组。
-
选择 Choose existing(选择现有)以使用现有的参数组。如果您使用现有组,请确保在创建集群之前修改组并为 Babelfish 参数添加值。有关 Babelfish 参数的信息,请参阅 Babelfish 的数据库集群参数组设置。
如果您使用现有组,请在后面的框中提供组名称。
-
-
对于 Database migration mode(数据库迁移模式),请选择下列选项之一:
-
单个数据库,可迁移单个 SQL Server 数据库。
在某些情况下,您可能会同时迁移多个用户数据库,最终目标是在没有 Babelfish 的情况下完全迁移到本机 Aurora PostgreSQL。如果最终的应用程序需要整合架构(单个
dbo架构),请确保首先将 SQL Server 数据库整合到单个 SQL Server 数据库中。然后使用单个数据库模式迁移到 Babelfish。 -
多个数据库,迁移多个 SQL Server 数据库(源自单个 SQL Server 安装)。多数据库模式不会合并不源于单个 SQL Server 安装的多个数据库。有关迁移多个数据库的信息,请参阅 将 Babelfish 与单个数据库或多个数据库结合使用。
注意
从 Aurora PostgreSQL 16 版本起,默认选择多数据库作为数据库迁移模式。

-
-
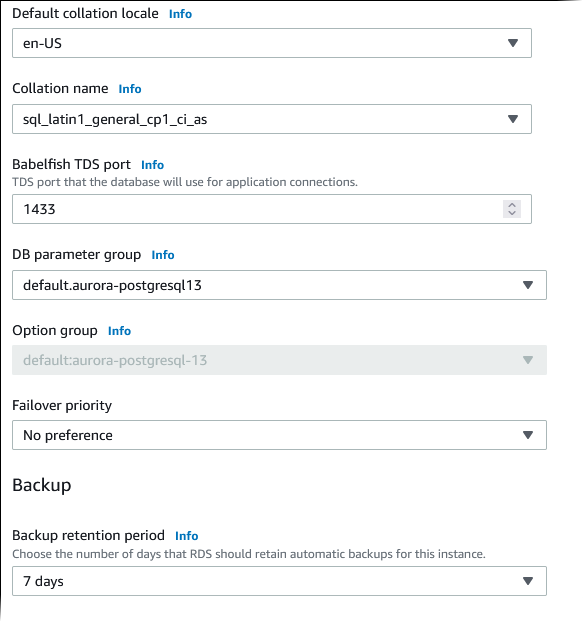
对于 Default collation locale(原定设置排序规则区域设置),输入您的服务器区域设置。默认值为
en-US。有关排序规则的详细信息,请参阅 了解适用于 Aurora PostgreSQL 的 Babelfish 中的排序规则。 -
对于 Collation name(排序规则名称)字段,输入原定设置排序规则。默认值为
sql_latin1_general_cp1_ci_as。有关详细信息,请参阅 了解适用于 Aurora PostgreSQL 的 Babelfish 中的排序规则。 -
对于数据库参数组,选择一个参数组或使用原定设置使用 Aurora 为您创建一个新组。
-
对于 Failover priority(故障转移优先级),选择实例的故障转移优先级。如果您未选择值,则原定设置值为
tier-1。此优先级决定在主实例故障恢复时提升 副本的顺序。有关更多信息,请参阅 Aurora 数据库集群的容错能力。 -
对于 Backup retention period(备份保留期),选择 Aurora 保留数据库的备份副本的时间长度(1–35 天)。您可使用备份副本对数据库执行时间点还原 (PITR),精度可到秒。原定设置的保留期为七天。
-
选择 Copy tags to snapshots(将标签复制到快照)以在创建快照时将任何数据库实例标签复制到数据库快照。
注意
当从快照还原数据库集群时,该集群不会还原为适用于 Aurora PostgreSQL 的 Babelfish 数据库集群。您需要开启用于控制数据库集群参数组中 Babelfish 首选项的参数,才能再次启用 Babelfish。有关 Babelfish 参数的更多信息,请参阅 Babelfish 的数据库集群参数组设置。
-
请选择 Enable encryption(启用加密)以对该数据库集群开启静态加密(Aurora 存储加密)。
-
选择 Enable Performance Insights(启用性能详情)打开 Amazon RDS 性能详情。
-
选择 Enable Enhanced monitoring(启用增强监控)以开始您的数据库集群在其上运行的操作系统的实时指标收集。
-
选择 PostgreSQL 日志将日志文件发布到 Amazon CloudWatch Logs。
-
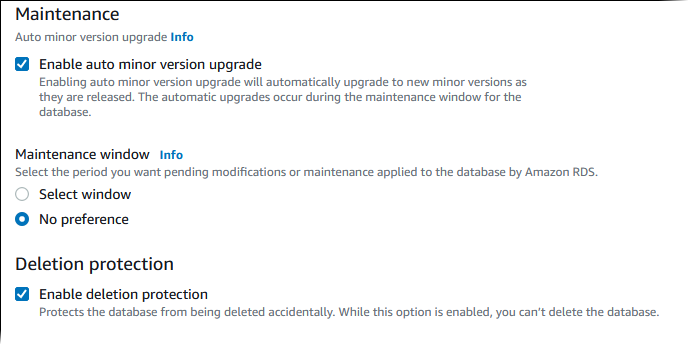
选择 Enable auto minor version upgrade(启用自动次要版本升级)在次要版本升级可用时自动更新 Aurora 数据库集群。
-
对于维护时段,请执行以下操作:
-
要选择 Amazon RDS 进行修改或执行维护的时间,请选择 Select window(选择时段)。
-
要在计划外的时间执行 Amazon RDS 维护,请选择 No preference(无首选项)。
-
-
选择 Enable deletion protection(启用删除保护)框以保护您的数据库免于意外删除。
如果启用此功能,则无法直接删除数据库。相反,在删除数据库之前,您需要修改数据库集群并关闭此功能。
-
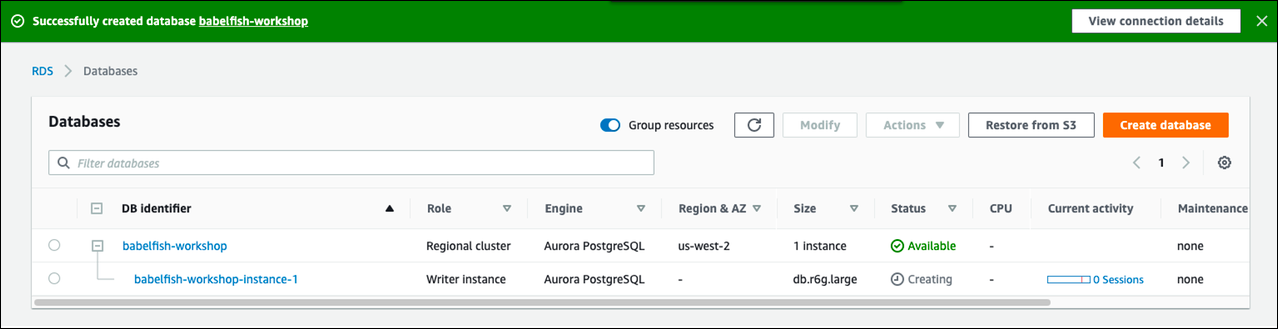
选择创建数据库。
您可以在 Databases(数据库)列表中找到为 Babelfish 设置的新数据库。Status(状态)列在部署完成时显示 Available(可用)。
当您使用 Amazon CLI 创建 Babelfish for Aurora PostgreSQL 时,您需要向命令传递要用于集群的数据库集群参数组的名称。有关更多信息,请参阅 数据库集群先决条件。
在您可以使用 Amazon CLI 创建具有 Babelfish 的 Aurora PostgreSQL 集群之前,请执行以下操作:
-
在 Amazon Aurora 终端节点和配额中,从服务列表中选择端点 URL。
-
创建集群的参数组。有关参数组的更多信息,请参阅 Amazon Aurora 的参数组。
-
修改参数组,添加打开 Babelfish 的参数。
要使用 Amazon CLI 创建带有 Babelfish 的 Aurora PostgreSQL 数据库集群
下面的示例使用原定设置的主用户名 postgres。根据需要替换您为数据库集群创建的用户名(例如 sa),或当您不接受原定设置时选择的任何用户名。
-
创建参数组。
对于 Linux、macOS 或 Unix:
aws rds create-db-cluster-parameter-group \ --endpoint-urlendpoint-url\ --db-cluster-parameter-group-nameparameter-group\ --db-parameter-group-familyaurora-postgresql14\ --description"description"对于:Windows
aws rds create-db-cluster-parameter-group ^ --endpoint-urlendpoint-URL^ --db-cluster-parameter-group-nameparameter-group^ --db-parameter-group-familyaurora-postgresql14^ --description"description" -
修改参数组以打开 Babelfish。
对于 Linux、macOS 或 Unix:
aws rds modify-db-cluster-parameter-group \ --endpoint-urlendpoint-url\ --db-cluster-parameter-group-nameparameter-group\ --parameters "ParameterName=rds.babelfish_status,ParameterValue=on,ApplyMethod=pending-reboot"对于:Windows
aws rds modify-db-cluster-parameter-group ^ --endpoint-urlendpoint-url^ --db-cluster-parameter-group-nameparamater-group^ --parameters "ParameterName=rds.babelfish_status,ParameterValue=on,ApplyMethod=pending-reboot" -
为新的数据库集群指定数据库子网组和 Virtual Private Cloud (VPC) 安全组 ID,然后调用 create-db-cluster 命令。
对于 Linux、macOS 或 Unix:
aws rds create-db-cluster \ --db-cluster-identifiercluster-name\ --master-usernamepostgres\ --manage-master-user-password \ --engine aurora-postgresql \ --engine-version14.3\ --vpc-security-group-idssecurity-group\ --db-subnet-group-namesubnet-group-name\ --db-cluster-parameter-group-nameparameter-group对于:Windows
aws rds create-db-cluster ^ --db-cluster-identifiercluster-name^ --master-usernamepostgres^ --manage-master-user-password ^ --engine aurora-postgresql ^ --engine-version14.3^ --vpc-security-group-idssecurity-group^ --db-subnet-group-namesubnet-group^ --db-cluster-parameter-group-nameparameter-group此示例指定了生成主用户密码并在 Secrets Manager 中对其进行管理的
--manage-master-user-password选项。有关更多信息,请参阅 使用 Amazon Aurora 和 Amazon Secrets Manager 管理密码。或者,您可以使用--master-password选项自行指定和管理密码。 -
显式为数据库集群主实例。调用 create-db-instance 命令时,将您在步骤 3 中创建的集群名称用于
--db-cluster-identifier参数,如下所示。对于 Linux、macOS 或 Unix:
aws rds create-db-instance \ --db-instance-identifierinstance-name\ --db-instance-classdb.r6g\ --db-subnet-group-namesubnet-group\ --db-cluster-identifiercluster-name\ --engine aurora-postgresql对于:Windows
aws rds create-db-instance ^ --db-instance-identifierinstance-name^ --db-instance-classdb.r6g^ --db-subnet-group-namesubnet-group^ --db-cluster-identifiercluster-name^ --engine aurora-postgresql