Amazon DynamoDB 中的节流故障排除
DynamoDB 实施节流主要出于两个原因:维护整体服务性能和成本控制。当资源消耗速率超过容量时,节流可作为一种主动保护措施,防止性能下降;当达到最大吞吐量或服务配额限制时,节流也可作为一种成本控制机制。发生节流情况时,DynamoDB 会返回特定的异常错误以及详细信息,说明请求受限的原因以及什么资源会受到影响。对于节流情况,每条原因都会对应于特定的 CloudWatch 指标,提供对节流事件的频率和模式的更多见解。
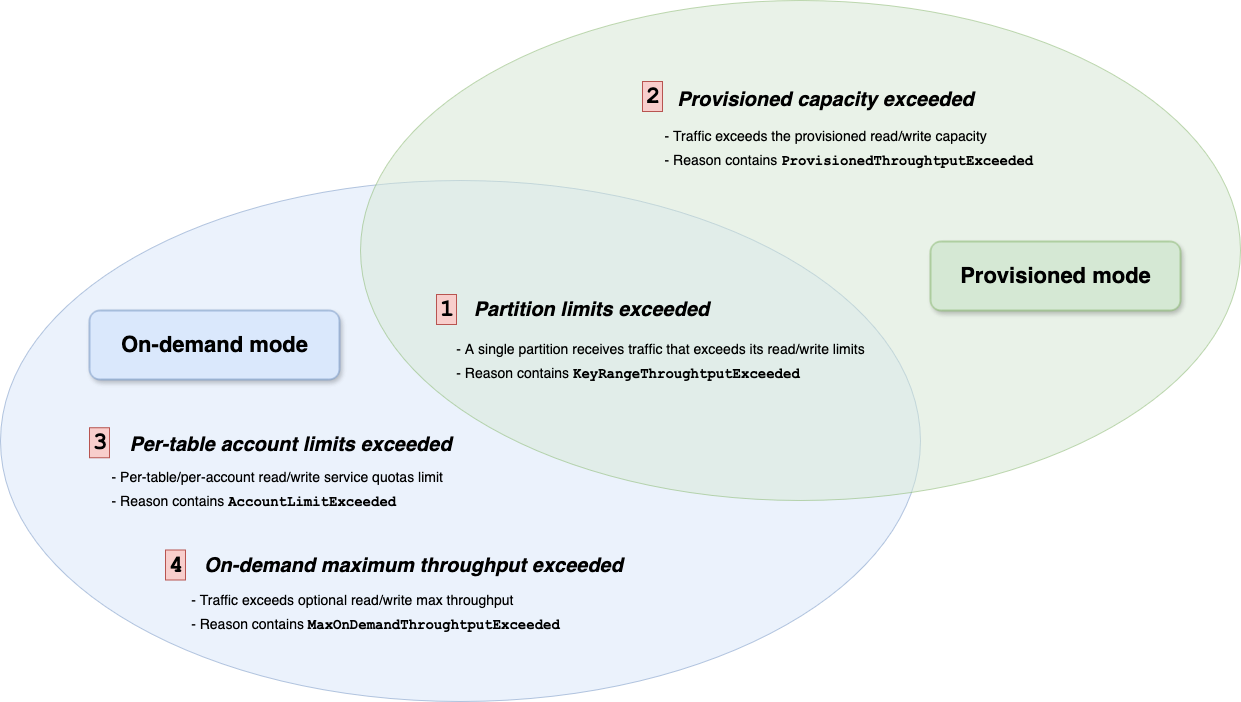
以下图表阐述了 DynamoDB 实施保护性节流的四种主要场景:
-
超过键范围吞吐量(在两种模式中):
指向特定分区的使用量超过了内部分区级别的吞吐量限制。
-
超过预置吞吐量(在预置模式中):
使用量超过了为表或全局二级索引(GSI)配置的预置容量单位(读取或写入)。
-
超过账户级别的服务配额(在按需模式中):
在当前 Amazon 区域中,使用量导致表或 GSI 的读取/写入吞吐量超过每个表的账户级服务配额。这些配额起到后备保护措施的作用,可以增加。
-
超过按需最大吞吐量(在按需模式中):
使用量超过了为表或 GSI 配置的最大吞吐量限额。这些是您专门为控制成本而配置的限额。
本指南意在帮助您了解和处理 DynamoDB 中的节流问题。首先,我们通过诊断框架,协助您确定影响工作负载的特定节流类型。
然后,解决方案指南部分针对每种节流场景提供具体指导,包括所要监控的 CloudWatch 指标以便进行检测和分析,以及推荐的优化步骤。遵循这种结构化方法,您可以更好地诊断造成节流情况的根本原因,并实施相应的解决方案来确保 DynamoDB 表高效运行。
要开始解决相关问题,请按照诊断节流中的内容,学习如何确定影响您的工作负载的节流类型,并实施推荐的解决策略。