DynamoDB 中的游戏个人资料架构设计
游戏个人资料业务使用场景
此使用场景探讨使用 DynamoDB 来存储游戏系统的玩家个人资料。许多现代游戏,尤其是在线游戏,需要用户(在本例中为玩家)先创建个人资料,然后才能玩游戏。游戏个人资料通常包括以下内容:
-
基本信息,例如玩家的用户名
-
游戏数据,例如物品和装备
-
游戏记录,例如任务和活动
-
社交信息,例如好友名单
为了满足此应用程序的细粒度数据查询访问要求,主键(分区键和排序键)将使用通用名称(PK 和 SK),因此它们可能会使用各种类型的值重载,如下所示。
此架构设计的访问模式为:
-
获取用户的好友名单
-
获取玩家的所有信息
-
获取用户的物品清单
-
从用户的物品清单中获取特定物品
-
更新用户的角色
-
更新用户的物品数量
在不同的游戏中,游戏个人资料的大小会有所不同。压缩大型属性值可以让属性值符合 DynamoDB 的项目限制,从而降低成本。吞吐量管理策略取决于多种因素,例如:玩家数量、每秒玩的游戏数量以及工作负载的季节性。通常,对于新推出的游戏,玩家数量和受欢迎程度是未知的,因此我们一开始使用按需吞吐量模式。
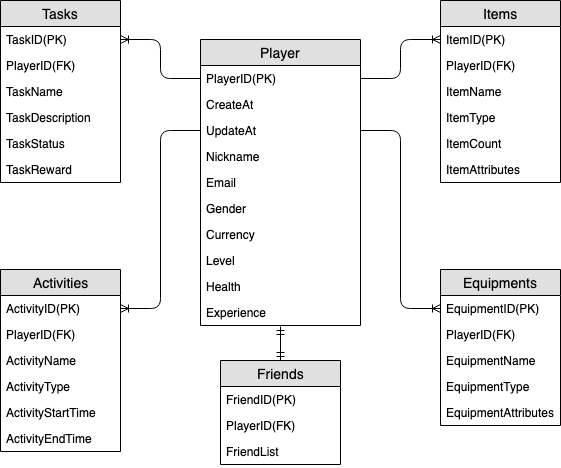
游戏个人资料实体关系图
这是我们在游戏个人资料架构设计中使用的实体关系图(ERD)。
游戏个人资料访问模式
我们将为社交网络架构设计考虑这些访问模式。
-
getPlayerFriends -
getPlayerAllProfile -
getPlayerAllItems -
getPlayerSpecificItem -
updateCharacterAttributes -
updateItemCount
游戏个人资料架构设计演变
从上面的 ERD 可以看出,这是一对多关系类型的数据建模。在 DynamoDB 中,一对多数据模型可以整理为项目集合,这不同于通过创建多个表并使用外键来链接的传统关系数据库。项目集合是一组共享相同分区键值但具有不同排序键值的项目。在项目集合中,每个项目都有一个唯一的排序键值,该值将其与其他项目区分开来。考虑到这一点,我们可以为每种实体类型的 HASH 和 RANGE 值使用以下模式。
首先,我们使用 PK 和 SK 等通用名称,将不同类型的实体存储在同一个表中,以便模型可供未来使用。为了提高可读性,我们可以添加前缀来表示数据的类型,也可以提供名为 Entity_type 或 Type 的任意属性。在当前示例中,我们使用以 player 开头的字符串,将 player_ID 存储为 PK;将 entity name# 用作 SK 的前缀,然后添加一个 Type 属性来指示这段数据所属的实体类型。这样,我们以后便能够支持存储更多的实体类型,并使用 GSI 重载和稀疏 GSI 等高级技术来满足更多的访问模式。
让我们开始实施访问模式。添加玩家和添加装备等访问模式可以通过 PutItem 操作实现,因此我们可以忽略这些访问模式。在本文中,我们将重点介绍上面列出的典型访问模式。
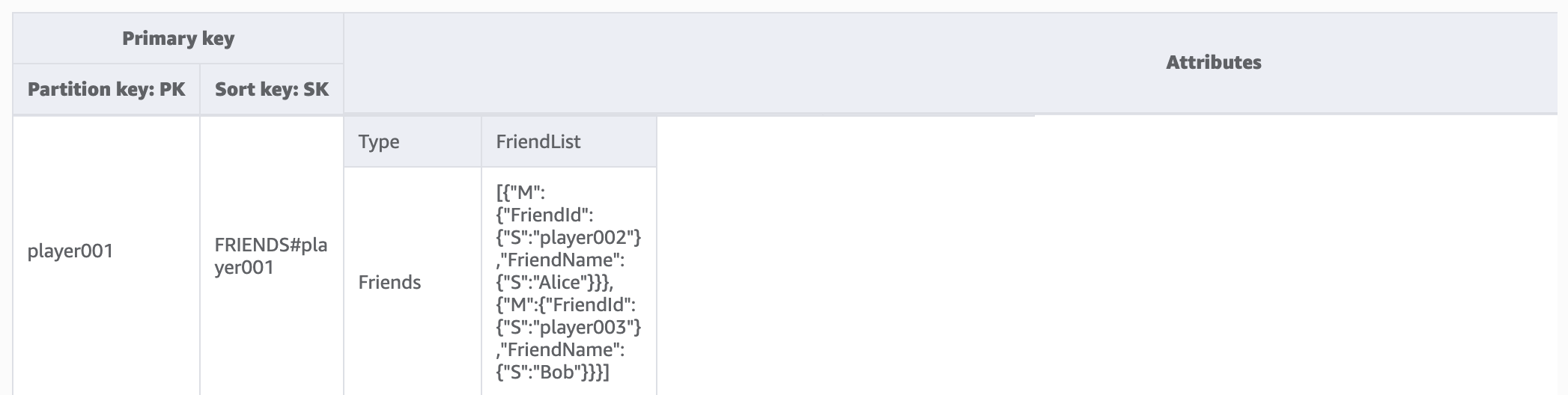
步骤 1:解决访问模式 1 (getPlayerFriends)
我们通过此步骤解决访问模式 1 (getPlayerFriends)。在我们目前的设计中,好友关系很简单,游戏中的好友数量很少。为简单起见,我们使用列表数据类型来存储好友列表(1:1 建模)。在此设计中,我们使用 GetItem 来满足这种访问模式。在 GetItem 操作中,我们明确提供分区键和排序键值以获取特定项目。
但是,如果某个游戏中有大量好友,并且他们之间的关系很复杂(例如好友关系是双向的,包括邀请和接受组件),则必须使用多对多关系来单独存储每个好友,这样才能扩展到大小不受限的好友名单。而且,如果好友关系变更涉及同时对多个项目进行操作,则可以使用 DynamoDB 事务将多个操作分组在一起,并将它们作为“全有或全无”的单个 TransactWriteItems 或 TransactGetItems 操作提交。
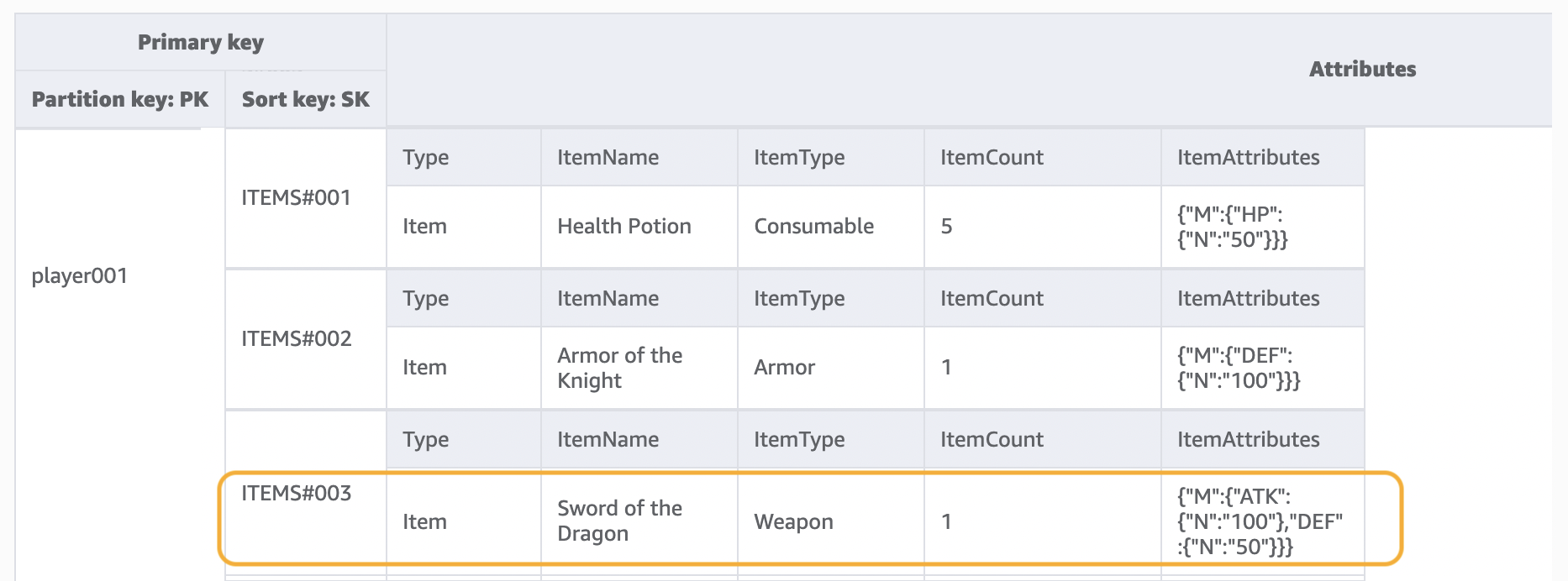
步骤 2:解决访问模式 2 (getPlayerAllProfile)、3 (getPlayerAllItems) 和 4 (getPlayerSpecificItem)
我们使用此步骤解决访问模式 2 (getPlayerAllProfile)、3 (getPlayerAllItems) 和 4 (getPlayerSpecificItem)。这三种访问模式的共同点是使用 Query 操作进行范围查询。根据查询的范围,使用键条件和筛选表达式,这些方法在实际开发中经常使用。
在查询操作中,我们为分区键提供一个值,然后获取具有该分区键值的所有项目。访问模式 2 (getPlayerAllProfile) 以这种方式实施。或者,我们可以添加排序键条件表达式,这是一个字符串,用于确定要从表中读取的项目。访问模式 3 (getPlayerAllItems) 通过添加键条件排序键 begins_with ITEMS# 来实施。此外,为了简化应用程序端的开发,我们可以使用筛选条件表达式来实施访问模式 4 (getPlayerSpecificItem)。
以下是使用筛选条件表达式筛选 Weapon 类别项目的伪代码示例:
filterExpression: "ItemType = :itemType" expressionAttributeValues: {":itemType": "Weapon"}
注意
筛选表达式在查询已完成但结果尚未返回到客户端时应用。因此,无论是否存在筛选表达式,查询都将占用同等数量的读取容量。
如果访问模式是查询大型数据集,需要筛选掉大量数据,仅保留一小部分数据,则合适的方法是设计更有效的 DynamoDB 分区键和排序键。例如,在上面的获取特定 ItemType 的示例中,如果每个玩家都有很多物品并且典型的访问模式是查询特定的 ItemType,那么将 ItemType 引入 SK 中作为复合键会更有效率。数据模型类似于以下所示:ITEMS#ItemType#ItemId。
步骤 3:解决访问模式 5 (updateCharacterAttributes) 和 6 (updateItemCount)
我们使用此步骤解决访问模式 5 (updateCharacterAttributes) 和 6 (updateItemCount)。当玩家需要修改角色时,例如减少货币或修改其物品中特定武器的数量,可以使用 UpdateItem 来实施这些访问模式。在更新玩家货币时,为了确保金额永远不会低于最低数量,我们可以添加一个 DynamoDB 条件表达式 CLI 示例,确保只有其大于或等于最低金额时才减少余额。以下是伪代码示例:
UpdateExpression: "SET currency = currency - :amount" ConditionExpression: "currency >= :minAmount"

在使用 DynamoDB 进行开发并使用原子计数器减少库存时,我们可以通过使用乐观锁来确保幂等性。以下是原子计数器的伪代码示例:
UpdateExpression: "SET ItemCount = ItemCount - :incr" expression-attribute-values: '{":incr":{"N":"1"}}'

此外,在玩家用货币购买物品的情况下,整个流程中需要扣除货币并同时添加物品。我们可以使用 DynamoDB 事务将多个操作分组在一起,并将它们作为“全有或全无”的单个 TransactWriteItems 或 TransactGetItems 操作提交。TransactWriteItems 是同步的幂等性写入操作,可将最多 100 个写入操作分组到一个“全有或全无”操作中。这些操作以原子方式完成,以便所有操作都成功或都失败。事务有助于消除重复或货币消失的风险。有关事务的更多信息,请参阅DynamoDB 事务示例。
下表总结了所有访问模式以及架构设计如何解决访问模式:
| 访问模式 | 基表/GSI/LSI | 操作 | 分区键值 | 排序键值 | 其他条件/筛选条件 |
|---|---|---|---|---|---|
| getPlayerFriends | 基表 | GetItem | PK=PlayerID | SK=“FRIENDS#playerID” | |
| getPlayerAllProfile | 基表 | Query | PK=PlayerID | ||
| getPlayerAllItems | 基表 | Query | PK=PlayerID | SK begins_with “ITEMS#” | |
| getPlayerSpecificItem | 基表 | Query | PK=PlayerID | SK begins_with “ITEMS#” | filterExpression: "ItemType = :itemType" expressionAttributeValues: { ":itemType": "Weapon" } |
| updateCharacterAttributes | 基表 | UpdateItem | PK=PlayerID | SK=“#METADATA#playerID” | UpdateExpression: "SET currency = currency - :amount" ConditionExpression: "currency >= :minAmount" |
| updateItemCount | 基表 | UpdateItem | PK=PlayerID | SK =“ITEMS#ItemID” | update-expression: "SET ItemCount = ItemCount - :incr" expression-attribute-values: '{":incr":{"N":"1"}}' |
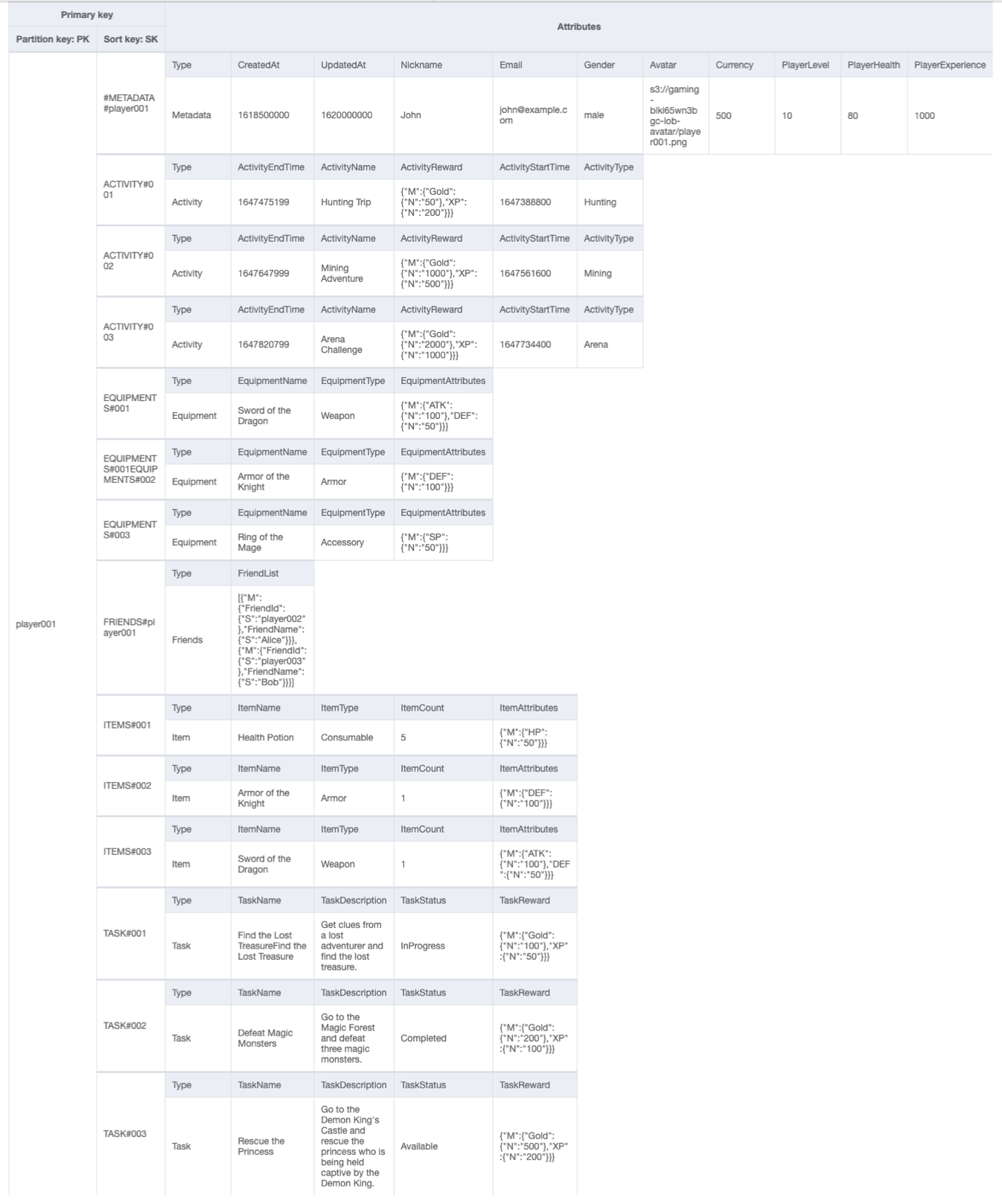
游戏个人资料最终架构
这是最终的架构设计。要以 JSON 文件格式下载此架构设计,请参阅 GitHub 上的 DynamoDB 示例
基表:
在此架构设计中使用 NoSQL Workbench
若要进一步探索和编辑新项目,您可以将此最终架构导入到 NoSQL Workbench,这是一款为 DynamoDB 提供数据建模、数据可视化和查询开发功能的可视化工具。请按照以下步骤开始使用:
-
下载 NoSQL Workbench。有关更多信息,请参阅 下载 NoSQL Workbench for DynamoDB。
-
下载上面列出的 JSON 架构文件,该文件已经采用 NoSQL Workbench 模型格式。
-
将 JSON 架构文件导入到 NoSQL Workbench。有关更多信息,请参阅 导入现有数据模型。
-
导入到 NOSQL Workbench 后,您便可编辑数据模型。有关更多信息,请参阅 编辑现有数据模型。