DynamoDB 中的数据建模基础
本节介绍基础层,首先探讨两种类型的表设计:单表和多表。
单表设计基础
对于 DynamoDB 架构的基础,一个选择是单表设计。单表设计模式让您可以在单个 DynamoDB 表中存储多种类型(实体)的数据。这种模式消除了维护多个表及其之间的复杂关系的需求,从而优化数据访问模式、提升性能并降低成本。能够做到这一点,是因为 DynamoDB 将具有相同分区键的项目(称为项目集合)分别存储在相同的分区上。在这种设计中,不同类型的数据作为项目存储在同一个表中,每个项目由唯一的排序键标识。
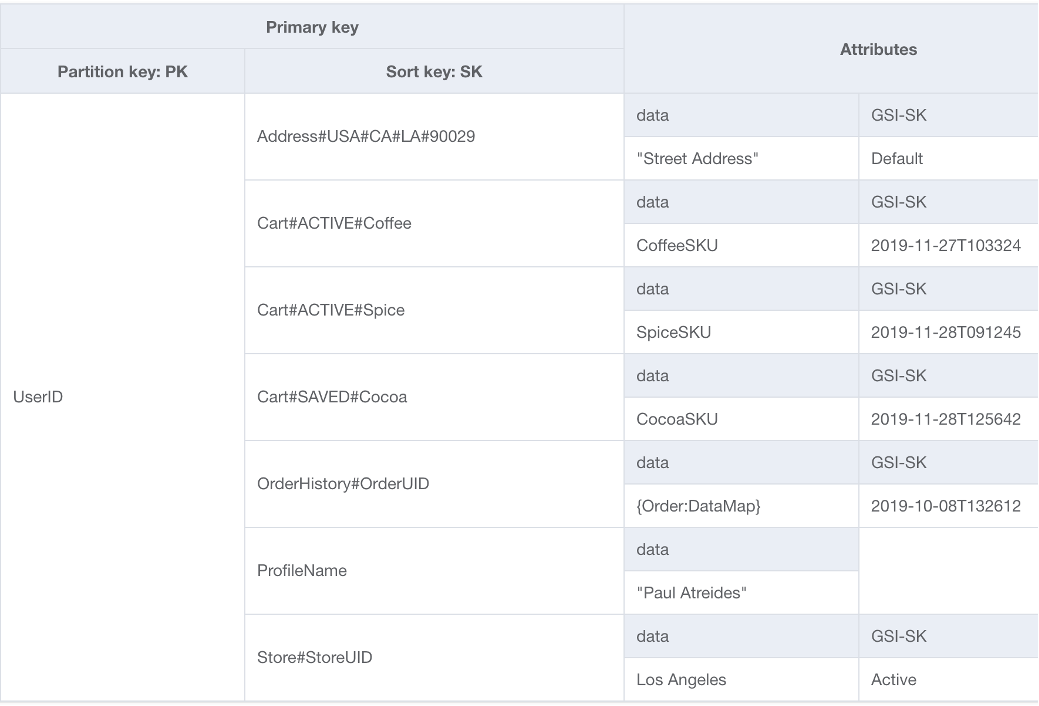
优势:
-
数据局部性,支持在一个数据库调用中查询多种实体类型
-
降低读取操作的整体费用成本和延迟成本:
-
采用最终一致性模式,对两个大小总计小于 4KB 的项目执行单次查询的成本为 0.5 RCU
-
采用最终一致性模式,对两个大小总计小于 4KB 的项目执行两次查询的成本为 1 RCU(每次 0.5 RCU)
-
返回两次单独的数据库调用的时间平均要长于一次调用的时间
-
-
减少要管理的表的数量:
-
无需在多个 IAM 角色或 IAM 策略之间维护权限
-
表的容量管理在所有实体之间平均分布,这通常可以让使用模式更好预测
-
进行监控所需的警报更少
-
只需在一个表上轮换客户托管加密密钥
-
-
让流向表的流量变得平滑:
-
通过将多种使用模式聚合到同一个表,总体使用情况会趋向于更平滑(就如同股票指数的表现往往比任何单个股票都更平滑),这有助于在预置模式表中可以更好地实现更高的利用率
-
缺点
-
与关系数据库相比,由于矛盾的设计,学习曲线可能很陡峭
-
所有实体类型的数据要求必须一致
-
要么全部备份,要么都不备份,因此如果某些数据无关紧要,请考虑将其放在单独的表中
-
所有项目共享表加密。对于具有单个租户加密要求的多租户应用程序,需要进行客户端加密
-
对于混合了历史数据和运营数据的表而言,在启用不频繁访问存储类时不会获得太多益处。有关更多信息,请参阅 DynamoDB 表类。
-
-
即使只需要处理一部分实体,也会将所有更改的数据都传播到 DynamoDB Streams。
-
得益于 Lambda 事件筛选条件,在使用 Lambda 时这不会影响您的账单,但在使用 Kinesis Consumer Library 时会增加成本
-
-
使用 GraphQL 时,单表设计将更难实施
-
使用更高级别的 SDK 客户端(如 Java DynamoDBMapper 或 增强型客户端)时,处理结果可能更加困难,因为同一个响应中的项目可能与不同的类相关联
何时使用:
对于那些经常同时查询多个实体类型或需要维护不同数据类型之间关系的应用程序,单表设计非常适合。当访问模式受益于数据局部性时,以及当您希望最大限度地减少管理多个表的开销时,单表设计尤其有效。
多表设计基础
对于 DynamoDB 架构的基础,第二个选择是多表设计。多表设计模式更像是传统数据库设计,在这种模式下,您在每个 DynamoDB 表中存储单一类型(实体)的数据。每个表中的数据仍按分区键组织,因此可以针对可扩展性和性能对单个实体类型的性能进行优化,但是跨多个表的查询必须独立完成。
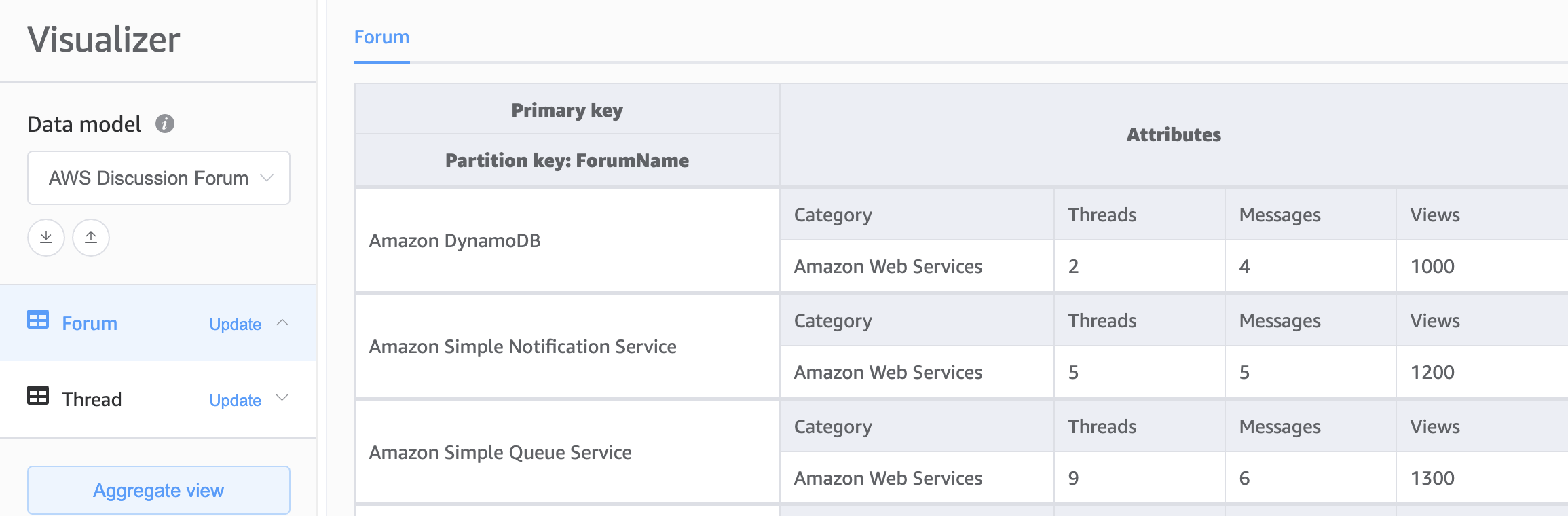
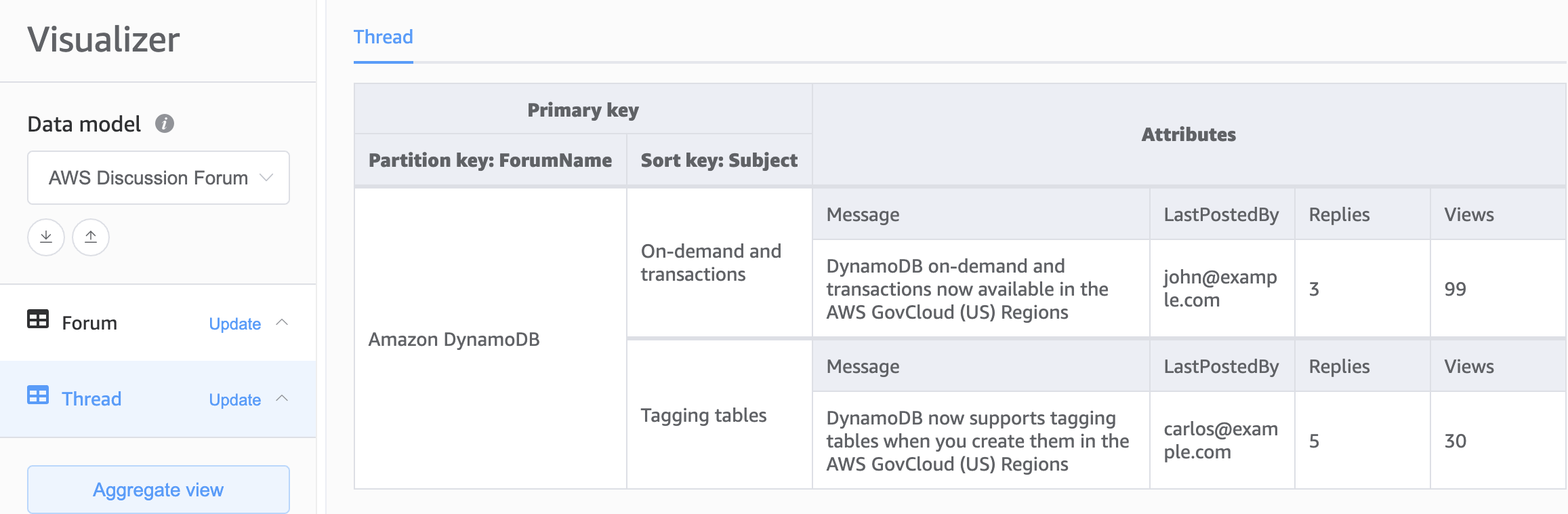
优点
-
对于那些不习惯使用单表设计的用户而言,此模式设计起来更简单
-
由于每个解析器都映射到单个实体(表),因此更容易实施 GraphQL 解析器
-
允许跨不同实体类型实现独特数据要求:
-
可以对单独的任务关键型表进行备份
-
可以分别管理各个表的表加密。对于具有单独租户加密要求的多租户应用程序,通过使用单独的租户表,每个客户都可以拥有自己的加密密钥
-
可以仅在存储历史数据的表上启用不频繁访问存储类,从而实现充分的成本节约益处。有关更多信息,请参阅 DynamoDB 表类。
-
-
每个表都有自己的更改数据流,这样便可以为每种类型的项目设计专用的 Lambda 函数,而不是采用单个的整体式处理程序
缺点
-
对于需要多个表中数据的访问模式,将需要从 DynamoDB 进行多次读取,并且可能需要通过客户端代码来处理/联接数据。
-
多个表的操作和监控需要更多 CloudWatch 警报,并且每个表必须独立扩展
-
每个表的权限都需要单独管理。以后添加表时需要更改任何必要的 IAM 角色或 IAM 策略
何时使用:
如果您的应用程序的访问模式不需要同时查询多个实体或表,那么多表设计是一种不错且足够的方法。