在 DynamoDB 中扫描表
Amazon DynamoDB 中的 Scan 操作读取表或二级索引中的每个项目。默认情况下,Scan 操作返回表或索引中每个项目的全部数据属性。您可以使用 ProjectionExpression 参数,以便 Scan 仅返回部分属性而不是全部属性。
Scan 始终返回结果集。如果未找到匹配的项目,结果集将为空。
单个 Scan 请求最多可检索 1 MB 数据。(可选)DynamoDB 可以向这些数据应用筛选表达式,从而在将数据返回给用户之前缩小结果范围。
扫描的筛选表达式
如果您需要进一步细化 Scan 结果,则可以选择性地提供筛选表达式。筛选表达式可确定 Scan 结果中应返回给您的项目。所有其他结果将会丢弃。
筛选表达式在 Scan 已完成但结果尚未返回时应用。因此,无论是否存在筛选表达式,Scan 都将占用同等数量的读取容量。
Scan 操作最多可检索 1 MB 的数据。此限制在计算筛选表达式之前应用。
使用 Scan,您可以在筛选表达式中指定任何属性,包括分区键和排序键属性。
筛选表达式的语法与条件表达式的相同。筛选表达式可使用的比较运算符、函数和逻辑运算符与条件表达式可使用的相同。有关逻辑运算符的更多信息,请参阅 DynamoDB 中的条件表达式和筛选表达式、运算符及函数。
例
以下 Amazon Command Line Interface (Amazon CLI) 示例将扫描 Thread 表,此时仅返回此表中由特定用户最新发布到的项目。
aws dynamodb scan \ --table-name Thread \ --filter-expression "LastPostedBy = :name" \ --expression-attribute-values '{":name":{"S":"User A"}}'
限制结果集中的项目数
Scan 操作可让您限制结果中返回的项目数。为此,将 Limit 参数设置为您在筛选条件表达式求值前希望 Scan 操作返回的最大项目数。
例如,假设您对某个表进行 Scan,Limit 值为 6,并且没有筛选表达式。Scan 结果包含表中的前 6 个项目。
现在假设您向 Scan 添加了一个筛选表达式。在这种情况下,DynamoDB 将向返回的前 6 个项目应用筛选表达式,不考虑不匹配的项目。最终的 Scan 结果将包含 6 个或更少的项目,具体取决于筛选出的项目数。
对结果分页
DynamoDB 分页来自 Scan 操作的结果。利用分页,Scan 结果将分成若干“页”大小为 1 MB(或更小)的数据。应用程序可以先处理第一页结果,然后处理第二页结果,依此类推。
单次 Scan 只会返回符合 1 MB 大小限制的结果集。
要确定是否存在更多结果,并一次检索一页结果,应用程序应执行以下操作:
-
检查低级别
Scan结果:-
如果结果包含
LastEvaluatedKey元素,请继续步骤 2。 -
如果结果中没有
LastEvaluatedKey,则表示没有其他要检索的项目。
-
-
构造新的
Scan请求,使用与前一个请求相同的参数。但是,此次获取来自步骤 1 的LastEvaluatedKey值,并将其用作新ExclusiveStartKey请求中的Scan参数。 -
运行新的
Scan请求。 -
前往步骤 1。
换言之,LastEvaluatedKey 响应中的 Scan 应该用作下一 ExclusiveStartKey 请求的 Scan。如果 LastEvaluatedKey 响应中没有 Scan 元素,则表示您已检索最后一页结果。(检查是否没有 LastEvaluatedKey 是确定您是否已到达结果集末尾的唯一方式。)
您可以使用 Amazon CLI 查看此行为。Amazon CLI 向 DynamoDB 反复发送低级别 Scan 请求,直到请求中不再有 LastEvaluatedKey。请考虑以下 Amazon CLI 示例,它扫描整个 Movies 表,但仅返回特定流派的电影。
aws dynamodb scan \ --table-name Movies \ --projection-expression "title" \ --filter-expression 'contains(info.genres,:gen)' \ --expression-attribute-values '{":gen":{"S":"Sci-Fi"}}' \ --page-size 100 \ --debug
通常,Amazon CLI 自动处理分页。但是,在此例中,Amazon CLI --page-size 参数限制了每页项目数。--debug 参数输出有关请求和响应的低级别信息。
注意
根据您传递的输入参数,您的分页结果也会有所不同。
-
使用
aws dynamodb scan --table-name Prices --max-items 1返回NextToken -
使用
aws dynamodb scan --table-name Prices --limit 1返回LastEvaluatedKey。
另请注意,使用 --starting-token 特别要求 NextToken 值。
如果您运行该示例,DynamoDB 的首次响应类似如下内容。
2017-07-07 12:19:14,389 - MainThread - botocore.parsers - DEBUG - Response body: b'{"Count":7,"Items":[{"title":{"S":"Monster on the Campus"}},{"title":{"S":"+1"}}, {"title":{"S":"100 Degrees Below Zero"}},{"title":{"S":"About Time"}},{"title":{"S":"After Earth"}}, {"title":{"S":"Age of Dinosaurs"}},{"title":{"S":"Cloudy with a Chance of Meatballs 2"}}], "LastEvaluatedKey":{"year":{"N":"2013"},"title":{"S":"Curse of Chucky"}},"ScannedCount":100}'
响应中的 LastEvaluatedKey 指示并未检索所有项目。随后,Amazon CLI 会将另一个 Scan 请求发送到 DynamoDB。此请求和响应模式继续,直到收到最终响应。
2017-07-07 12:19:17,830 - MainThread - botocore.parsers - DEBUG - Response body: b'{"Count":1,"Items":[{"title":{"S":"WarGames"}}],"ScannedCount":6}'
如果不存在 LastEvaluatedKey,则表示没有其他要检索的项目。
注意
Amazon SDK 处理低级别的 DynamoDB 响应(包括是否存在 LastEvaluatedKey),并提供各种抽象概念对 Scan 结果进行分页。例如,适用于 Java 的 SDK 文档接口提供 java.util.Iterator 支持,以便您能够一次处理一个结果。
对于各种编程语言的代码示例,请参阅本地化的 Amazon DynamoDB 入门指南和 Amazon SDK 文档。
对结果中的项目进行计数
除了与您的条件匹配的项目之外,Scan 响应还包含以下元素:
-
ScannedCount— 在应用任何ScanFilter之前计算的项目数。ScannedCount值很高但Count结果很少或为零,指Scan操作效率低下。如果您没有在请求中使用筛选器,则ScannedCount与Count相同。 -
Count— 在应用筛选表达式(如果有)之后,剩余的项目数量。
注意
如果您不使用筛选表达式,那么 ScannedCount 和 Count 将具有相同的值。
如果 Scan 结果集的大小大于 1 MB,则 ScannedCount 和 Count 将仅表示项目总数的部分计数。您需要执行多次 Scan 操作才能检索所有结果(请参阅对结果分页)。
所有 Scan 响应都将包含由该特定 ScannedCount 请求处理的项目的 Count 和 Scan。要获取所有 Scan 请求的总和,您可以对 ScannedCount 和 Count 记录流水账。
扫描占用的容量单位
您可以对任何表或二级索引执行 Scan 操作。Scan 操作将占用读取容量单位,如下所示:
如果对...进行 Scan |
DynamoDB 将占用...的读取容量单位 |
|---|---|
| 表 | 表的预置读取容量。 |
| 全局二级索引 | 索引的预置读取容量。 |
| 本地二级索引 | 基表的预置读取容量。 |
注意
基于资源的策略目前不支持跨账户访问二级索引扫描操作。
默认情况下,Scan 操作不会返回任何有关它占用的读取容量大小的数据。但是,您可在 ReturnConsumedCapacity 请求中指定 Scan 参数以获取此信息。下面是 ReturnConsumedCapacity 的有效设置:
-
NONE— 不返回任何已占用容量数据。(这是默认值。) -
TOTAL— 响应包含占用的读取容量单位的总数。 -
INDEXES— 响应显示占用的读取容量单位的总数,以及访问的每个表和索引的占用容量。
DynamoDB 将基于项目数量以及这些项目的大小,而不是基于返回到应用程序的数据量来计算消耗的读取容量单位数。因此,无论您是请求所有属性(默认行为)还是只请求部分属性(使用投影表达式),占用的容量单位数都是相同的。无论您是否使用筛选表达式,该数值也都是一样的。Scan 消耗最小的读取容量单位,来为高达 4 KB 的项目每秒执行一次强一致性读取,或每秒执行两次最终一致性读取。如果您需要读取大于 4KB 的项目,DynamoDB 需要额外的读取请求单位。空表和分区键数量稀疏的超大表,可能会有在超出扫描的数据量后对一些额外的 RCU 收费的情况。这包括处理 Scan 请求的费用,即使不存在数据也是如此。
扫描的读取一致性
默认情况下,Scan 操作将执行最终一致性读取。这意味着 Scan 结果可能无法反映由最近完成的 PutItem 或 UpdateItem 操作导致的更改。有关更多信息,请参阅 DynamoDB 读取一致性。
如果您需要强一致性读取,请在 Scan 开始时在 ConsistentRead 请求中将 true 参数设置为 Scan。这可确保在 Scan 开始前完成的所有写入操作都会包括在 Scan 响应中。
备份或复制表时,可以将 ConsistentRead 设置为 true,并结合 DynamoDB Streams。首先,您使用 Scan 并将 ConsistentRead 设置为 true 来获取表中数据的一致性副本。Scan 操作期间,DynamoDB Streams 会记录表上发生的任何其他写入活动。在 Scan 完成后,您可以将流中的写入活动应用于该表。
注意
与保留 Scan 的默认值 (ConsistentRead) 相比,true 设置为 ConsistentRead 的 false 操作将占用两倍的读取容量单位。
并行扫描
默认情况下,Scan 操作按顺序处理数据。Amazon DynamoDB 以 1 MB 的增量向应用程序返回数据,应用程序执行其他 Scan 操作检索接下来 1 MB 的数据。
扫描的表或索引越大,Scan 完成需要的时间越长。此外,一个顺序 Scan 可能并不总是能够充分利用预调配的读取吞吐容量:即使 DynamoDB 跨多个物理分区分配大型表的数据,Scan 操作一次只能读取一个分区。出于这个原因,Scan 受到单个分区的最大吞吐量限制。
为了解决这些问题,Scan操作可以逻辑地将表或二级索引分成多个分段,多个应用程序工作进程并行扫描这些段。每个工作进程可以是一个线程(在支持多线程的编程语言中),也可以是一个操作系统进程。要执行并行扫描,每个工作进程都会发出自己的 Scan 请求,并使用以下参数:
-
Segment— 要由特定工作进程扫描的段。每个工作进程应使用不同的Segment值。 -
TotalSegments— 并行扫描的片段总数。该值必须与应用程序将使用的工作进程数量相同。
下图显示了多线程应用程序如何执行具有三度并行的并行 Scan。
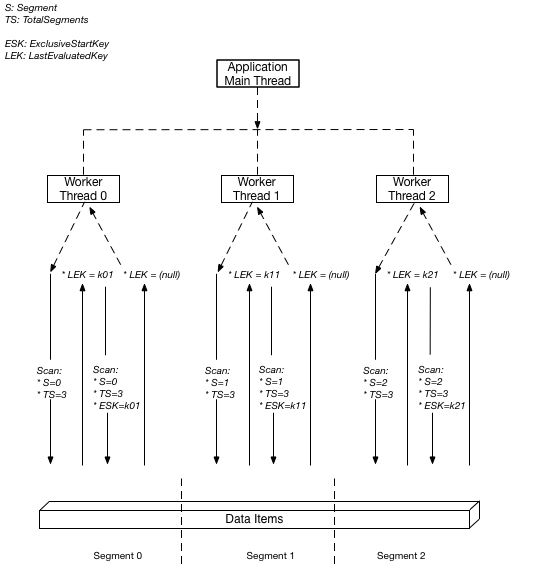
在此图中,应用程序生成三个线程,并为每个线程分配一个编号。(段从零开始,因此第一个编号始终为 0。) 每个线程发出 Scan 请求,将 Segment 设置为其指定的编号并将 TotalSegments 设置为 3。每个线程扫描其指定的段,每次检索 1 MB 的数据,并将数据返回到应用程序的主线程。
DynamoDB 通过对每个项目的分区键应用哈希函数,将项目分配给分段。对于给定 TotalSegments 值,所有具有相同分区键的项目总是被分配给相同的 Segment。这意味着,在项目 1、项目 2 和项目 3 都共享 pk="account#123"(但排序键不同)的表中,无论排序键值或项目集合的大小如何,这些项目都将由同一个 worker 处理。
由于分段分配仅基于分区键哈希,因此分段的分布可能不均匀。有些分段可能不包含任何项目,而另一些分段可能包含许多带有大型项目集合的分区键。因此,增加分段总数并不能保证获得更快的扫描性能,尤其是在分区键在键空间中分布不均匀的情况下。
Segment 和 TotalSegments 值适用于单个 Scan 请求,可以随时使用不同的值。您可能需要对这些值以及您使用的工作集成数进行试验,直到您的应用程序达到最佳性能。
注意
具有大量工作进程的并行扫描可以轻松占用正在扫描的表或索引的所有预配置吞吐量。如果表或索引也引起来自其他应用程序的大量读取或写入活动,最好避免进行此类扫描。
要控制每个请求返回的数据量,请使用 Limit 参数。这有助于防止出现一个工作进程占用所有预配置吞吐量而牺牲所有其他工作进程的情况。