DAX 和 DynamoDB 一致性模型
Amazon DynamoDB Accelerator (DAX) 是一项直写缓存服务,旨在简化将缓存添加到 DynamoDB 表的过程。由于 DAX 独立于 DynamoDB 运行,务必同时了解 DAX 和 DynamoDB 的一致性模型,确保应用程序的行为方式符合预期。
在很多使用案例中,应用程序使用 DAX 的方式影响 DAX 集群内的数据一致性,以及 DAX 和 DynamoDB 之间的数据一致性。
DAX 集群节点之间的一致性
要为应用程序实现高可用性,建议为 DAX 集群预配置至少三个节点。然后将这些节点置于区域内的多个可用区中。
DAX 集群运行时,复制该集群中所有节点之间的数据(假定已预置多个节点)。考虑一个使用 DAX 成功执行 UpdateItem 的应用程序。此操作会导致使用新值修改主节点中的项目缓存。然后,该值复制到集群中的所有其他节点。此复制具有最终一致性,并且通常只需不到一秒即可完成。
在这种情况下,两个客户端可从同一 DAX 集群读取同一键但接收不同的值,具体取决于每个客户端访问的节点。当更新已在集群中的所有节点中完全复制后,这些节点将全部具有一致性。(此行为类似于 DynamoDB 的最终一致性。)
如果您要构建一个使用 DAX 的应用程序,则应采用可容忍最终一致的数据的方式设计该应用程序。
DAX 项目缓存行为
每个 DAX 集群都有两个不同的缓存 —项目缓存和查询缓存。有关更多信息,请参阅 DAX:工作原理。
本节将介绍在 DAX 项目缓存中进行读取和写入的一致性影响。
读取的一致性
利用 DynamoDB,GetItem 操作默认执行最终一致性读取。假设将 UpdateItem 与 DynamoDB 客户端一起使用。如果您随后立即尝试读取同一项目,则可能会看到数据在更新前的样子。这是由于所有 DynamoDB 存储位置中的传播延迟。通常,在几秒钟内即可实现一致性。因此,如果您重试读取,可能会看到更新后的项目。
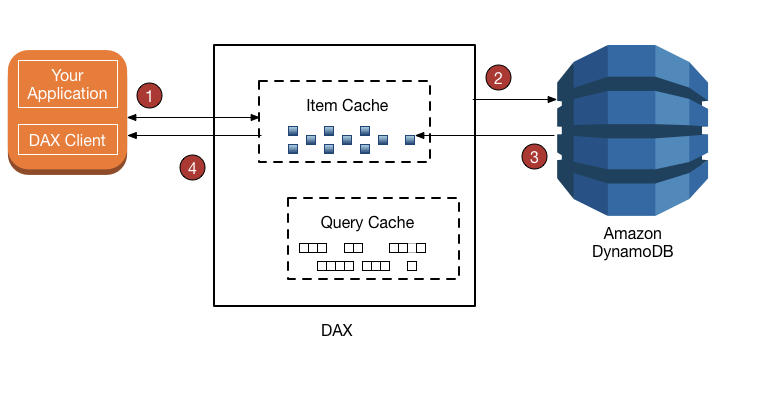
当您将 GetItem 与 DAX 客户端一起使用时,该操作(在本例中为最终一致性读取)按如下方式继续。
-
DAX 客户端发出
GetItem请求。DAX 尝试从项目缓存读取请求的项目。如果该项目在缓存中(缓存命中),则 DAX 会将其返回到应用程序。 -
如果该项目不可用(缓存未命中),则 DAX 将针对 DynamoDB 执行最终一致性
GetItem操作。 -
DynamoDB 返回请求的项目,DAX 将该项目存储在项目缓存中。
-
DAX 将项目返回到应用程序。
-
(未显示)如果 DAX 集群包含多个节点,则该项目将复制到集群中的所有其他节点。
项目根据 存活时间 (TTL) 设置和最近最少使用 (LUR) 算法,保留在 DAX 项目缓存中。有关更多信息,请参阅 DAX:工作原理。
但是,在此期间,DAX 不从 DynamoDB 再次读取该项目。如果其他人使用 DynamoDB 客户端完全绕过 DAX 更新该项目,则使用 DAX 客户端的 GetItem 请求生成的结果与使用 DynamoDB 客户端的 GetItem 请求不同。在这种情况下,DAX 和 DynamoDB 将对同一键保留不一致的值,直到 DAX 项目的 TTL 过期。
如果应用程序绕过 DAX 修改基础 DynamoDB 表的数据,则应用程序需要预测并容忍可能出现的数据不一致。
注意
除了 GetItem,DAX 客户端还支持 BatchGetItem 请求。BatchGetItem 基本上是围绕一个或多个 GetItem 请求的包装器,因此,DAX 将其中每个请求视为单独的 GetItem 操作。
写入的一致性
DAX 是一种直写缓存,可简化使 DAX 项目缓存与基础 DynamoDB 表保持一致的过程。
DAX 客户端支持与 DynamoDB 相同的写入 API 操作(PutItem、UpdateItem、DeleteItem、BatchWriteItem 和 TransactWriteItems)。如果将这些操作与 DAX 客户端结合使用,将在 DAX 和 DynamoDB 中修改这些项目。DAX 将在项目缓存中更新项目,无论这些项目的 TTL 值是多少。
例如,假设您从 DAX 客户端发出一个 GetItem 请求,从 ProductCatalog 表读取项目。(分区键为 Id,没有排序键。) 检索其 Id 为 101 的项目。该项目的 QuantityOnHand 值为 42。DAX 将项目存储在具有特定 TTL 的项目缓存中。对于本示例,假设 TTL 为 10 分钟。3 分钟后,另一个应用程序使用 DAX 客户端更新同一项目,这样其 QuantityOnHand 值现在为 41。假设该项目没有再更新,则在下一个 10 分钟期间内,同一项目的任何后续读取将返回 QuantityOnHand 的缓存值 (41)。
DAX 如何处理写入
DAX 适用于需要高性能读取的应用程序。作为直写缓存,DAX 将写入同步传递到 DynamoDB,然后将得到的更新自动异步复制到集群所有节点的项目缓存。无需管理缓存无效逻辑,因为 DAX 会为您处理。
DAX 支持以下写入操作:PutItem、UpdateItem、DeleteItem、BatchWriteItem 和 TransactWriteItems。
向 DAX 发送 PutItem、UpdateItem、DeleteItem 或 BatchWriteItem 请求时,将执行下列操作:
-
DAX 将请求发送到 DynamoDB。
-
DynamoDB 回复 DAX,确认写入成功。
-
DAX 将项目写入项目缓存。
-
DAX 将成功信息返回到请求者。
向 DAX 发送 TransactWriteItems 请求时,将执行下列操作:
-
DAX 将请求发送到 DynamoDB。
-
DynamoDB 回复 DAX,确认事务已完成。
-
DAX 将成功信息返回到请求者。
-
DAX 在后台对
TransactWriteItems请求的每个项目发出TransactGetItems请求,将项目存储在项目缓存中。TransactGetItems用于确保可序列化隔离。
如果因为任何原因(包括限制)写入 DynamoDB 失败,则不在 DAX 中缓存项目。失败的异常返回到请求方。这样确保数据在首次成功写入 DynamoDB 之前不会写入 DAX 缓存。
注意
每次写入 DAX 会更改项目缓存的状态。但是,写入项目缓存不会影响查询缓存。(DAX 项目缓存和查询缓存用于不同目的,相互独立运行。)
DAX 查询缓存行为
DAX 在其查询缓存中缓存 Query 和 Scan 请求的结果。但是,这些结果完全不影响项目缓存。应用程序使用 DAX 发出 Query 或 Scan 请求时,结果集将保存在查询缓存,而不是项目缓存。您无法通过执行 Scan 操作来“预热”项目缓存,因为项目缓存和查询缓存是不同实体。
查询-更新-查询的一致性
更新项目缓存或基础 DynamoDB 表,不会使存储在查询缓存中的结果失效或修改。
为了说明这种情况,请考虑以下情景。应用程序正在处理 DocumentRevisions 表,该表将 DocId 作为分区键,RevisionNumber 作为排序键。
-
客户端对
DocId101,所有具有RevisionNumber大于等于5的项目发出Query。DAX 将结果集存储在查询缓存中,并将结果集返回给用户。 -
客户端针对
RevisionNumber值为20的DocId101发出PutItem请求。 -
客户端发出与步骤 1 中相同的
Query(DocId101且RevisionNumber>=5)。
在这种情况下,步骤 3 中发出的 Query 的缓存结果集与步骤 1 中缓存的结果集相同。原因是 DAX 不会基于对各个项目的更新使 Query 或 Scan 结果集失效。如果 Query 的 TTL 过期,步骤 2 中的 PutItem 操作仅反映在 DAX 查询缓存中。
应用程序应考虑查询缓存的 TTL 值,以及应用程序能够容忍查询缓存与项目缓存之间的不一致结果的时长。
强一致性读取和事务读取
要执行强一致性 GetItem、BatchGetItem、Query 或 Scan 请求,请将 ConsistentRead 参数设置为 true。DAX 将强一致性读取请求传递到 DynamoDB。如果收到来自 DynamoDB 的响应,DAX 会将结果返回到客户端,但不会缓存结果。DAX 无法自行处理强一致性读取,因为它未紧密耦合到 DynamoDB。因此,任何从 DAX 后续读取必须为最终一致性读取。任何后续强一致性读取将传递到 DynamoDB。
DAX 以处理强一致性读取的相同方式处理 TransactGetItems 请求。DAX 将所有 TransactGetItems 请求传递到 DynamoDB。如果收到来自 DynamoDB 的响应,DAX 会将结果返回到客户端,但不会缓存结果。
逆向缓存
DAX 在项目缓存和查询缓存中都支持逆向缓存条目。如果 DAX 在基础 DynamoDB 表中找不到请求项目,将产生逆向缓存条目。DAX 不会生成错误,而会缓存空结果并将该结果返回到用户。
例如,假设应用程序向 DAX 集群发送一个 GetItem 请求,并且 DAX 项目缓存中没有匹配的项目。这将导致 DAX 从基础 DynamoDB 表读取对应的项目。如果该项目在 DynamoDB 中不存在,DAX 会将一个空项目存储在项目缓存中,然后将此空项目返回给该应用程序。现在假设应用程序发送对相同项目的另一个 GetItem 请求。DAX 将在项目缓存中找到空项目,然后立即将它返回到该应用程序。而根本不会征求 DynamoDB 的意见。
逆向缓存条目将保留在 DAX 项目缓存中,直到项目 TTL 已过期、调用 LRU 或者使用 PutItem、UpdateItem 或 DeleteItem 修改项目。
DAX 查询缓存将采用类似的方法处理逆向缓存结果。如果应用程序执行 Query 或 Scan,并且 DAX 查询缓存不包含缓存的结果,DAX 会将该请求发送到 DynamoDB。如果结果集中没有匹配项目,DAX 会将空结果集存储在查询缓存中,并将空结果集返回到该应用程序。后续的 Query 或 Scan 请求将生成相同的(空)结果集,直到该结果集的 TTL 已过期。
针对写入的策略
DAX 的直写行为适合很多应用程序模式。但是,也存在一些可能不适合直写模型的应用程序模式。
对于对延迟敏感的应用程序,通过 DAX 进行写入会产生一个额外的网络跃点。因此,写入 DAX 将比直接写入 DynamoDB 稍慢一点。如果应用程序对写入延迟敏感,您可通过改为直接写入 DynamoDB 降低延迟。有关更多信息,请参见 绕写。
对于写入密集型应用程序(如执行批量数据加载的应用程序),您可能不希望通过 DAX 写入所有数据,因为只有极小一部分数据会由这种应用程序读取。通过 DAX 写入大量数据时,必须调用其 LRU 算法在缓存中为要读取的新项目腾出空间。这将减小 DAX 作为读取缓存的有效性。
当您将某个项目写入到 DAX 时,项目缓存状态将更改以适应新项目。(例如,DAX 可能需要从项目缓存中移出旧数据以便为新项目腾出空间。) 新项目将保留在项目缓存中,具体取决于缓存的 LRU 算法和缓存的 TTL 设置。只要项目保留在项目缓存中,DAX 就不会从 DynamoDB 再次读取项目。
直写
DAX 项目缓存将实施直写策略。有关更多信息,请参阅 DAX 如何处理写入。
写入项目时,DAX 将确保缓存的项目与 DynamoDB 中存在的项目同步。这对于需要在写入项目后立即再次读取项目的应用程序很有用。但是,如果其他应用程序直接对 DynamoDB 表进行写入,则 DAX 项目缓存中的项目将不再与 DynamoDB 保持同步。
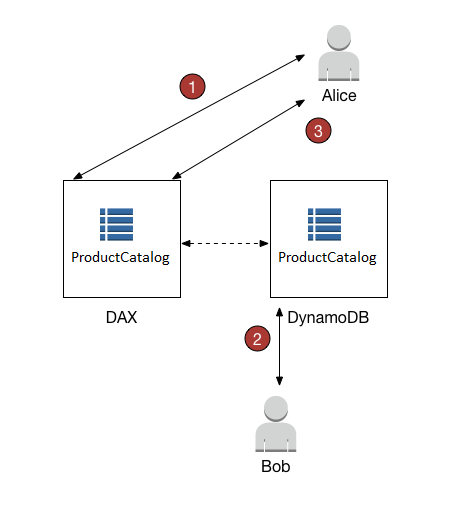
为了说明这种情况,请考虑正在使用 ProductCatalog 表的两位用户(Alice 和 Bob)。Alice 使用 DAX 访问该表,而 Bob 则绕过 DAX 直接在 DynamoDB 中访问该表。
-
Alice 更新
ProductCatalog表的项目。DAX 将请求转发到 DynamoDB,更新成功。然后,DAX 将项目写入到项目缓存中,将成功响应返回 Alice。从此时起,直到项目最终从缓存中移出,从 DAX 读取项目的所有用户都将看到包含 Alice 的更新的项目。 -
不久后,Bob 更新 Alice 写入的同一个
ProductCatalog项目。但是,Bob 直接在 DynamoDB 中更新该项目。DAX 不会自动刷新其项目缓存来响应通过 DynamoDB 实现的更新。因此,DAX 用户看不到 Bob 的更新。 -
Alice 再次从 DAX 读取该项目。该项目位于项目缓存中,因此 DAX 会将它返回给 Alice 而无需访问 DynamoDB 表。
在这种情况下,Alice 和 Bob 将看到同一 ProductCatalog 项目的不同表示形式。在 DAX 从项目缓存中移出该项目之前或其他用户使用 DAX 再次更新同一项目之前,将会是这种情况。
绕写
如果应用程序需要写入大量数据(如批量数据加载),可以绕过 DAX 并将数据直接写入 DynamoDB。这样的绕写策略减少了写入延迟。但是,项目缓存不与 DynamoDB 中的数据保持同步。
如果决定使用绕写策略,请记住,DAX 在应用程序使用 DAX 客户端读取数据时填充其项目缓存。这可能在某些情况下很有用,因为它确保了仅缓存读取得最频繁的数据(而不是写入得最频繁的数据)。
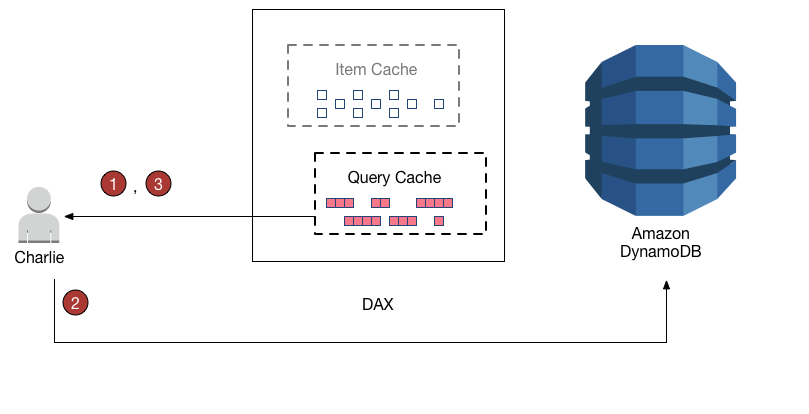
例如,请考虑一个希望使用 DAX 处理不同表(即 GameScores 表)的用户 (Charlie)。GameScores 的分区键是 UserId,因此,Charlie 的所有分数都具有相同的 UserId。
-
Charlie 希望检索其所有分数,因此,他向 DAX 发送了一条
Query请求。假设以前未发布过此查询,DAX 将查询转发到 DynamoDB 进行处理。它将结果存储在 DAX 查询缓存中,然后将结果返回给 Charlie。结果集在查询缓存中保持可用,直到被移出。 -
现在,假设 Charlie 玩 Meteor Blasters 游戏并获得了高分数。Charlie 向 DynamoDB 发送一条
UpdateItem请求,修改GameScores表中的一个项目。 -
最后,Charlie 决定重新运行之前的
Query,从GameScores中检索其所有数据。Charlie 没有在结果中看到他的 Meteor Blasters 的高分数。这是因为查询结果来自查询缓存,而不是项目缓存。这两种缓存是相互独立的,因此一种缓存中的更改不会影响另一种缓存。
DAX 不会使用来自 DynamoDB 的最新数据来刷新查询缓存中的结果集。查询缓存中的每个结果集都是截止执行 Query 或 Scan 操作时的状态。因此,Charlie 的 Query 结果不会反映其 PutItem 操作。在 DAX 从查询缓存中移出此结果集之前,将一直是这种情况。