Amazon RDS 零 ETL 集成的数据筛选
Amazon RDS 零 ETL 集成支持数据筛选,这使您可以控制哪些数据从源 Amazon RDS 数据库复制到目标数据仓库。您可以应用一个或多个筛选条件来有选择地包含或排除特定的表,而不是复制整个数据库。这可以通过确保只传输相关数据,来协助您优化存储和查询性能。目前,筛选仅限于数据库级和表级。不支持列级和行级筛选。
当您要执行以下操作时,数据筛选可能很有用:
-
联接来自两个或更多不同源数据库的某些表,而您不需要来自任一数据库的完整数据。
-
仅使用表的子集而不是整个数据库实例集来执行分析,从而节省成本。
-
从某些表中筛选掉敏感信息,例如电话号码、地址或信用卡详细信息。
您可以使用 Amazon Web Services 管理控制台、Amazon Command Line Interface(Amazon CLI)或 Amazon RDS API 向零 ETL 集成添加数据筛选条件。
如果集成将预置集群作为其目标,则该集群必须使用补丁 180 或更高版本,才能使用数据筛选。
主题
数据筛选条件的格式
您可以为单个集成定义多个筛选条件。每个筛选条件要么包含、要么排除任何与筛选表达式中的模式之一匹配的现有和将来的数据库表。Amazon RDS 零 ETL 集成使用 Maxwell 筛选条件语法
每个筛选条件都包含以下元素:
| Element | 说明 |
|---|---|
| 筛选条件类型 |
|
| 筛选表达式 |
逗号分隔的模式列表。表达式必须使用 Maxwell 筛选条件语法 |
| Pattern |
一种筛选模式,格式为 注意对于 RDS for MySQL,数据库和表名称均支持正则表达式。对于 RDS for PostgreSQL,只有架构和表名称支持正则表达式,而数据库名称不支持正则表达式。 您不能包含列级别筛选条件或黑名单。 单个集成最多可以有总共 99 个模式。在控制台中,可以在单个筛选表达式中输入模式,也可以将它们分散在多个表达式中。单个模式的长度不能超过 256 个字符。 |
重要
如果选择 RDS for PostgreSQL 源数据库,则必须至少指定一种数据筛选模式。该模式必须至少包含一个数据库 (database-name.*.*
下图显示了控制台中 RDS for MySQL 数据筛选条件的结构:
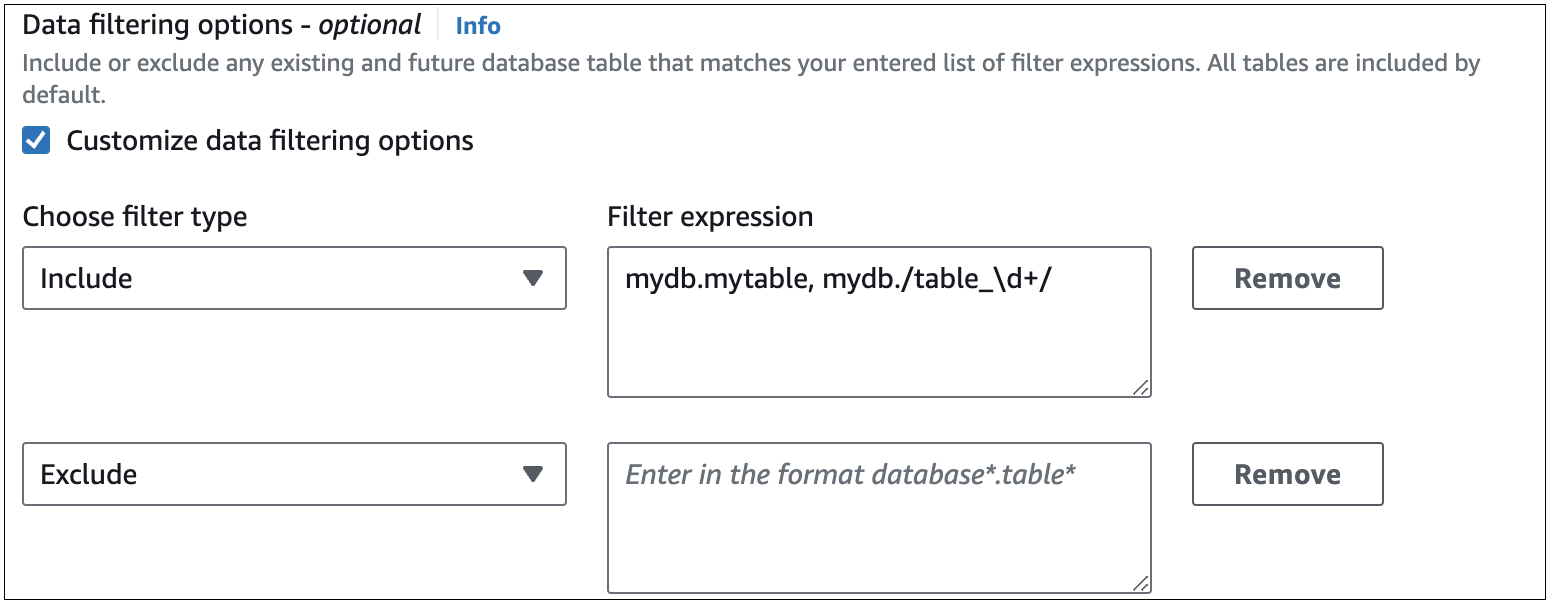
重要
请勿在筛选条件模式中包含个人身份信息、机密信息或敏感信息。
Amazon CLI 中的数据筛选条件
使用 Amazon CLI 添加数据筛选条件时,语法与使用控制台略有不同。必须为每种模式分别指定筛选条件类型(Include 或 Exclude),因此不能将多个模式分组到一个筛选条件类型下。
例如,在控制台中,可以在单个 Include 语句下对以下逗号分隔的模式进行分组:
RDS for MySQL
mydb.mytable,mydb./table_\d+/
RDS for PostgreSQL
mydb.myschema.mytable,mydb.myschema./table_\d+/
但是,使用 Amazon CLI 时,相同的数据筛选条件必须采用以下格式:
RDS for MySQL
'include:mydb.mytable, include:mydb./table_\d+/'
RDS for PostgreSQL
'include:mydb.myschema.mytable, include:mydb.myschema./table_\d+/'
筛选条件逻辑
如果您在集成中未指定任何数据筛选条件,Amazon RDS 会采用默认筛选条件 include:*.*,这会将所有表复制到目标数据仓库。但是,如果您至少添加一个筛选条件,则默认逻辑会切换为 exclude:*.*,默认情况下这会排除所有表。这使您可以显式定义要在复制中包含哪些数据库和表。
例如,如果您定义以下筛选条件:
'include: db.table1, include: db.table2'
Amazon RDS 按以下方式评估筛选条件:
'exclude:*.*, include: db.table1, include: db.table2'
因此,Amazon RDS 仅将来自名为 db 的数据库的 table1 和 table2 复制到目标数据仓库。
筛选条件优先级
Amazon RDS 按您指定的顺序评估数据筛选条件。在 Amazon Web Services 管理控制台中,它将从左到右、从上到下处理筛选表达式。第二个筛选条件或第一个筛选条件之后的单个模式可以覆盖它。
例如,如果第一个筛选条件是 Include books.stephenking,则它只包括 books 数据库中的 stephenking 表。但是,如果您添加第二个筛选条件 Exclude books.*,则它会覆盖第一个筛选条件。这可以防止将 books 索引中的任何表复制到目标数据仓库。
当您指定至少一个筛选条件时,默认情况下,逻辑以采用 exclude:*.* 开始,这会自动将所有表排除 在复制范围之外。作为最佳实践,请按照从最广泛到最具体的顺序定义筛选条件。首先使用一个或多个 Include 语句来指定要复制的数据,然后添加 Exclude 筛选条件来有选择性地移除某些表。
同样的原则也适用于使用 Amazon CLI 定义的筛选条件。Amazon RDS 按您指定筛选条件模式的顺序评估这些模式,因此一个模式可能会覆盖您指定的在它之前的模式。
RDS for MySQL 示例
以下示例演示了如何将数据筛选用于 RDS for MySQL 示例零 ETL 集成:
-
包括所有数据库和所有表:
'include: *.*' -
包括
books数据库中的所有表:'include: books.*' -
排除任何名为
mystery的表:'include: *.*, exclude: *.mystery' -
包括
books数据库中的两个特定表:'include: books.stephen_king, include: books.carolyn_keene' -
包括
books数据库中的所有表,但那些包含子字符串mystery的表除外:'include: books.*, exclude: books./.*mystery.*/' -
包括
books数据库中的所有表,但那些以mystery开头的表除外:'include: books.*, exclude: books./mystery.*/' -
包括
books数据库中的所有表,但那些以mystery结束的表除外:'include: books.*, exclude: books./.*mystery/' -
包括
books数据库中的所有以table_开头的表,但名为table_stephen_king的表除外。例如,将复制table_movies或table_books,但不复制table_stephen_king。'include: books./table_.*/, exclude: books.table_stephen_king'
RDS for PostgreSQL 示例
以下示例演示了如何将数据筛选用于 RDS for PostgreSQL 零 ETL 集成:
-
包括
books数据库中的所有表:'include: books.*.*' -
排除
books数据库中名为mystery的所有表:'include: books.*.*, exclude: books.*.mystery' -
在
mystery架构的books数据库中包括一个表,在finance架构的employee数据库中包括一个表:'include: books.mystery.stephen_king, include: employee.finance.benefits' -
包括
books数据库和science_fiction架构中的所有表,但那些包含子字符串king的表除外:'include: books.science_fiction.*, exclude: books.*./.*king.*/ -
包括
books数据库中的所有表,但那些架构名称以sci开头的表除外:'include: books.*.*, exclude: books./sci.*/.*' -
包括
books数据库中的所有表,但那些在mystery架构中以king结束的表除外:'include: books.*.*, exclude: books.mystery./.*king/' -
包括
books数据库中的所有以table_开头的表,但名为table_stephen_king的表除外。例如,复制fiction架构中的table_movies和mystery架构中的table_books,但不复制任一架构中的table_stephen_king:'include: books.*./table_.*/, exclude: books.*.table_stephen_king'
RDS for Oracle 示例
以下示例演示了如何将数据筛选用于 RDS for Oracle 零 ETL 集成:
-
包括 books 数据库中的所有表:
'include: books.*.*' -
排除 books 数据库中名为 mystery 的所有表:
'include: books.*.*, exclude: books.*.mystery' -
包括 mystery 架构中 books 数据库内的一个表,以及 finance 架构中 employee 数据库内的一个表:
'include: books.mystery.stephen_king, include: employee.finance.benefits' -
包括 mystery 架构中 books 数据库内的所有表:
'include: books.mystery.*'
大小写方面的注意事项
Oracle Database 和 Amazon Redshift 对对象名称大小写的处理方式不同,这会影响数据筛选器配置和目标查询。请注意以下几点:
-
除非
CREATE语句中显式引用,否则 Oracle Database 以大写形式存储数据库、架构和对象名称。例如,如果您创建mytable(不带引号),Oracle 数据字典会将表名存储为MYTABLE。如果引用对象名称,则数据字典会保留大小写。 -
零 ETL 数据筛选器区分大小写,并且必须与 Oracle 数据字典中显示的对象名称的大小写完全匹配。
-
除非被显式引用,否则 Amazon Redshift 查询默认为小写对象名称。例如,查询
MYTABLE(无引号)会搜索mytable。
在创建 Amazon Redshift 筛选条件和查询数据时,请注意大小写差异。
创建一个使用大写名称的表
如果在创建表时没有用双引号指定名称,Oracle 数据库会将该名称以大写形式存储在数据字典中。例如,您可以使用以下任一 SQL 语句创建 MYTABLE。
CREATE TABLE REINVENT.MYTABLE (id NUMBER PRIMARY KEY, description VARCHAR2(100)); CREATE TABLE reinvent.mytable (id NUMBER PRIMARY KEY, description VARCHAR2(100)); CREATE TABLE REinvent.MyTable (id NUMBER PRIMARY KEY, description VARCHAR2(100)); CREATE TABLE reINVENT.MYtabLE (id NUMBER PRIMARY KEY, description VARCHAR2(100));
由于您在前面的语句中没有引用表名,因此 Oracle 数据库将对象名以大写形式存储为 MYTABLE。
要将此表复制到 Amazon Redshift,您必须在 create-integration 命令的数据筛选器中指定大写名称。零 ETL 筛选器名称和 Oracle 数据字典名称必须匹配。
aws rds create-integration \ --integration-name upperIntegration \ --data-filter "include: ORCL.REINVENT.MYTABLE" \ ...
默认情况下,Amazon Redshift 以小写形式存储数据。要在 Amazon Redshift 的复制数据库中查询 MYTABLE,您必须引用大写名称 MYTABLE,使其与 Oracle 数据字典中的大小写匹配。
SELECT * FROM targetdb1."REINVENT"."MYTABLE";
以下查询不使用引用机制。它们都会返回错误,因为它们搜索名为 mytable 的 Amazon Redshift 表,该表使用默认的小写名称,但该表在 Oracle 数据字典中的名称为 MYTABLE。
SELECT * FROM targetdb1."REINVENT".MYTABLE; SELECT * FROM targetdb1."REINVENT".MyTable; SELECT * FROM targetdb1."REINVENT".mytable;
以下查询使用引用机制来指定大小写混用名称。这些查询都会返回错误,因为它们搜索的不是名为 MYTABLE 的 Amazon Redshift 表。
SELECT * FROM targetdb1."REINVENT"."MYtablE"; SELECT * FROM targetdb1."REINVENT"."MyTable"; SELECT * FROM targetdb1."REINVENT"."mytable";
创建一个使用小写名称的表
在以下替代示例中,使用双引号将表名以小写形式存储在 Oracle 数据字典中。您可以按如下方式创建 mytable。
CREATE TABLE REINVENT."mytable" (id NUMBER PRIMARY KEY, description VARCHAR2(100));
Oracle 数据库以小写形式将表名存储为 mytable。要将此表复制到 Amazon Redshift,您必须在零 ETL 数据筛选器中指定小写名称 mytable。
aws rds create-integration \ --integration-name lowerIntegration \ --data-filter "include: ORCL.REINVENT.mytable" \ ...
在 Amazon Redshift 的复制数据库中查询此表时,您可以指定小写名称 mytable。这次查询将会成功,因为它搜索一个名为 mytable 的表,该名称是 Oracle 数据字典中的表名。
SELECT * FROM targetdb1."REINVENT".mytable;
由于 Amazon Redshift 默认使用小写的对象名称,因此以下查询也可以成功找到 mytable。
SELECT * FROM targetdb1."REINVENT".MYtablE; SELECT * FROM targetdb1."REINVENT".MYTABLE; SELECT * FROM targetdb1."REINVENT".MyTable;
以下查询使用对象名称的引用机制。它们都会返回错误,因为它们搜索的 Amazon Redshift 表名不同于 mytable。
SELECT * FROM targetdb1."REINVENT"."MYTABLE"; SELECT * FROM targetdb1."REINVENT"."MyTable"; SELECT * FROM targetdb1."REINVENT"."MYtablE";
创建一个包含大小写混合名称的表
在以下示例中,使用双引号将表名以小写形式存储在 Oracle 数据字典中。您可以按如下方式创建 MyTable。
CREATE TABLE REINVENT."MyTable" (id NUMBER PRIMARY KEY, description VARCHAR2(100));
Oracle 数据库以大小写混合的方式将此表名存储为 MyTable。要将此表复制到 Amazon Redshift,您必须在数据筛选器中指定大小写混用名称。
aws rds create-integration \ --integration-name mixedIntegration \ --data-filter "include: ORCL.REINVENT.MyTable" \ ...
在 Amazon Redshift 的复制数据库中查询此表时,必须通过引用对象名称来指定大小写混用名称 MyTable。
SELECT * FROM targetdb1."REINVENT"."MyTable";
由于 Amazon Redshift 默认使用小写对象名称,因此以下查询无法找到该对象,因为它们搜索的是小写名称 mytable。
SELECT * FROM targetdb1."REINVENT".MYtablE; SELECT * FROM targetdb1."REINVENT".MYTABLE; SELECT * FROM targetdb1."REINVENT".mytable;
注意
在 RDS for Oracle 集成中,您不能在数据库名称、架构名称或表名称的筛选值中使用正则表达式。
向集成添加数据筛选条件
您可以使用 Amazon Web Services 管理控制台、Amazon CLI 或 Amazon RDS API 配置数据筛选。
重要
如果您在创建集成后添加筛选条件,Amazon RDS 会将其视为似乎始终存在。它会移除目标数据仓库中不符合新筛选条件的任何数据,并重新同步所有受影响的表。
将数据筛选条件添加到零 ETL 集成中
登录 Amazon Web Services 管理控制台 并通过以下网址打开 Amazon RDS 控制台:https://console.aws.amazon.com/rds/
。 -
在导航窗格中,选择零 ETL 集成。选择要向其添加数据筛选条件的集成,然后选择修改。
-
在源下,添加一个或多个
Include和Exclude语句。下图显示了 MySQL 集成的数据筛选条件的示例:
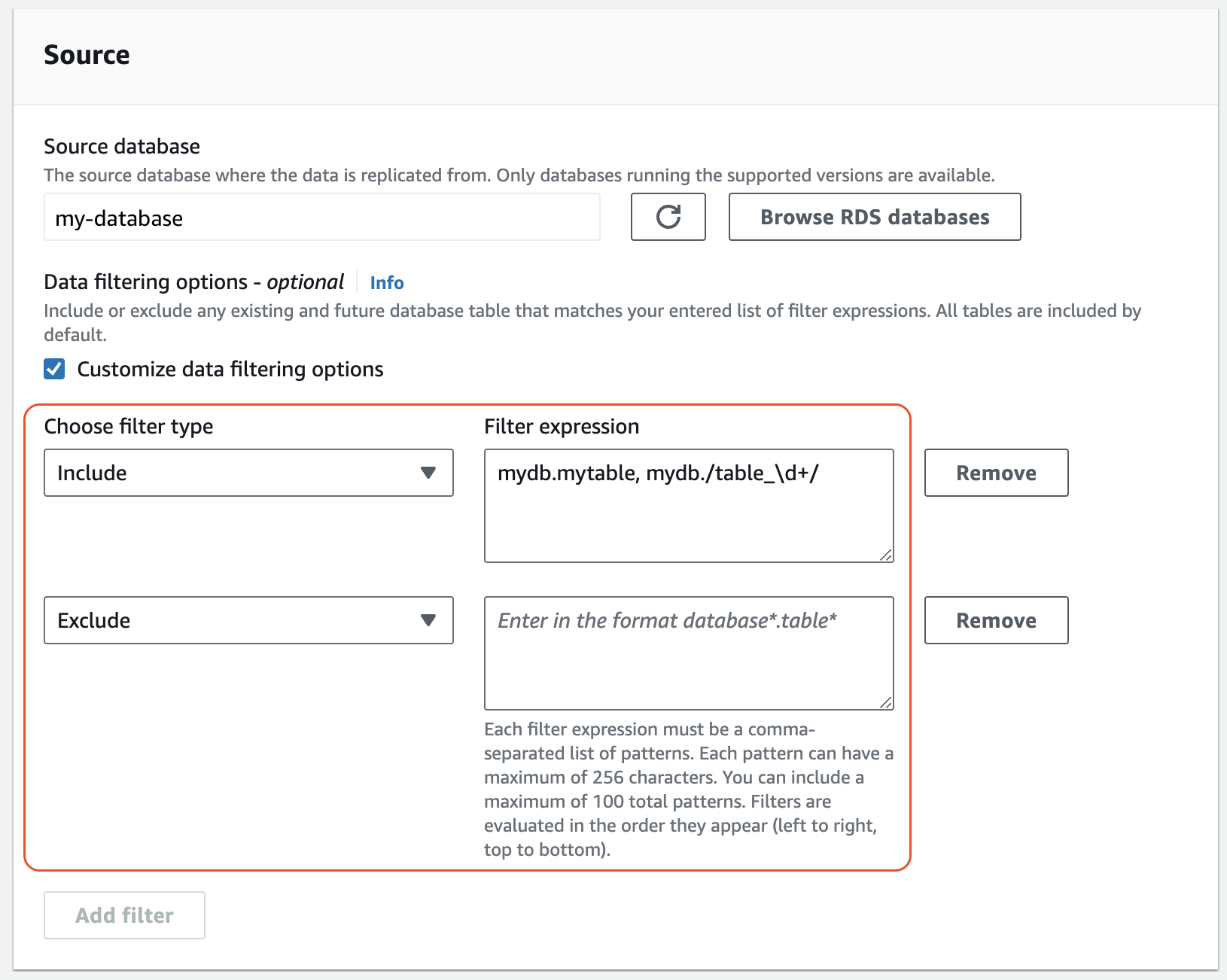
-
如果您对更改感到满意,请选择继续和保存更改。
要使用 Amazon CLI 向零 ETL 集成添加数据筛选条件,请调用 modify-integrationInclude 和 Exclude Maxwell 筛选条件列表来指定 --data-filter 参数。
例
以下示例向 my-integration 添加筛选条件模式。
对于 Linux、macOS 或 Unix:
aws rds modify-integration \ --integration-identifiermy-integration\ --data-filter'include: foodb.*, exclude: foodb.tbl, exclude: foodb./table_\d+/'
对于:Windows
aws rds modify-integration ^ --integration-identifiermy-integration^ --data-filter'include: foodb.*, exclude: foodb.tbl, exclude: foodb./table_\d+/'
要使用 RDS API 修改零 ETL 集成,请调用 ModifyIntegration 操作。指定集成标识符,并提供逗号分隔的筛选条件模式列表。
从集成中移除数据筛选条件
当您从集成中移除数据筛选条件时,Amazon RDS 会重新评估剩余的筛选条件,就好像移除的筛选条件从未存在过一样。然后,它将所有以前排除但现在符合条件的数据复制到目标数据仓库。这会触发所有受影响的表重新同步。