Amazon RDS 的多可用区数据库集群部署
多可用区数据库集群部署是 Amazon RDS 的半同步、高可用性部署模式,具有两个可读副本数据库实例。多可用区数据库集群在同一个 Amazon Web Services 区域 的三个独立可用区中有一个写入器数据库实例和两个读取器数据库实例。与多可用区数据库实例部署相比,多可用区数据库集群可提供高可用性、增加读取工作负载容量以及更低的写入延迟。
您可以使用 将数据导入 Amazon RDS for MySQL 数据库实例并减少停机时间 中的说明将本地数据库中的数据导入到多可用区数据库集群。
您可以为多可用区数据库集群购买预留数据库实例。有关更多信息,请参阅 多可用区数据库集群的预留数据库实例。
功能可用性和支持因每个数据库引擎的特定版本以及 Amazon Web Services 区域而异。有关使用多可用区数据库集群的 Amazon RDS 的版本和区域可用性的更多信息,请参阅支持 Amazon RDS 中多可用区数据库集群的区域和数据库引擎。
主题
重要
多可用区数据库集群与 Aurora 数据库集群不同。有关使用 Aurora 数据库集群的更多信息,请参阅《Amazon Aurora 用户指南》。
多可用区数据库集群的实例类可用性
以下数据库实例类支持多可用区数据库集群部署:db.m5d、db.m6gd、db.m6id、db.m6idn、db.r5d、db.r6gd、db.x2iedn、db.r6id、db.r6idn 和 db.c6gd。
注意
c6gd 实例类是仅有的支持 medium 实例大小的实例类。
有关数据库实例类的更多信息,请参阅数据库实例类。
多可用区数据库集群架构
使用多可用区数据库集群,Amazon RDS 使用数据库引擎的本机复制功能将数据从写入器数据库实例复制到两个读取器数据库实例。当对写入器数据库实例进行更改时,它会发送给每个读取器数据库实例。
多可用区数据库集群部署使用半同步复制,这需要来自至少一个读取器数据库实例的确认才能提交更改。它不需要确认事件已在所有副本上完全执行和提交。
读取器数据库实例可充当自动故障转移目标,还可提供读取流量以提高应用程序读取吞吐量。如果写入器数据库实例发生中断,RDS 将管理到其中一个读取器数据库实例的故障转移。RDS 会根据具有最近更改记录的读取器数据库实例来执行此操作。
下图显示了一个多可用区数据库集群。
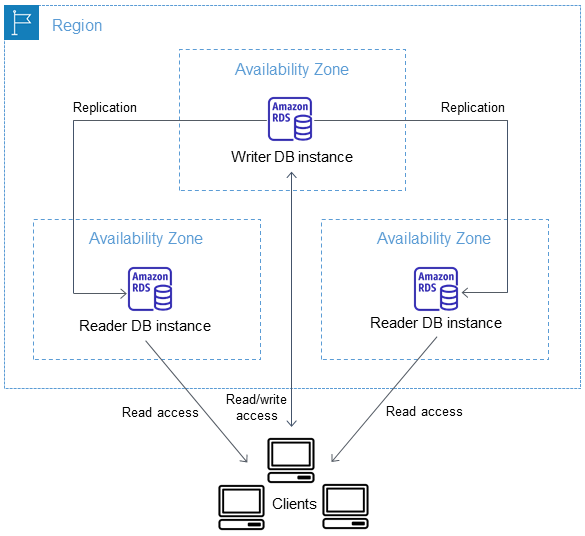
与多可用区数据库实例部署相比,多可用区数据库集群的写入延迟通常较低。其还允许在读取器数据库实例上运行只读工作负载。RDS 控制台显示了写入器数据库实例的可用区和读取器数据库实例的可用区。您也可以使用 describe-db-clusters CLI 命令或 DescribeDBClusters API 操作来查找此信息。
重要
为防止 RDS for MySQL 多可用区数据库集群出现复制错误,我们强烈建议所有表都具有主键。
多可用区数据库集群的参数组
在多可用区数据库集群中,数据库集群参数组就像是引擎配置值的容器,这些值可应用于多可用区数据库集群中的每个数据库实例。
在多可用区数据库集群中,数据库参数组设置为数据库引擎和数据库引擎版本的默认数据库参数组。数据库集群参数组中的设置用于集群中的所有数据库实例。
有关参数组的信息,请参阅 使用多可用区数据库集群的数据库集群参数组。
RDS 代理与多可用区数据库集群
您可以使用 Amazon RDS 代理为您的多可用区数据库集群创建代理。通过使用 RDS 代理,您的应用程序可以池化和共享数据库连接,以提高其扩展能力。每个代理都执行连接多路复用,也称为连接重用。对于多路复用,RDS 代理使用一个底层数据库连接对事务执行所有操作。RDS 代理还可以将多可用区数据库集群的次要版本升级的停机时间缩短到一秒或更短。有关 RDS 代理优点的更多信息,请参阅 Amazon RDS 代理。
要为多可用区数据库集群设置代理,请在创建集群时选择创建 RDS 代理。有关创建和管理 RDS 代理端点的说明,请参阅 使用 Amazon RDS Proxy 终端节点。
副本滞后和多可用区数据库集群
副本滞后是写入器数据库实例上的最新事务与读取器数据库实例上的最新应用事务之间的时间差异。Amazon CloudWatch 指标 ReplicaLag 表示这种时间差。有关 CloudWatch 指标的更多信息,请参阅使用 Amazon CloudWatch 监控 Amazon RDS 指标。
尽管多可用区数据库集群允许高写入性能,但基于引擎的复制的性质仍可能导致副本滞后。由于任何故障转移都必须先解决副本滞后问题,然后才能提升新的写入器数据库实例,因此要考虑监控和管理此副本滞后。
对于 RDS for MySQL 多可用区数据库集群,故障转移时间取决于两个剩余读取器数据库实例的副本滞后。两个读取器数据库实例必须先应用未应用的事务,然后才能将其中一个升级为新写入器数据库实例。
对于 RDS for PostgreSQL 多可用区数据库集群,故障转移时间取决于两个剩余读取器数据库实例的最低副本滞后。具有最低副本滞后的读取器数据库实例必须先应用未应用的事务,然后才能将其升级为新写入器数据库实例。
有关演示副本滞后超过设置时间量时如何创建 CloudWatch 告警的教程,请参阅 教程:为 Amazon RDS 的多可用区数据库集群副本滞后创建 Amazon CloudWatch 警报。
副本滞后的常见原因
一般来说,写入工作负载过高,导致读取器数据库实例无法有效应用事务时,就会出现副本滞后。各种工作负载都可能会产生临时或持续副本滞后。以下是一些常见示例:
-
写入器数据库实例的高写入并发或大量批处理更新,导致读取器数据库实例上的应用过程落后。
-
在一个或多个读取器数据库实例上使用资源的繁重的读取工作负载。运行速度慢或查询数量多都可能会影响应用进程,继而导致副本滞后。
-
由于数据库必须保留提交顺序,因此修改大量数据或 DDL 语句的事务有时会暂时加剧副本滞后问题。
缓解副本滞后问题
对于适用于 RDS for MySQL 和 RDS for PostgreSQL 的多可用区数据库集群,您可以通过减少写入器数据库实例的负载来缓解副本滞后问题。您还可以使用流量控制来减少副本滞后。流量控制通过限制写入器数据库实例上的写入操作来发挥作用,从而确保副本滞后时间不会继续无限延长。通过在事务结束时添加延迟来实现写入限制,以此降低写入器数据库实例的写入吞吐量。流量控制不能保证会消除滞后,但可以帮助缩短许多工作负载的总体滞后时间。以下各节提供有关将流量控制与 RDS for MySQL 和 RDS for PostgreSQL 结合使用的信息。
使用 RDS for MySQL 的流量控制来缓解副本滞后
当您使用 RDS for MySQL 多可用区数据库集群时,默认情况下,使用动态参数 rpl_semi_sync_master_target_apply_lag 启用流量控制。此参数指定副本滞后的上限。当副本滞后接近这一配置的限制时,流量控制会限制写入器数据库实例上的写入事务,以尝试将副本滞后控制在指定值以下。在某些情况下,副本滞后可能会超过指定的限制。默认情况下,该参数设置为 120 秒。要禁用流量控制,请将该参数设置为其最大值 86400 秒(一天)。
要查看流量控制注入的当前延迟,请通过运行以下查询来显示参数 Rpl_semi_sync_master_flow_control_current_delay。
SHOW GLOBAL STATUS like '%flow_control%';
您的输出应类似于以下内容。
+-------------------------------------------------+-------+
| Variable_name | Value |
+-------------------------------------------------+-------+
| Rpl_semi_sync_master_flow_control_current_delay | 2010 |
+-------------------------------------------------+-------+
1 row in set (0.00 sec)注意
延迟以微秒为单位显示。
当您为 RDS for MySQL 多可用区数据库集群启用 Performance Insights 时,您可以监控与指示查询通过流量控制延迟的 SQL 语句对应的等待事件。当流量控制引入延迟时,您可以查看与 Performance Insights 控制面板上的 SQL 语句对应的等待事件 /wait/synch/cond/semisync/semi_sync_flow_control_delay_cond。要查看这些指标,请确保性能架构已启用。有关 Performance Insights 的信息,请参阅 在 Amazon RDS 上使用性能详情监控数据库负载。
使用 RDS for PostgreSQL 的流量控制来缓解副本滞后
使用 RDS for PostgreSQL 多可用区数据库集群时,流量控制作为扩展部署。其为数据库集群中的所有数据库实例开启后台工件。默认情况下,读取器数据库实例上的后台工件会将当前副本滞后情况告知写入器数据库实例上的后台工件信。如果读取器数据库实例的滞后时间超过两分钟,则写入器数据库实例上的后台工件会在事务结束时添加延迟。若要控制滞后阈值,请使用参数 flow_control.target_standby_apply_lag。
流量控制限制 PostgreSQL 进程时,pg_stat_activity 和 Performance Insights 中的 Extension 等待事件会表明该情况。函数 get_flow_control_stats 显示当前所添加延迟时长的详细信息。
流量控制可以给大多数短时、高量并发联机事务处理 (OLTP) 工作负载带来益处。如果滞后由长时间运行的事务(如分批操作)造成,流量控制便无法提供特别大的助益。
从 shared_preload_libraries 中移除扩展程序,然后重启数据库实例,即可关闭流量控制。
多可用区数据库集群快照
Amazon RDS 会在所配置的备份时段内创建并保存多可用区数据库集群的自动备份。RDS 创建数据库集群的存储卷快照,同时备份整个集群而不仅仅是各个实例。
也可以手动备份多可用区数据库集群。对于非常长期的备份,请考虑将快照数据导出到 Amazon S3。有关更多信息,请参阅 创建 Amazon RDS 的多可用区数据库集群快照。
您可以将多可用区数据库集群还原到特定时间点,从而创建新的多可用区数据库集群。有关说明,请参阅将多可用区数据库集群还原到指定时间。
或者,可以将多可用区数据库集群快照还原到单可用区部署或多可用区数据库实例部署。有关说明,请参阅从多可用区数据库集群快照还原到数据库实例。