配置 DAX 集群
DAX 集群是一个托管集群,但您可以调整其配置以满足您的应用程序要求。由于它与 DynamoDB API 操作紧密集成,因此在将您的应用程序与 DAX 集成时,应考虑以下几个方面。
DAX 定价
集群的成本取决于其预调配的节点的数量和大小。每个节点按其在集群中运行的小时数计费。有关更多信息,请参阅 Amazon DynamoDB 定价
缓存命中不会产生 DynamoDB 成本,但会影响 DAX 集群资源。缓存未命中会产生 DynamoDB 读取成本,并需要 DAX 资源。写入会产生 DynamoDB 写入成本,并影响用于代理写入的 DAX 集群资源。
项目缓存和查询缓存
DAX 能够维护项目缓存和查询缓存。了解这些缓存之间的差异可以帮助您确定它们为应用程序提供的性能和一致性特征。
| 缓存特性 | 项目缓存 | 查询缓存 |
|---|---|---|
|
用途 |
存储 GetItem 和 BatchGetItem API 操作的结果。 |
|
|
访问类型 |
使用基于键的访问权限。 当应用程序使用 |
使用基于参数的访问权限。 DAX 会缓存 |
|
缓存失效 |
在以下情况下,DAX 会自动将更新的项目复制到 DAX 集群中节点的项目缓存中:
|
查询缓存比项目缓存更难失效。项目更新可能不会直接映射到缓存的查询或扫描。您必须仔细调整查询缓存 TTL 以保持数据一致性。在 TTL 使以前缓存的响应失效,以及 DAX 对 DynamoDB 执行新的查询之前,通过 DAX 或基表执行的写入不会反映在查询缓存中。 |
|
全局二级索引 |
由于本地二级索引或全局二级索引不支持 GetItem API 操作,因此项目缓存仅缓存从基表读取的内容。 |
查询缓存会缓存针对表和索引的查询。 |
为缓存选择 TTL 设置
TTL 决定了数据在过时之前存储在缓存中的时间段。在此时间段之后,数据将在下次请求时自动刷新。为 DAX 缓存选择正确的 TTL 设置时,需要在应用程序性能优化和数据一致性之间取得平衡。由于不存在适用于所有应用程序的通用 TTL 设置,因此最佳 TTL 设置会因应用程序的具体特征和要求而有所不同。建议您首先使用此规范性指南,设置保守的 TTTTL 设置。然后,根据应用程序的性能数据和见解以迭代方式调整 TTL 设置。
DAX 将保留项目缓存的最近最少使用的(LRU)列表。该 LRU 列表会跟踪项目首次写入缓存或最后一次从缓存中读取项目的时间。如果 DAX 节点内存已满,DAX 将逐出较旧的项目(即使其尚未过期),为新项目腾出空间。将始终启用 LRU 算法,用户无法配置。
若要设置适用于应用程序的 TTL 持续时间,请考虑以下几点:
了解数据访问模式
-
读取密集型工作负载 – 对于具有读取密集型工作负载且数据更新不频繁的应用程序,请设置更长的 TTL 持续时间以减少缓存未命中几率。更长的 TTL 持续时间还可以减少访问底层 DynamoDB 表的需求。
-
写入密集型工作负载 – 对于更新频繁且不是通过 DAX 写入的应用程序,请设置较短的 TTL 持续时间,以确保缓存与数据库保持一致。更短的 TTL 持续时间还可以降低提供陈旧数据的风险。
评估应用程序的性能要求
-
延迟敏感度 - 如果您的应用程序需要低延迟而不是数据新鲜度,请使用更长的 TTL 持续时间。较长的 TTL 持续时间可最大限度提高缓存命中率,从而降低平均读取延迟。
-
吞吐量和可扩展性 – 更长的 TTL 持续时间可减少 DynamoDB 表的负载,并提高吞吐量和可扩展性。不过,您应在这一方面与对最新数据的需求之间取得平衡。
分析缓存逐出和内存使用情况
-
缓存内存限制 - 监控 DAX 集群的内存使用情况。较长的 TTL 持续时间可以在缓存中存储更多数据,这可能会达到内存限制并导致基于 LRU 的驱逐。
使用指标和监控功能来调整 TTL
定期查看指标,例如缓存命中率和未命中率以及 CPU 和内存利用率。根据这些指标调整 TTL 设置,以在性能和数据新鲜度之间取得最佳平衡。如果缓存未命中率高且内存利用率低,请延长 TTL 持续时间以提高缓存命中率。
考虑业务需求与合规性
数据保留策略可能会规定您可以为缓存敏感或个人信息设置的最长 TTL 持续时间。
将 TTL 设置为零时的缓存行为
如果将 TTL 设置为 0,项目缓存和查询缓存将表现出以下行为:
-
项目缓存 – 仅在 LRU 驱逐或直写操作发生时,才会刷新缓存中的项目。
-
查询缓存 - 不缓存查询响应。
使用 DAX 集群缓存多个表
对于具有多个不需要单独缓存的小型 DynamoDB 表的工作负载,单个 DAX 集群会缓存对这些表的请求。这使得 DAX 的使用更加灵活和高效,特别是对于访问多个表并需要高性能读取的应用程序。
与 DynamoDB 数据面板 API 类似,DAX 请求需要表名。如果您在同一 DAX 集群中使用多个表,则不需要任何特定配置。但是,必须确保集群的安全权限允许访问所有缓存表。
将 DAX 用于多个表的注意事项
在将 DAX 与多个 DynamoDB 表结合使用时,应考虑以下几点:
-
内存管理 - 将 DAX 用于多个表时,应考虑工作数据集的总大小。您的数据集中的所有表将共享与您选择的节点类型相同的内存空间。
-
资源分配 - DAX 集群的资源在所有缓存的表之间共享。但是,高流量表可能会导致从相邻的小表中驱逐数据。
-
规模经济 – 将较小的资源分组到更大的 DAX 集群中,可以对流量进行平均化,使其处于更稳定的模式。就 DAX 集群所需的读取资源总数而言,拥有三个或更多节点也是经济实惠的。这还提高了集群中所有缓存表的可用性。
DAX 和 DynamoDB 全局表中的数据复制
DAX 是一项基于区域的服务,因此集群只知道其 Amazon Web Services 区域中的流量。当全局表从另一个区域复制数据时,它们会绕过缓存,直接写入底层数据源。
较长的 TTL 持续时间可能会导致陈旧数据在辅助区域中停留的时间比在主区域中更长。这可能会导致辅助区域的本地缓存中的缓存不命中。
下图显示了源区域 A 中在全局表级别上进行的数据复制。区域 B 中的 DAX 集群并未立即意识到来自源区域 A 的新复制数据。
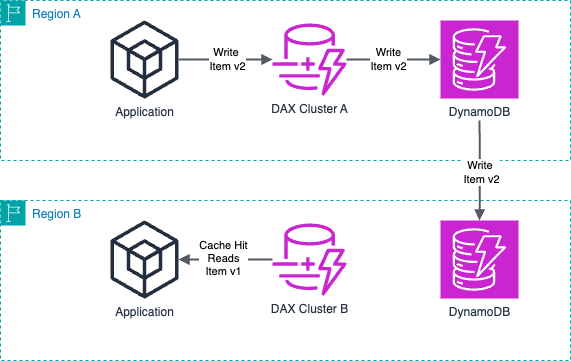
DAX 区域可用性
并非所有支持 DynamoDB 表的区域都支持部署 DAX 集群。如果您的应用程序要求通过 DAX 实现低读取延迟,请先查看支持 DAX 的区域列表。然后,为 DynamoDB 表选择区域。
DAX 缓存行为
DAX 执行元数据和逆向缓存。了解这些缓存行为将有助于您有效地管理缓存项目和逆向缓存条目的属性元数据。
-
元数据缓存 - DAX 集群无限期维护有关缓存项目的属性名称的元数据。即使在项目过期或已从缓存中逐出之后,此元数据仍会保留。
随着时间的推移,使用不限制数量的属性名称的应用程序会耗尽 DAX 集群中的内存。此限制仅适用于顶级属性名称,不适用于嵌套属性名称。不受限制的属性名称的示例包含时间戳、UUID 和会话 ID。尽管您可以使用时间戳和会话 ID 作为属性值,但建议使用更短、更加可预测的属性名称。
-
逆向缓存 – 如果出现缓存未命中且从 DynamoDB 表中读取没有产生匹配的项目,DAX 会在相应的项目或查询缓存中添加逆向缓存条目。在缓存 TTL 持续时间到期或发生直写之前,此条目将一直保留。DAX 继续返回此逆向缓存条目以供将来的请求使用。
如果逆向缓存行为不符合您的应用程序模式,请在 DAX 返回空结果时直接读取 DynamoDB 表。还建议您设置较低的 TTL 缓存持续时间,以避免缓存中出现长期的空结果,并提高与表的一致性。