Amazon DynamoDB 的核心组件
在 DynamoDB 中,表、项目和属性是您使用的核心组件。表是项目的集合,而每个项目是属性的集合。DynamoDB 使用主键来唯一标识表中的各个项目。您可以使用 DynamoDB Streams 捕获 DynamoDB 表中的数据修改事件。
DynamoDB 中存在限制。有关更多信息,请参阅 Amazon DynamoDB 中的配额。
以下视频将向您介绍表、项目和属性。
表、项目和属性
以下是基本的 DynamoDB 组件:
-
表 – 类似于其他数据库系统,DynamoDB 将数据存储在表中。表 是数据的集合。例如,请参阅名为 People 的示例表,该表可用于存储有关好友、家人或关注的任何其他人的个人联系信息。您也可以建立一个 Cars 表,存储有关人们所驾驶的车辆的信息。
-
项目 – 每个表包含零个或更多个项目。项目 是一组属性,具有不同于所有其他项目的唯一标识。在 People 表中,每个项目表示一位人员。在 Cars 表中,每个项目代表一种车。DynamoDB 中的项目在很多方面都类似于其他数据库系统中的行、记录或元组。在 DynamoDB 中,对表中可存储的项目数没有限制。
-
属性 – 每个项目包含一个或多个属性。属性 是基础的数据元素,无需进一步分解。例如,People 表中的一个项目包含名为 PersonID、LastName、FirstName 等的属性。对于 Department 表,项目可能包含 DepartmentID、Name、Manager 等属性。DynamoDB 中的属性在很多方面都类似于其他数据库系统中的字段或列。
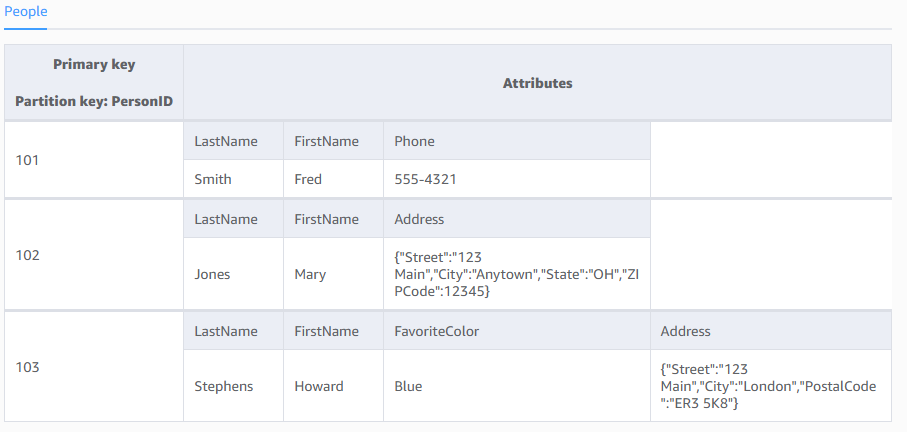
下图是一个名为 People 的表,其中显示了一些示例项目和属性。
People
{
"PersonID": 101,
"LastName": "Smith",
"FirstName": "Fred",
"Phone": "555-4321"
}
{
"PersonID": 102,
"LastName": "Jones",
"FirstName": "Mary",
"Address": {
"Street": "123 Main",
"City": "Anytown",
"State": "OH",
"ZIPCode": 12345
}
}
{
"PersonID": 103,
"LastName": "Stephens",
"FirstName": "Howard",
"Address": {
"Street": "123 Main",
"City": "London",
"PostalCode": "ER3 5K8"
},
"FavoriteColor": "Blue"
}请注意有关 People 表的以下事项:
-
表中的每个项目都有一个唯一的标识符或主键,用于将项目与表中的所有其他内容区分开来。在 People 表中,主键包含一个属性 (PersonID)。
-
与主键不同,People 表是无架构的,这表示属性及其数据类型都不需要预先定义。每个项目都能拥有其自己的独特属性。
-
大多数属性是标量 类型的,这表示它们只能具有一个值。字符串和数字是标量的常见示例。
-
某些项目具有嵌套属性 (Address)。DynamoDB 支持高达 32 级深度的嵌套属性。
下面是名为 Music 的另一个示例表,该表可用于跟踪音乐精选。
Music
{
"Artist": "No One You Know",
"SongTitle": "My Dog Spot",
"AlbumTitle": "Hey Now",
"Price": 1.98,
"Genre": "Country",
"CriticRating": 8.4
}
{
"Artist": "No One You Know",
"SongTitle": "Somewhere Down The Road",
"AlbumTitle": "Somewhat Famous",
"Genre": "Country",
"CriticRating": 8.4,
"Year": 1984
}
{
"Artist": "The Acme Band",
"SongTitle": "Still in Love",
"AlbumTitle": "The Buck Starts Here",
"Price": 2.47,
"Genre": "Rock",
"PromotionInfo": {
"RadioStationsPlaying": [
"KHCR",
"KQBX",
"WTNR",
"WJJH"
],
"TourDates": {
"Seattle": "20150622",
"Cleveland": "20150630"
},
"Rotation": "Heavy"
}
}
{
"Artist": "The Acme Band",
"SongTitle": "Look Out, World",
"AlbumTitle": "The Buck Starts Here",
"Price": 0.99,
"Genre": "Rock"
} 请注意有关 Music 表的以下事项:
-
Music 的主键包含两个属性(Artist 和 SongTitle)。表中的每个项目必须具有这两个属性。Artist 和 SongTitle 的属性组合用于将表中的每个项目与所有其他内容区分开来。
-
与主键不同,Music 表是无架构的,这表示属性及其数据类型都不需要预先定义。每个项目都能拥有其自己的独特属性。
-
其中一个项目具有嵌套属性 (PromotionInfo),该属性包含其他嵌套属性。DynamoDB 支持高达 32 级深度的嵌套属性。
有关更多信息,请参阅 使用 DynamoDB 中的表和数据。
主键
创建表时,除表名称外,您还必须指定表的主键。主键唯一标识表中的每个项目,因此,任意两个项目的主键都不相同。
DynamoDB 支持两种不同类型的主键:
-
分区键 – 由一个称为分区键的属性构成的简单主键。
DynamoDB 使用分区键的值作为内部散列函数的输入。来自散列函数的输出决定了项目将存储到的分区(DynamoDB 内部的物理存储)。
在只有分区键的表中,任何两个项目都不能有相同的分区键值。
表、项目和属性 的 People 表具有简单主键 (PersonID)。您可以直接访问 People 表中的任何项目,方法是提供该项目的 PersonId 值。
-
分区键和排序键 – 称为复合主键,此类型的键由两个属性组成。第一个属性是分区键,第二个属性是排序键。
DynamoDB 使用分区键值作为对内部哈希函数的输入。来自散列函数的输出决定了项目将存储到的分区(DynamoDB 内部的物理存储)。具有相同分区键值的所有项目按排序键值的排序顺序存储在一起。
在具有分区键和排序键的表中,多个项目可能具有相同的分区键值。但是,这些项目必须具有不同的排序键值。
表、项目和属性 的 Music 表是具有复合主键(Artist 和 SongTitle)的表示例。您可以直接访问 Music 表中的任何项目,方法是提供该项目的 Artist 和 SongTitle 值。
在查询数据时,复合主键可让您获得额外的灵活性。例如,如果您仅提供了 Artist 的值,则 DynamoDB 将检索该艺术家的所有歌曲。要仅检索特定艺术家的一部分歌曲,您可以提供一个 Artist 值和一系列 SongTitle 值。
注意
项目的分区键也称为其哈希属性。哈希属性一词源自 DynamoDB 中使用的内部哈希函数,以基于数据项目的分区键值实现跨多个分区的数据项目平均分布。
项目的排序键也称为其范围属性。范围属性一词源自 DynamoDB 存储项目的方式,它按照排序键值有序地将具有相同分区键的项目存储在互相紧邻的物理位置。
每个主键属性必须为标量 (表示它只能具有一个值)。主键属性唯一允许的数据类型是字符串、数字和二进制。对于其他非键属性没有任何此类限制。
二级索引
您可以在一个表上创建一个或多个二级索引。利用二级索引,除了可对主键进行查询外,还可使用替代键查询表中的数据。DynamoDB 不需要使用索引,为应用程序提供数据查询方面的更大的灵活性。在表中创建二级索引后,您可以从索引中读取数据,方法与从表中读取数据大体相同。
DynamoDB 支持两种索引:
-
全局二级索引 – 分区键和排序键可与基表中的这些键不同的索引。全局二级索引中的主键值无需唯一。
-
本地二级索引 – 分区键与基表相同但排序键不同的索引。
在 DynamoDB 中,全局二级索引(GSI)是跨整个表的索引,允许您跨所有分区键进行查询。本地二级索引(LSI)的分区键与基表相同,但排序键不同。
DynamoDB 中的每个表具有 20 个全局二级索引(默认配额)和 5 个本地二级索引的配额。
在前面显示的示例 Music 表中,您可以按 Artist(分区键)或按 Artist 和 SongTitle(分区键和排序键)查询数据项。如果您还想要按 Genre 和 AlbumTitle 查询数据,该怎么办? 若要达到此目的,您可在 Genre 和 AlbumTitle 上创建一个索引,然后通过与查询 Music 表相同的方式查询索引。
下图显示了示例 Music 表,该表包含一个名为 GenreAlbumTitle 的新索引。在索引中,Genre 是分区键,AlbumTitle 是排序键。
| Music 表 | GenreAlbumTitle |
|---|---|
|
|
|
|
|
|
|
|
请注意有关 GenreAlbumTitle 索引的以下事项:
-
每个索引属于一个表(称为索引的基表)。在上述示例中,Music 是 GenreAlbumTitle 索引的基表。
-
DynamoDB 将自动维护索引。当您添加、更新或删除基表中的某个项目时,DynamoDB 会添加、更新或删除属于该表的任何索引中的对应项目。
-
当您创建索引时,可指定哪些属性将从基表复制或投影 到索引。DynamoDB 至少会将键属性从基表投影到索引中。对于
GenreAlbumTitle也是如此,只不过此时只有Music表中的键属性会投影到索引中。
您可以查询 GenreAlbumTitle 索引以查找某个特定流派的所有专辑(例如,所有 Rock 专辑)。您还可以查询索引以查找特定流派中具有特定专辑名称的所有专辑(例如,名称以字母 H 开头的所有 Country 专辑)。
有关更多信息,请参阅 在 DynamoDB 中使用二级索引改进数据访问。
DynamoDB Streams
DynamoDB Streams 是一项可选功能,用于捕获 DynamoDB 表中的数据修改事件。有关这些事件的数据将以事件发生的顺序近乎实时地出现在流中。
每个事件由一条流记录 表示。如果您对表启用流,则每当以下事件之一发生时,DynamoDB Streams 都会写入一条流记录:
-
向表中添加了新项目:流将捕获整个项目的映像,包括其所有属性。
-
更新了项目:流将捕获项目中已修改的任何属性的“之前”和“之后”映像。
-
从表中删除了项目:流将在整个项目被删除前捕获其映像。
每条流记录还包含表的名称、事件时间戳和其他元数据。流记录具有 24 个小时的生命周期;在此时间过后,它们将从流中自动删除。
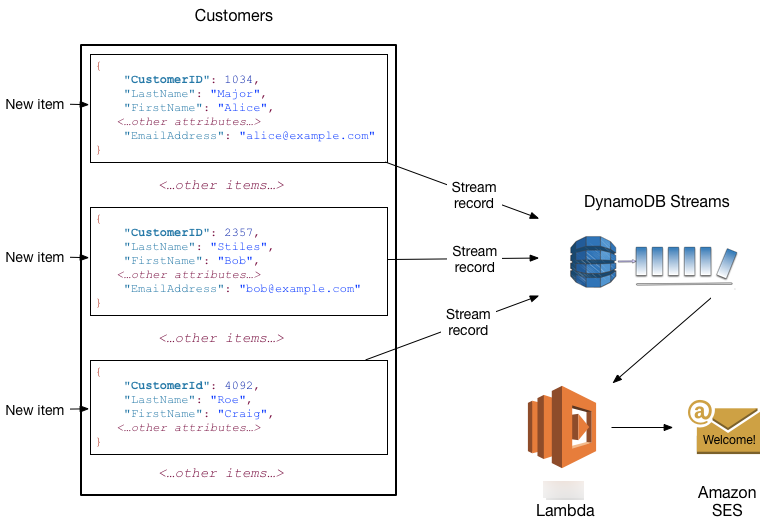
您可以将 DynamoDB Streams 与 Amazon Lambda 结合使用以创建触发器—在流中有您感兴趣的事件出现时自动执行的代码。例如,假设有一个包含某公司客户信息的 Customers 表。假设您希望向每位新客户发送一封“欢迎”电子邮件。您可对该表启用一个流,然后将该流与 Lambda 函数关联。Lambda 函数将在新的流记录出现时执行,但只会处理添加到 Customers 表的新项目。对于具有 EmailAddress 属性的任何项目,Lambda 函数将调用 Amazon Simple Email Service (Amazon SES) 以向该地址发送电子邮件。
注意
在此示例中,最后一位客户 Craig Roe 将不会收到电子邮件,因为他没有 EmailAddress。
除了触发器之外,DynamoDB Streams 还提供了强大的解决方案,例如,Amazon 区域内和区域之间的数据复制、DynamoDB 表中的数据具体化视图、使用 Kinesis 具体化视图的数据分析等。
有关更多信息,请参阅 将更改数据捕获用于 DynamoDB Streams。