DynamoDB 中的路由策略
或许全局表部署中最复杂的部分是管理请求路由。请求必须首先从终端用户发送到以某种方式选择和路由的区域。该请求会遇到该区域中的一些服务堆栈,包括一个计算层 [可能由 Amazon Lambda 函数支持的负载均衡器、容器或 Amazon Elastic Compute Cloud(Amazon EC2)节点组成],以及可能包括其他数据库在内的其他服务。该计算层与 DynamoDB 通信。它应该通过使用该区域的本地端点来实现。全局表中的数据会复制到所有其他参与区域,并且每个区域在其 DynamoDB 表周围都有类似的服务堆栈。
全局表为不同区域中的每个堆栈提供具有相同数据的本地副本。如果本地 DynamoDB 表出现问题,您可以考虑在单个区域中设计单个堆栈,并预计会远程调用辅助区域的 DynamoDB 端点。这不是最佳实践。如果一个区域存在由 DynamoDB 引起的问题(或者更有可能是由堆栈中的其他内容或其他依赖于 DynamoDB 的服务造成的),则最好将最终用户路由到另一个区域进行处理,然后使用另一个区域的计算层,该计算层将与其本地 DynamoDB 端点通信。此方法完全绕过了有问题的区域。为了确保韧性,您需要跨多个区域进行复制:计算层以及数据层的复制。
有许多替代技术可以将终端用户请求路由到区域进行处理。最佳选择取决于您的写入模式和失效转移注意事项。本节讨论四个选项:客户端驱动、计算层、Route 53 和 Global Accelerator。
客户端驱动的请求路由
如下图所示,使用客户端驱动的请求路由,最终用户客户端(应用程序、使用 JavaScript 的网页或其他客户端)可以跟踪有效的应用程序端点(例如,Amazon API Gateway 端点,而不是字面上的 DynamoDB 端点),并使用自己的嵌入式逻辑来选择要与之通信的区域。该客户端可以根据随机选择、观测到的最低延迟、观测到的最大带宽测量值或本地执行的运行状况检查来进行选择。
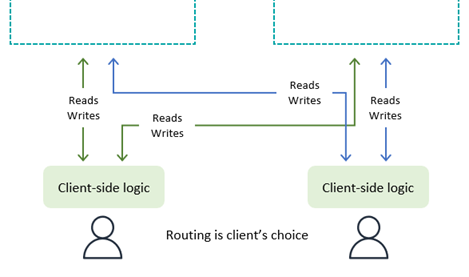
客户端驱动的请求路由的优势在于,它可以适应现实世界中的公共互联网流量状况等情况,以便在发现任何性能下降时切换区域。客户端必须知道所有潜在的端点,但启动新的区域端点并不常见。
通过写入任何区域模式,客户端可以单方面选择其首选端点。如果客户端对一个区域的访问受到妨碍,则客户端可以路由到另一个端点。
在写入一个区域模式下,客户端将需要一种机制来将其写入操作路由到当前主动区域。这可能像凭经验测试哪个区域当前正在接受写入一样基本(注意任何写入拒绝并回退到备用区域),也可能像调用全局协调器来查询当前应用程序状态一样复杂 [可能建立在 Amazon 应用程序恢复控制器(ARC)路由控制之上,该路由控制提供 5 区域仲裁驱动系统来维护全局状态以满足此类需求]。客户端可以决定读取是可以转到任何区域以实现最终一致性,还是必须路由到主动区域以实现强一致性。有关更多信息,请参阅 Route 53 的工作原理。
在写入您的区域模式下,客户端需要确定它正在处理的数据集的主区域。例如,如果客户端对应于一个用户账户,并且每个用户账户都有一个区域作为主区域,则客户端可以从全局登录系统请求相应的端点。
例如,一家通过网络帮助用户管理业务财务的金融服务公司可以使用全局表以及写入您的区域模式。每个用户都必须登录中央服务。该服务返回凭证以及将使用这些凭证的区域的端点。凭证在短时间内有效。之后,网页会自动协商新的登录信息,这提供了可能将用户的活动重定向到新区域的机会。
计算层请求路由
如下图所示,通过计算层请求路由,在计算层中运行的代码决定是要在本地处理请求,还是将请求传递给在另一个区域运行的其自身的副本。当您使用写入一个区域模式时,计算层可能会检测到该区域不是主动区域,并允许本地读取操作,而将所有写入操作转发到另一个区域。此计算层代码必须了解数据拓扑和路由规则,并根据最新设置(用于指定哪些区域对于哪些数据为主动状态)可靠地执行这些规则。区域内的外部软件堆栈不必知道微服务是如何路由读取和写入请求的。在稳健的设计中,接收区域会验证它是否为写入操作的当前主区域。如果不是,则会生成一个错误,表明需要更正全局状态。如果主区域处于更改过程中,则接收区域也可能将写入操作缓冲一段时间。在所有情况下,区域中的计算堆栈仅写入其本地 DynamoDB 端点,但计算堆栈可能会相互通信。
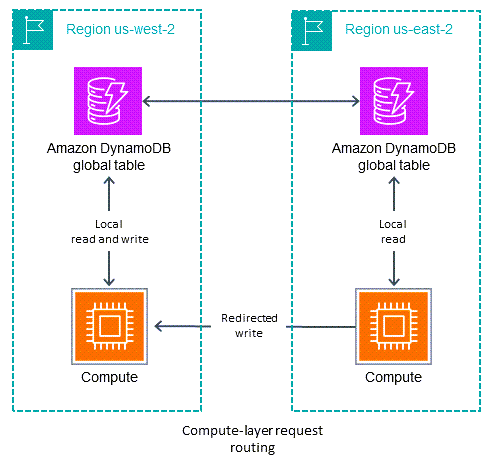
正如 re:Invent 2022
Route 53 请求路由
Amazon 应用程序恢复控制器(ARC)是一种域名服务(DNS)技术。使用 Route 53 时,客户端通过查找众所周知的 DNS 域名来请求其端点,Route 53 返回与其认为最合适的区域端点相对应的 IP 地址。此过程如下图所示。Route 53 具有一个很长路由策略列表,用于确定适当的区域。还可以用于失效转移路由,以将流量路由出运行状况检查失败的区域。
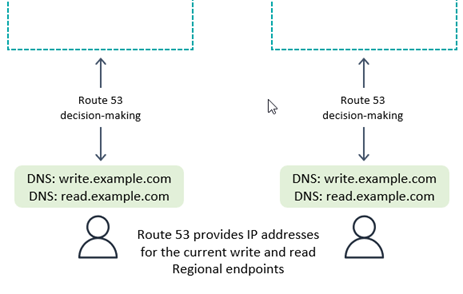
通过写入任何区域模式,或者与后端的计算层请求路由结合使用,可以向 Route 53 授予完全访问权限,以根据任何复杂的内部规则(例如,最接近网络中的区域、最接近的地理位置中的区域或任何其他选择)返回区域。
通过写入一个区域模式,您可以将 Route 53 配置为返回当前主动区域(使用 Route 53 ARC)。如果客户端想要连接到被动区域(例如,用于读取操作),则可以查找不同的 DNS 名称。
注意
客户端缓存来自 Route 53 的响应中的 IP 地址,缓存时间由域名上的生存时间(TTL)设置指示。较长的 TTL 可延长所有客户端识别新端点的恢复时间目标(RTO)。60 秒的值通常用于失效转移。并非所有软件都能完全遵守 DNS TTL 到期,且可能存在多个级别的 DNS 缓存,例如在操作系统、虚拟机和应用程序中。
在写入您的区域模式下,除非您还使用计算层请求路由,否则最好避开 Route 53。
Global Accelerator 请求路由
如下图所示,借助 Amazon Global Accelerator
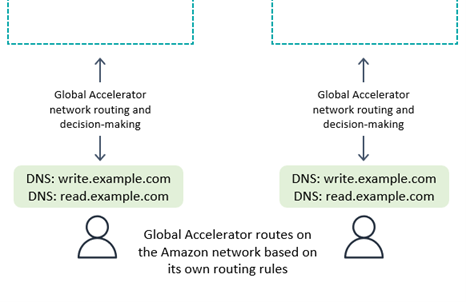
通过写入任何区域模式,或者在后端与计算层请求路由结合使用,Global Accelerator 可以无缝运行。客户端连接到最近的边缘站点,无需关心哪个区域会收到请求。
使用写入一个区域时,Global Accelerator 路由规则必须将请求发送到当前主动区域。您可以使用运行状况检查,人为地报告任何未被全局系统视为主动区域的区域上的故障。与 DNS 一样,如果请求可以来自任何区域,则可以使用备用 DNS 域名来路由读取请求。
在写入您的区域模式下,除非您还使用计算层请求路由,否则最好避开 Global Accelerator。