在 DynamoDB 中建模关系数据的最佳实践
本节提供了在 Amazon DynamoDB 中对关系数据建模的最佳实践。首先,我们介绍传统的数据建模概念。然后,我们将介绍使用 DynamoDB 相对于传统关系数据库管理系统的优势 – 它如何消除对 JOIN 操作的需求并减少开销。
然后,我们将解释如何设计可高效扩展的 DynamoDB 表。最后,我们提供一个如何在 DynamoDB 中对关系数据进行建模的示例。
主题
传统的关系数据库模型
传统关系数据库管理系统(RDBMS)在规范化关系结构中存储数据。关系数据模型的目标是(通过规范化)减少数据重复,支持引用完整性并减少数据异常。
以下模式是通用订单输入应用程序的关系数据模型示例。该应用程序支持一种人力资源模式,此模式为理论制造商的运营和业务支持系统提供大力支持。
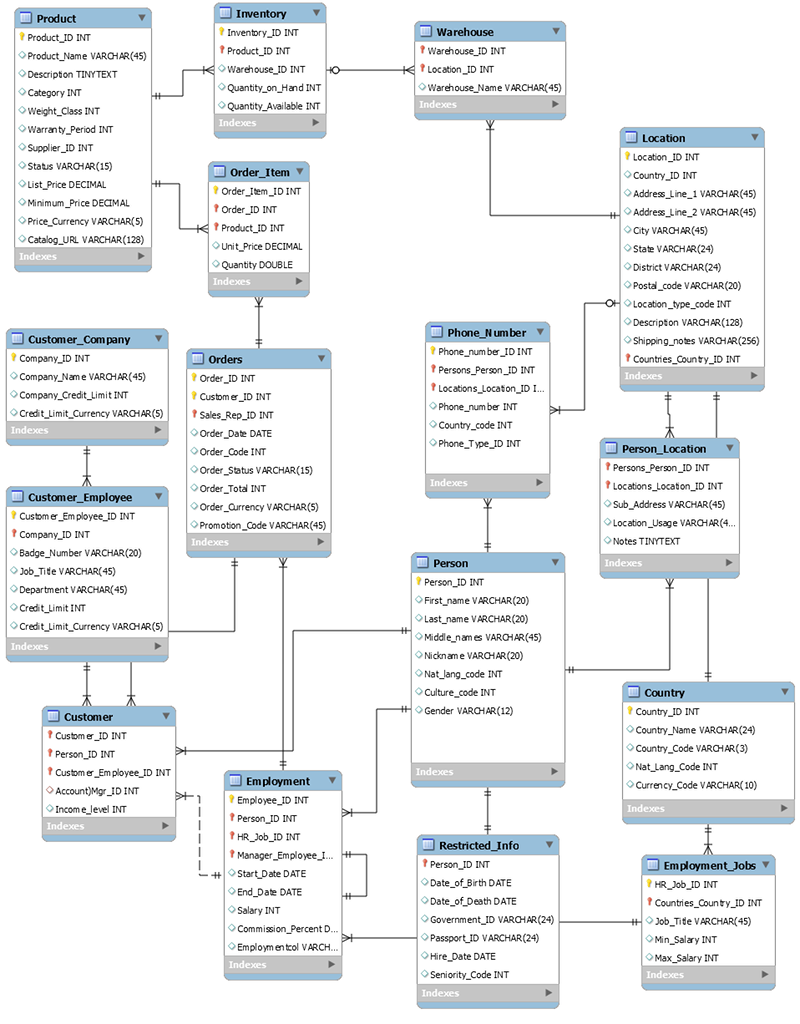
作为一种非关系数据库服务,与传统的关系数据库管理系统相比,DynamoDB 具有许多优势。
DynamoDB 如何消除对 JOIN 操作的需求
RDBMS 使用结构查询语言(SQL)将数据返回到应用程序。由于数据模型的规范化,此类查询通常需要使用 JOIN 运算符来合并来自一个或多个表的数据。
例如,要生成按照可发运每个项目的所有仓库库存数量排序的采购订单项目列表,可以对上述架构发出下面的 SQL 查询。
SELECT * FROM Orders
INNER JOIN Order_Items ON Orders.Order_ID = Order_Items.Order_ID
INNER JOIN Products ON Products.Product_ID = Order_Items.Product_ID
INNER JOIN Inventories ON Products.Product_ID = Inventories.Product_ID
ORDER BY Quantity_on_Hand DESC这种 SQL 查询可提供用于访问数据的灵活 API,但需要大量处理。查询中的每个联接都会增加查询的运行时复杂性,因为每个表的数据都必须暂存,然后汇集才能返回结果集。
可能影响查询运行时间的其它因素包括表的大小以及所联接的列是否有索引。上述查询对多个表发起复杂查询,然后对结果集进行排序。
消除对 JOINs 的需求是 NoSQL 数据建模的核心所在。这就是我们构建 DynamoDB 来支持 Amazon.com 的原因,也是 DynamoDB 在任何规模都能提供一致性能的原因。考虑到 SQL 查询和 JOINs 的运行时复杂性,RDBMS 的性能在大规模情况下并不稳定。随着客户应用程序的增长,这会导致性能问题。
虽然规范化数据确实减少了存储到磁盘的数据量,但影响性能的最受限制的资源通常是 CPU 时间和网络延迟。
DynamoDB 旨在消除 JOINs(并鼓励数据非规范化)和优化数据库架构,通过对某项目的单个请求来完全回答应用程序查询,从而最大限度地减少这两种限制。这些特性使 DynamoDB 能够在任何规模上提供个位数、毫秒级的性能。这是因为对于常见的访问模式,无论数据大小如何,DynamoDB 操作的运行时复杂度都是恒定的。
DynamoDB 事务如何消除写入进程的开销
另一个可能减慢 RDBMS 速度的因素是利用事务写入到规范化模式。如示例所示,大多数在线事务处理 (OLTP) 应用程序使用的关系数据结构存储在 RDBMS 中时,必须分解并分布在多个逻辑表中。
因此,需要一个符合 ACID 的事务框架,避免应用程序尝试读取正在写入的对象时可能发生的争用情况和数据完整性问题。此类事务框架与关系架构相结合,会大幅增加写入进程的开销。
在 DynamoDB 中实现事务可以防止 RDBMS 中发现的常见扩展问题。为此,DynamoDB 将事务作为单个 API 调用发出,并限制该单个事务中可以访问的项目数量。长时间运行的事务可能会由于长时间或永久锁定数据而导致操作问题,因为事务从不会关闭。
为了防止在 DynamoDB 中出现此类问题,使用以下两个不同的 API 操作实现事务:TransactWriteItems 和 TransactGetItems。这些 API 操作不具有 RDBMS 中常见的开始和结束语义。此外,DynamoDB 还有一个事务内 100 个项目的访问限制,以便以类似方式防止长时间运行的事务。要了解有关 DynamoDB 事务的更多信息,请参阅处理事务。
为此,如果业务需要低延迟响应高流量查询,采用 NoSQL 系统通常具有技术和经济意义。Amazon DynamoDB 可以避免这些限制,帮助解决问题。
RDBMS 的性能因为下列原因通常无法正常扩展:
-
使用成本高昂的连接,重新组织需要的查询结果视图。
-
规范化数据并存储在多个表中,需要多个查询以写入磁盘。
-
通常产生 ACID 合规事务系统的性能成本。
DynamoDB 可以正常扩展的原因包括:
-
架构灵活性支持 DynamoDB 在单个项目内存储复杂层次数据。
-
复合键设计支持将相关项目一起存储在同一个表。
-
事务是在单个操作中执行的。可以访问的项目数量限制为 100,以避免长时间运行的操作。
针对数据存储的查询变得简单得多,通常采用以下形式:
SELECT * FROM Table_X WHERE Attribute_Y = "somevalue"
与前面示例中的 RDBMS 相比,DynamoDB 可以更轻松返回请求的数据。