Aurora PostgreSQL Limitless Database 中的分布式死锁
在数据库分片组中,分布在不同路由器和分片之间的事务之间可能会发生死锁。例如,运行跨两个分片的两个并发分布式事务,如下图所示。
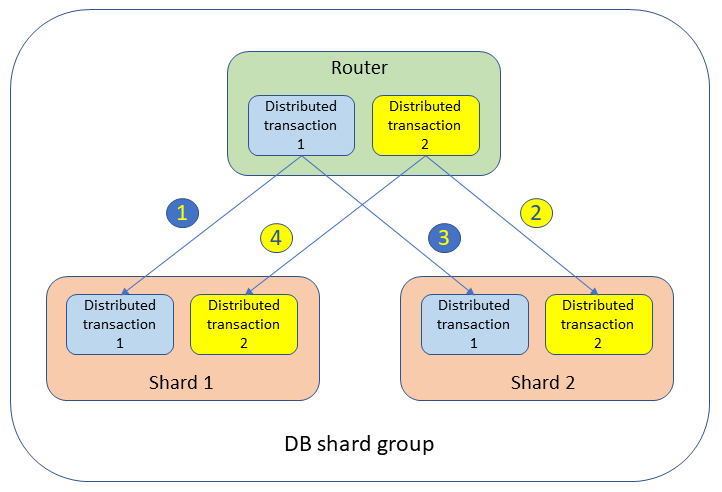
事务会锁定表并在两个分片中创建等待事件,如下所示:
-
分布式事务 1:
UPDATEtableSETvalue= 1 WHERE key = 'shard1_key';这会锁定分片 1。
-
分布式事务 2:
UPDATEtableSETvalue= 2 WHERE key = 'shard2_key';这会锁定分片 2。
-
分布式事务 1:
UPDATEtableSETvalue= 3 WHERE key = 'shard2_key';分布式事务 1 正在等待分片 2。
-
分布式事务 2:
UPDATEtableSETvalue= 4 WHERE key = 'shard1_key';分布式事务 2 正在等待分片 1。
在这种情况下,分片 1 和分片 2 都看不到问题:事务 1 在等待分片 2 上的事务 2,而事务 2 在等待分片 1 上的事务 1。从全局角度来看,事务 1 在等待事务 2,事务 2 在等待事务 1。两个不同分片上的两个事务互相等待的情况称为分布式死锁。
Aurora PostgreSQL Limitless Database 可以自动检测和解决分布式死锁。当事务等待获取资源的时间过长时,数据库分片组中的路由器会收到通知。接收通知的路由器开始从数据库分片组中的所有路由器和分片收集必要的信息。然后,路由器会继续结束参与分布式死锁的事务,直到数据库分片组中的其余事务可以在不被彼此阻止的情况下继续进行。
当您的事务是分布式死锁的一部分并由路由器结束时,您会收到以下错误:
ERROR: aborting transaction participating in a distributed deadlock
rds_aurora.limitless_distributed_deadlock_timeout 数据库集群参数设置每个事务在通知路由器检查分布式死锁之前等待资源的时间。如果您的工作负载不太容易出现死锁情况,则可以增加该参数值。默认值为 1000 毫秒(1 秒)。
当发现并解决跨节点死锁时,分布式死锁周期将发布到 PostgreSQL 日志中。死锁中每个进程的信息包括以下内容:
-
启动事务的协调器节点
-
协调器节点上事务的虚拟事务 ID(xid),格式为
backend_id/backend_local_xid -
事务的分布式会话 ID