监控只读复制
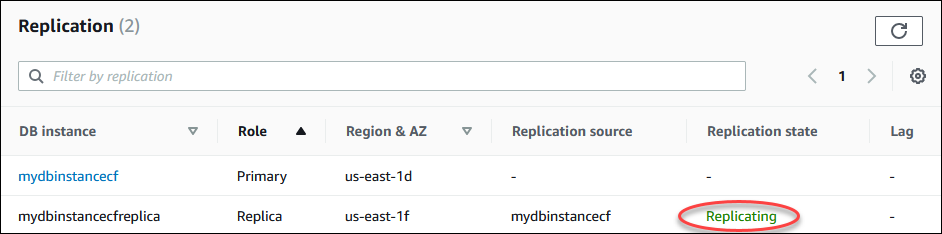
您可以通过几个方法监控只读副本的状态。Amazon RDS 控制台在只读副本详细信息的 Connectivity & security(连接和安全)选项卡的 Replication(复制)部分中显示只读副本的状态。要查看只读副本的详细信息,请在 Amazon RDS 控制台的数据库实例列表中选择该只读副本的名称。
您还可以使用 Amazon CLIdescribe-db-instances 命令或 Amazon RDS API DescribeDBInstances 操作查看只读副本的状态。
只读副本的状态可以是以下某项:
-
正在复制 – 正在成功地复制只读副本。
-
复制已降级(仅 SQL Server 和 PostgreSQL)– 副本从主实例接收数据,但一个或多个数据库可能无法获取更新。例如,当副本正在设置新创建的数据库时,可能会发生这种情况。当在蓝绿部署的蓝色环境中进行不支持的 DDL 或大型对象更改时,也可能发生这种情况。
除非在降级状态期间发生错误,否则状态不会从
replication degraded转换为error。 -
错误 – 复制出错。检查 Amazon RDS 控制台中的复制错误字段或事件日志以确定具体错误。有关复制错误故障诊断的详细信息,请参阅 排查 MySQL 只读副本问题。
-
已终止(仅限 MariaDB、MySQL 或 PostgreSQL) – 复制已终止。如果复制连续终止超过 30 天,不论是手动还是由于复制错误,都将会出现这种情况。在这种情况下,Amazon RDS 会终止主数据库实例和所有只读副本之间的复制。Amazon RDS 这样做是为了防止源数据库实例上的存储需求增长以及长失效转移时间。
复制中断可能影响存储,因为日志的大小和数量可能因向日志写入大量错误消息而增大。复制中断还可能影响故障恢复,因为 Amazon RDS 在恢复期间需要一段时间来维护和处理大量日志。
-
terminated(已终止)(仅限 Oracle) – 复制已终止。如果复制因只读副本上没有剩下足够的存储空间而停止超过 8 小时,就会发生这种情况。在这种情况下,Amazon RDS 会终止主数据库实例与受影响只读副本之间的复制。此状态为最终状态,必须重新创建只读副本。
-
已停止(仅限 MariaDB 或 MySQL) – 复制已因客户发起请求而停止。
-
复制停止点设置(仅限 MySQL) – 使用mysql.rds_start_replication_until存储过程设置客户启动的停止点,并且正在进行复制。
-
达到复制停止点(仅限 MySQL) – 使用mysql.rds_start_replication_until存储过程设置客户启动的停止点,并且复制已停止(因为已达到停止点)。
您可以查看到数据库实例的复制位置,如果是,请检查其复制状态。在 RDS 控制台的数据库页面上,它在角色列中显示主要。选择其数据库实例名称。在详细信息页面的连接性和安全性选项卡上,其复制状态位于复制下。
监控复制滞后
您可以通过查看 Amazon RDS ReplicaLag 指标,在 Amazon CloudWatch 中监控复制滞后。
对于 Db2,ReplicaLag 指标是已落后的数据库的最大滞后秒数。例如,如果两个数据库分别滞后 5 秒和 10 秒,则 ReplicaLag 为 10 秒。没有可用高可用性灾难恢复(HADR)状态的数据库不包括在计算中。
对于 MariaDB 和 MySQL,ReplicaLag 指标报告 Seconds_Behind_Master 命令的 SHOW REPLICA STATUS 字段的值。MySQL 和 MariaDB 的复制滞后的常见原因如下所示:
-
网络中断。
-
向只读副本上带索引的表写入。如果只读副本上的
read_only参数未设置为 0,它可以中断复制。 -
使用 MyISAM 等非事务性存储引擎。只有 MySQL 上 InnoDB 存储引擎和 MariaDB 上的 XtraDB 存储引擎支持复制。
注意
以前的 MariaDB 版本使用的是 SHOW SLAVE STATUS,而不是 SHOW REPLICA STATUS。如果您使用的 MariaDB 版本低于 10.5,请使用 SHOW SLAVE STATUS。
当 ReplicaLag 指标达到 0 时,即表示副本已赶上主数据库实例进度。如果 ReplicaLag 指标返回 -1,则当前未激活复制。ReplicaLag = -1 等效于 Seconds_Behind_Master = NULL。
对于 Oracle,ReplicaLag 指标是以下项的总和:Apply
Lag 值加上当前时间和应用滞后的 DATUM_TIME 值之间的差。DATUM_TIME 值是只读副本从其源数据库实例收到数据的最后时间。有关更多信息,请参阅 Oracle 文档中的V$DATAGUARD_STATS
对于 SQL Server,ReplicaLag 指标是已落后数据库的最大滞后秒数。例如,如果您有两个数据库分别滞后 5 秒和 10 秒,则 ReplicaLag 为 10 秒。ReplicaLag 指标返回以下查询的值。
SELECT MAX(secondary_lag_seconds) max_lag FROM sys.dm_hadr_database_replica_states;
有关更多信息,请参阅 Microsoft 文档中的 secondary_lag_seconds
如果 RDS 无法确定滞后,例如在副本安装期间或只读副本处于 ReplicaLag 状态时,则 -1 返回 error。
注意
只有当新数据库在只读副本上可供访问之后,才会将其包含在延迟计算中。
对于 PostgreSQL, ReplicaLag 指标返回以下查询的值。
SELECT extract(epoch from now() - pg_last_xact_replay_timestamp()) AS reader_lag
PostgreSQL 9.5.2 版及更高版本使用物理复制槽来管理源实例上的提前写入日志 (WAL) 保留。对于每个跨区域只读副本实例,Amazon RDS 创建一个物理复制槽并将它与实例关联。两个 Amazon CloudWatch 指标、Oldest Replication Slot Lag 和 Transaction
Logs Disk Usage 表示最滞后的副本(依据接收到的 WAL 数据)的滞后时间和用于 WAL 数据的存储空间。当跨区域只读副本长时间滞后时,Transaction
Logs Disk Usage 值会显著增大。
有关使用 CloudWatch 监控数据库实例的更多信息,请参阅使用 Amazon CloudWatch 监控 Amazon RDS 指标。