Aurora 零 ETL 集成
Aurora 与 Amazon Redshift 和 Amazon SageMaker AI 的零 ETL 集成支持使用 Aurora 中的数据进行近乎实时的分析和机器学习(ML)。这是一个完全托管式解决方案,用于在将事务数据写入 Aurora 数据库集群后,使这些数据在分析目标中可用。提取、转换、加载(ETL)是将来自多个来源的数据合并到一个大型中央数据仓库的过程。
借助零 ETL 集成,Aurora 数据库集群中的数据可在 Amazon Redshift 或 Amazon SageMaker AI 智能湖仓中以近乎实时的方式使用。一旦这些数据进入目标数据仓库或数据湖中,您就可以使用各种内置功能为分析、机器学习和人工智能工作负载提供支持,例如机器学习、实体化视图、数据共享、对多个数据存储和数据湖的联合访问,以及与 Amazon SageMaker AI、Quick 及其他 Amazon Web Services 服务的集成。
要创建零 ETL 集成,您需要将 Aurora 数据库集群指定为源,并将支持的数据仓库或智能湖仓指定为目标。该集成会将数据从源数据库复制到目标数据仓库或智能湖仓中。
下图展示了这项与 Amazon Redshift 进行零 ETL 集成的功能:


下图展示了这项与 Amazon SageMaker AI 智能湖仓进行零 ETL 集成的功能:
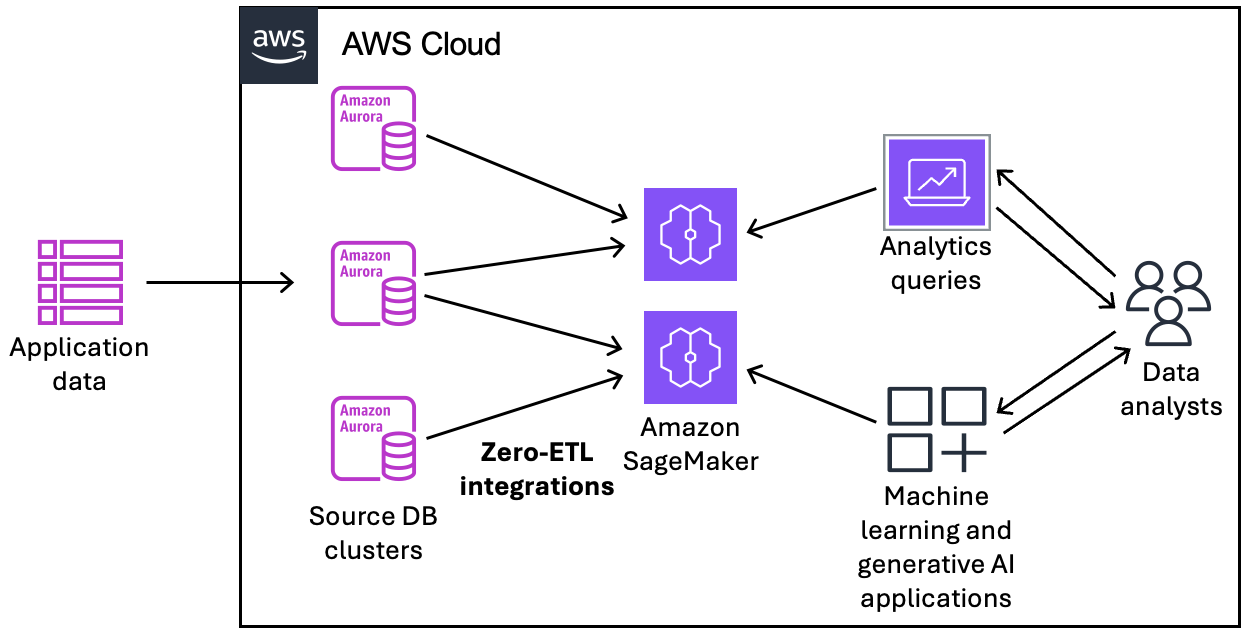
该集成还会监控数据管道的运行状况,并在可能的情况下从问题中恢复。您可以创建多个 Aurora 数据库集群与单个目标数据仓库或智能湖仓的集成,从而使您能够获得跨多个应用程序的全面洞察。
有关零 ETL 集成的定价的更多信息,请参阅 Amazon Aurora 定价
主题
优势
Aurora 零 ETL 集成具有以下好处:
-
帮助您从多个数据来源获得整体见解。
-
无需构建和维护执行提取、转换、加载(ETL)操作的复杂数据管道。零 ETL 集成通过为您预调配和管理管道来消除构建和管理管道所带来的挑战。
-
减少运营负担和成本,让您专注于改进应用程序。
-
让您利用目标目的地的分析和机器学习功能,从事务数据和其它数据中获得见解,从而有效地应对关键的、时间敏感的事件。
重要概念
在开始使用零 ETL 集成时,请考虑以下概念:
- 集成
-
完全托管式数据管道,可自动将事务数据和架构从 Aurora 数据库集群复制到数据仓库或目录。
- 源数据库集群
-
从中复制数据的 Aurora 数据库集群。可以指定一个使用预调配数据库实例或 Aurora serverless 数据库实例作为源的数据库集群。
- Target
-
要将数据复制到的数据仓库或智能湖仓。有两种类型的数据仓库:预调配集群数据仓库和无服务器数据仓库。预调配集群数据仓库是一个由称作节点的各种计算资源构成的集合,这些节点已整理到名为集群的组中。无服务器数据仓库由存储计算资源的工作组和存放数据库对象和用户的命名空间组成。这两个数据仓库都运行分析引擎并包含一个或多个数据库。
目标智能湖仓由目录、数据库、表和视图组成。有关智能湖仓架构的更多信息,请参阅《Amazon SageMaker AI Unified Studio User Guide》中的 SageMaker Lakehouse components。
多个源数据库集群可以写入同一个目标。
有关更多信息,请参阅《Amazon Redshift 开发人员指南》中的数据仓库系统架构。
限制
以下限制适用于 Aurora 零 ETL 集成。
一般限制
-
源数据库集群必须与目标位于同一区域。
-
如果集群已有集成,则无法重命名数据库集群或其任何实例。
-
不能在相同的源数据库和目标数据库之间创建多个集成。
-
您无法删除已有集成的数据库集群。您必须先删除所有关联的集成。
-
如果您停止源数据库集群,则在恢复集群之前,可能不会将最后几个事务复制到目标。
-
如果您的集群是蓝绿部署的源,则在切换期间,蓝色和绿色环境无法具有现有的零 ETL 集成。您必须先删除集成,接着切换,然后重新创建集成。
-
一个数据库集群必须至少包含一个数据库实例才能成为集成的来源。
-
您无法为本身是跨账户克隆的源数据库集群创建集成,例如使用 Amazon Resource Access Manager(Amazon RAM)共享的集群。
-
如果源集群是 Aurora 全局数据库中的主数据库集群,并且它故障转移到其中的一个辅助集群,则集成将变为非活动状态。您必须删除并重新创建集成。
-
如果源数据库正在积极创建另一个集成,则无法为其创建集成。
-
最初创建集成或重新同步表时,从源到目标的数据做种可能需要 20-25 分钟或更长时间,具体取决于源数据库的大小。这种延迟可能导致副本滞后延长。
-
某些数据类型不支持。有关更多信息,请参阅 Aurora 和 Amazon Redshift 数据库之间的数据类型差异。
-
系统表、临时表和视图不会复制到目标仓库。
-
对源表执行 DDL 命令(例如
ALTER TABLE)可能会触发表重新同步,从而使表在重新同步时无法用于查询。有关更多信息,请参阅 我的一个或多个 Amazon Redshift 表需要重新同步。
Aurora MySQL 限制
-
源数据库集群必须运行受支持的 Aurora MySQL 版本。有关受支持的版本的列表,请参阅 支持零 ETL 集成的区域和 Aurora 数据库引擎。
-
零 ETL 集成依赖于 MySQL 二进制日志(binlog)来捕获持续数据更改。请勿使用基于二进制日志的数据筛选,因为这可能会导致源数据库和目标数据库之间的数据不一致。
-
零 ETL 集成仅适用于配置为使用 InnoDB 存储引擎的数据库。
-
不支持带有预定义表更新的外键引用。具体而言,
CASCADE、SET NULL和SET DEFAULT操作不支持ON DELETE和ON UPDATE规则。尝试使用对另一个表的此类引用创建或更新表会使该表进入失败状态。 -
在源数据库集群上执行的 XA 事务
会导致集成进入 Syncing状态。
Aurora PostgreSQL 限制
-
源数据库集群必须运行受支持的 Aurora PostgreSQL 版本。有关受支持的版本的列表,请参阅 支持零 ETL 集成的区域和 Aurora 数据库引擎。
-
如果选择 Aurora PostgreSQL 源数据库集群,则必须至少指定一种数据筛选条件模式。该模式必须至少包含一个数据库 (
database-name.*.* -
在源 Aurora PostgreSQL 数据库集群中创建的所有数据库都必须使用 UTF-8 编码。
-
使用声明式分区时,表分区将被复制到 Amazon Redshift。但是,分区表本身不会复制到 Amazon Redshift。
-
不支持两阶段事务
。 -
如果从作为集成源的数据库集群中删除所有数据库实例,然后重新添加数据库实例,则源集群和目标集群之间的复制会中断。
-
源数据库集群无法使用 Aurora Limitless Database。
-
数据筛选器中存在的所有表都需要主键。任何没有主键的表都将进入失败状态。
Amazon Redshift 限制
有关与零 ETL 集成相关的 Amazon Redshift 限制的列表,请参阅《Amazon Redshift 管理指南》中的将零 ETL 集成与 Amazon Redshift 结合使用时的注意事项。
Amazon SageMaker AI 智能湖仓限制
以下是 Amazon SageMaker AI 智能湖仓零 ETL 集成的限制。
-
目录名称的长度限制为 19 个字符。
配额
您的账户有以下与 Aurora 零 ETL 集成相关的限额。除非另行指定,否则每个限额将基于区域。
| 名称 | 默认值 | 说明 |
|---|---|---|
| 集成 | 100 | Amazon Web Services 账户内的集成总数。 |
| 每个目标的集成数 | 50 | 向单个目标数据仓库或智能湖仓发送数据的集成数量。 |
| 每个源集群的集成数量 | 5 | 从单个源数据库集群发送数据的集成数量。 |
此外,目标仓库对每个数据库实例或集群节点中支持的表数量设置了某些限制。有关 Amazon Redshift 配额和限制的更多信息,请参阅《Amazon Redshift 管理指南》中的 Amazon Redshift 中的配额和限制。
支持的区域
Aurora 零 ETL 集成在 Amazon Web Services 区域的一个子集中提供。有关受支持区域的列表,请参阅。支持零 ETL 集成的区域和 Aurora 数据库引擎