在 DynamoDB 中使用全局二级索引进行具体化聚合查询
对于希望快速做出决策的企业来说,对快速更改的数据维持近实时聚合和键指标正变得越来越重要。例如,音乐库可能需要近实时地展示下载量最多的歌曲,或者电子商务平台可能需要按类别显示热门产品。
由于 DynamoDB 并不原生支持跨项目的 SUM 或 COUNT 等聚合操作,因此在读取时计算这些值需要扫描大量项目,这可能导致速度缓慢并且成本高昂。您可以改为随着数据的更改预先计算聚合,并将结果作为常规项目存储在表中。这种模式称为实体化聚合。
示例场景和访问模式
请考虑具有以下要求的音乐库应用程序:
该应用程序记录大量的单首歌曲下载量(每秒数千首)。
用户需要以个位数毫秒级的延迟,查看给定月份下载量最多的歌曲。
该应用程序还需要支持诸如“本月十大热门歌曲”和“给定月份的所有歌曲下载量”之类的查询。
对于这种规模,若在读取时通过扫描所有下载记录来计算下载计数,成本可能会非常高。您可以改为维护一个累计计数,在每次下载时对其进行更新,并以支持高效查询的方式存储该计数。
采用预先计算聚合的原因
有多种方法可以计算聚合。下表比较了常见的备用方案,并解释了为什么通常 DynamoDB 中的实体化聚合最适合此类使用案例。
| 方法 | 权衡 | 何时使用 |
|---|---|---|
| 读取时扫描并计数 | 需要在每次查询时读取所有下载记录。延迟会随着数据量的增长而增加,并且会消耗大量读取容量。 | 仅适用于非常小的数据集,此时不会有多少延迟影响。 |
| 外部聚合存储(例如,Amazon ElastiCache) | 使用单独的服务进行管理,增加了操作复杂性。DynamoDB 与缓存之间需要同步逻辑。 | 需要亚毫秒级读取时,或者使用的复杂聚合逻辑超出了简单计数时。 |
| 写入时的应用程序级别聚合 | 聚合逻辑与写入路径相耦合。如果在记录下载后但在更新计数之前,应用程序出现故障,则聚合结果将变得不一致。 | 需要同步的强一致性聚合并且可以容忍增加的写入延迟时。 |
| 使用 Streams 和 Lambda 的实体化聚合 | 聚合与写入路径相分离。聚合具有最终一致性(通常落后几秒钟)。增加 Lambda 调用成本。 | 需要具有低读取延迟且可以容忍最终一致性的近实时聚合时。这是本页上介绍的方法。 |
实体化聚合方法保持了简单的写入路径(只需记录下载),将聚合过程分载到异步流程,并将结果存储在 DynamoDB 中,这样就可以实现延迟为个位数毫秒级的查询。
表设计
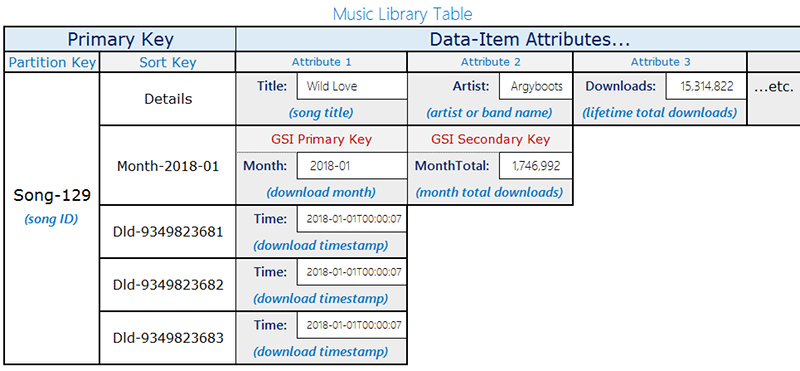
此设计使用具有两种项目类型的单个表,这些项目共享相同的分区键 (songID),但使用不同的排序键模式来区分它们:
下载记录:单独的下载事件。排序键是
DownloadID(每次下载的唯一标识符)。每月聚合项目:每个月每首歌曲的预先计算下载计数。排序键是月份,采用
YYYY-MM格式(例如,2018-01)。这些项目还包含DownloadCount属性,提供累计总数。
只有每月聚合项目包含 Month 属性。这种区别对于后文介绍的稀疏 GSI 设计很重要。
下图显示了具有这两种项目类型的表布局:
| 项目类型 | 分区键(songID) | 排序键 | 其它属性 |
|---|---|---|---|
| 下载记录 | song1 |
download-abc123 |
UserID, Timestamp |
| 每月聚合 | song1 |
2018-01 |
Month=2018-01,
DownloadCount=1,746,992 |
使用 Streams 和 Amazon Lambda 的聚合管道
聚合管道的工作方式如下:
下载歌曲后,应用程序会向表中写入一个新项目,其
Partition-Key=songID且Sort-Key=DownloadID。DynamoDB Streams 将此写入捕获为流记录。
附加到流的 Lambda 函数处理新记录。该函数识别
songID和当前月份,然后通过递增DownloadCount属性来更新对应的每月聚合项目。接下来,更新后的聚合项目可通过稀疏 GSI 进行查询。
Lambda 函数使用带有 ADD 表达式的 UpdateItem 调用,以原子方式增加下载计数。这样可以避免“读取-修改-写入”争用情况:
import boto3 dynamodb = boto3.resource('dynamodb') table = dynamodb.Table('MusicLibrary') def handler(event, context): for record in event['Records']: if record['eventName'] == 'INSERT': new_image = record['dynamodb']['NewImage'] song_id = new_image['songID']['S'] # Derive the month from the download timestamp timestamp = new_image['Timestamp']['S'] month = timestamp[:7] # Extract YYYY-MM table.update_item( Key={ 'songID': song_id, 'SK': month }, UpdateExpression='ADD DownloadCount :inc SET #m = :month', ExpressionAttributeNames={ '#m': 'Month' }, ExpressionAttributeValues={ ':inc': 1, ':month': month } )
注意
如果在写入更新后的聚合值之后,Lambda 执行失败,则可能会重试流记录。由于 ADD 操作在每次运行时都会增加计数,因此对于同一次下载,重试会多次导致增加计数,从而给出一个近似值。对于大多数分析和排行榜使用案例来说,这种细小的误差幅度是可以接受的。如果您需要精确的计数,则可以考虑添加幂等性逻辑,例如,使用条件表达式来检查是否已经处理了特定的 DownloadID。
稀疏 GSI 设计
要高效地查询聚合结果,请使用以下键架构创建全局二级索引:
GSI 分区键:
Month(字符串)GSI 排序键:
DownloadCount(数字)
此 GSI 是稀疏的,因为只有每月聚合项目包含 Month 属性。单独的下载记录没有此属性,因此会自动从索引中排除。这意味着 GSI 仅包含预先计算的聚合项目,而这只是表中总项目的一小部分。
稀疏 GSI 有两个主要优点:
更低的成本:由于仅将聚合项目复制到索引,因此与包含表中所有项目的索引相比,您消耗的写入容量和存储空间要少得多。
更快的查询:索引仅包含您需要查询的数据,因此读取效率很高,并且能够以个位数毫秒级的延迟返回结果。
有关稀疏索引工作原理的更多信息,请参阅利用稀疏索引。
查询 GSI
在采用了稀疏 GSI 之后,您可以高效地处理多种类型的查询:
获取给定月份下载次数最多的歌曲:
aws dynamodb query \ --table-name "MusicLibrary" \ --index-name "MonthDownloadsIndex" \ --key-condition-expression "#m = :month" \ --expression-attribute-names '{"#m": "Month"}' \ --expression-attribute-values '{":month": {"S": "2018-01"}}' \ --scan-index-forward false \ --limit 1
将 ScanIndexForward 设置为 false,可以按 DownloadCount 的降序顺序对结果进行排序,使用 Limit=1 可以仅返回排名第一的歌曲。
获取给定月份排名前 10 的歌曲:
aws dynamodb query \ --table-name "MusicLibrary" \ --index-name "MonthDownloadsIndex" \ --key-condition-expression "#m = :month" \ --expression-attribute-names '{"#m": "Month"}' \ --expression-attribute-values '{":month": {"S": "2018-01"}}' \ --scan-index-forward false \ --limit 10
获取给定月份内的所有歌曲下载量(按下载次数排序):
aws dynamodb query \ --table-name "MusicLibrary" \ --index-name "MonthDownloadsIndex" \ --key-condition-expression "#m = :month" \ --expression-attribute-names '{"#m": "Month"}' \ --expression-attribute-values '{":month": {"S": "2018-01"}}' \ --scan-index-forward false
注意事项
实施此模式时,请记住以下几点:
最终一致性:聚合值通过 DynamoDB Streams 和 Lambda 异步更新。从记录下载到更新聚合,通常会有几秒的延迟。这意味着 GSI 反映的是近实时数据,而不是实时数据。
Lambda 并发性:如果表具有较高的写入量,则多个 Lambda 调用可能会尝试同时更新同一个聚合项目。原子性
ADD操作可以安全地处理这种情况,但您应该监控 Lambda 的并发度和节流指标,以确保函数能够满足流式处理的速度。GSI 写入容量:由于稀疏 GSI 仅包含聚合项目,因此所需的写入容量要比基表少得多。但是,您仍应预调配足够的容量(或使用按需模式)来应对聚合更新的速度。
近似计数:如前所述,Lambda 重试可能会导致计数略微过多。对于需要精确计数的使用案例,请在 Lambda 函数中实施幂等性检查。