本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
解析器
从前面的几节中,您了解了架构和数据来源的组件。现在,我们需要解决架构和数据来源如何交互的问题。这一切都始于解析器。
解析器是一个代码单元,可以处理向服务发出请求时如何解析该字段的数据的问题。解析器附加到架构中的您的类型内的特定字段。它们通常用于实施查询、变更和订阅字段操作的状态更改操作。解析器处理客户端的请求,然后返回结果,结果可能是一组输出类型,例如对象或标量:
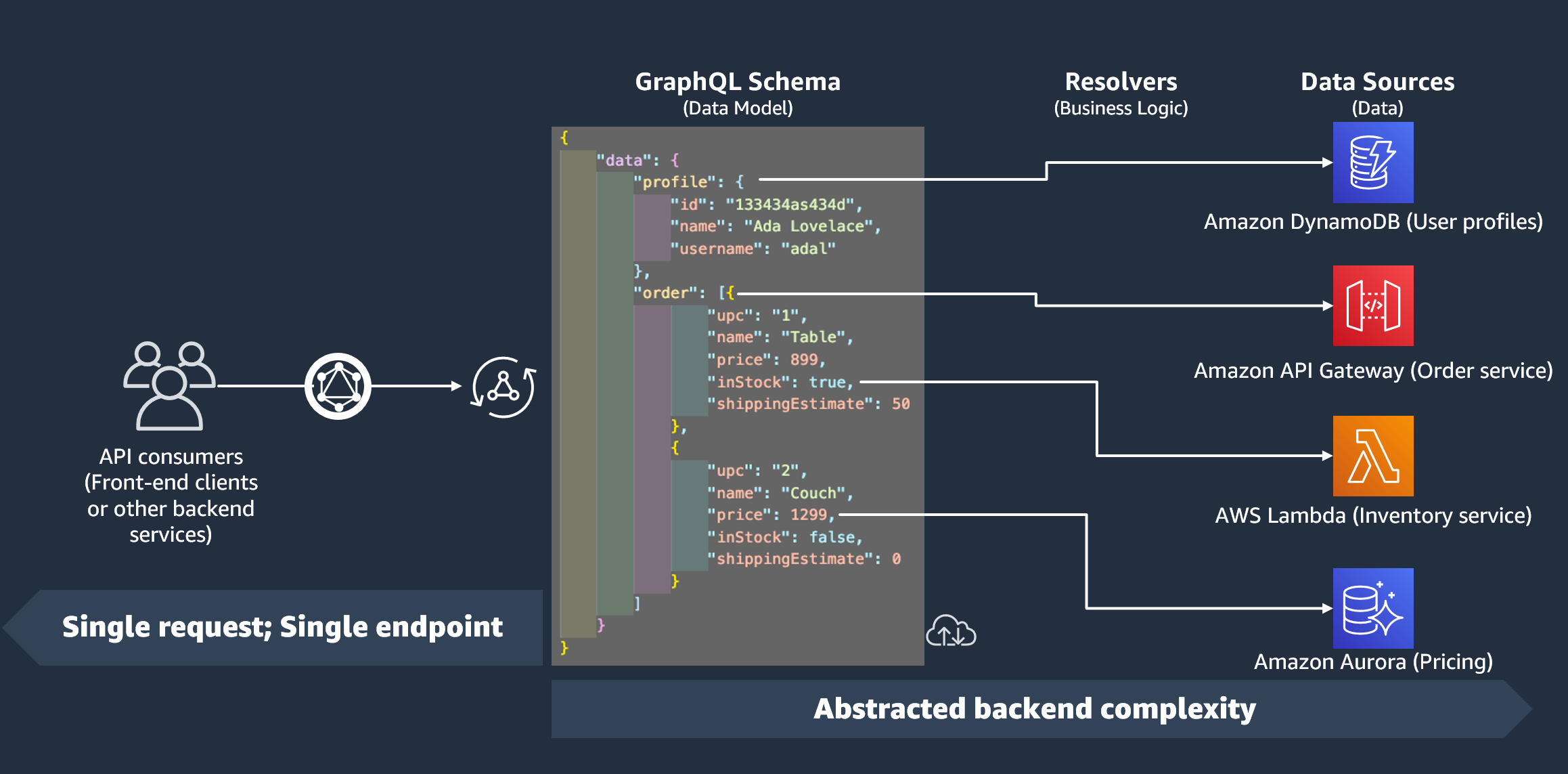
解析器运行时系统
在中 Amazon AppSync,必须先为解析器指定运行时间。解析器运行时系统表示执行解析器的环境。它还决定了你的解析器将使用的语言。 Amazon AppSync 目前支持 APPSYNC_JS JavaScript 和 Velocity 模板语言 (VTL)。参见解析器的JavaScript 运行时功能和函数 JavaScript 或 VTL 的解析器映射模板实用程序参考。
解析器结构
从代码角度看,可以通过多种方式设置解析器结构。具有单位解析器和管道解析器。
单位解析器
单位解析器由定义对数据来源执行的单个请求和响应处理程序的代码组成。请求处理程序将上下文对象作为参数,并返回用于调用数据来源的请求负载。响应处理程序接收从数据来源返回的负载以及执行的请求结果。响应处理程序将负载转换为 GraphQL 响应以解析 GraphQL 字段。
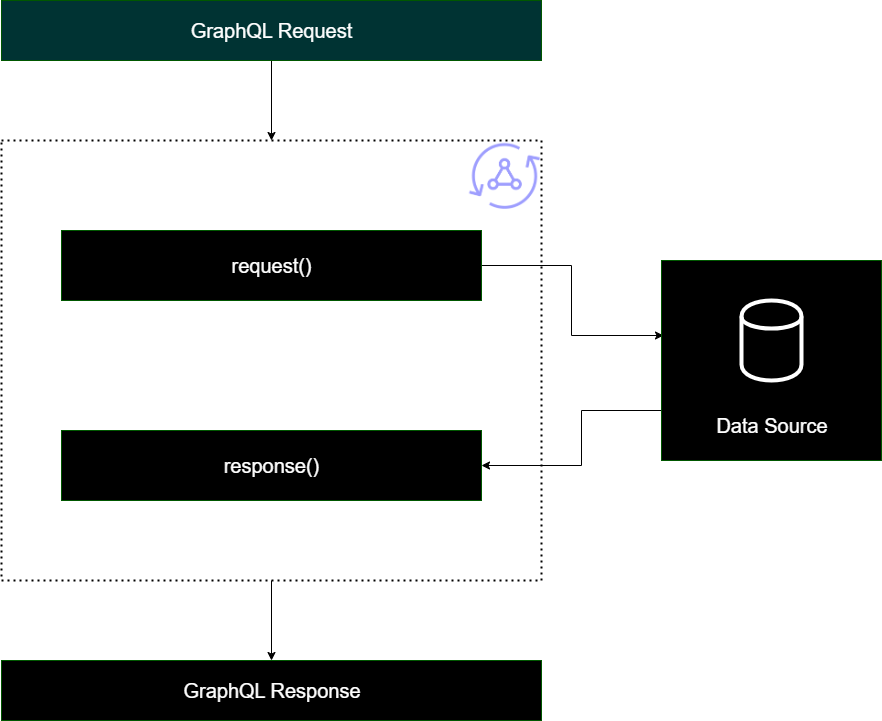
管道解析器
在实施管道解析器时,它们采用通用的结构:
-
预备步骤:在客户端发出请求时,将为使用的架构字段(通常是查询、变更、订阅)的解析器传送请求的数据。解析器开始使用预备步骤处理程序处理请求数据,该处理程序允许在数据传送到解析器之前执行一些预处理操作。
-
函数:在运行预备步骤后,请求传送到函数列表。将对数据来源执行列表中的第一个函数。函数是解析器代码的子集,其中包含自己的请求和响应处理程序。请求处理程序获取请求数据,并对数据来源执行操作。在将数据来源的响应传回到列表之前,响应处理程序对其进行处理。如果具有多个函数,请求数据将发送到列表中的下一个函数以进行执行。列表中的函数按照开发人员定义的顺序依次执行。在执行所有函数后,最终结果传送到后续步骤。
-
后续步骤:后续步骤是一个处理程序函数,允许您在将最终函数的响应传送到 GraphQL 响应之前对其执行一些最终操作。
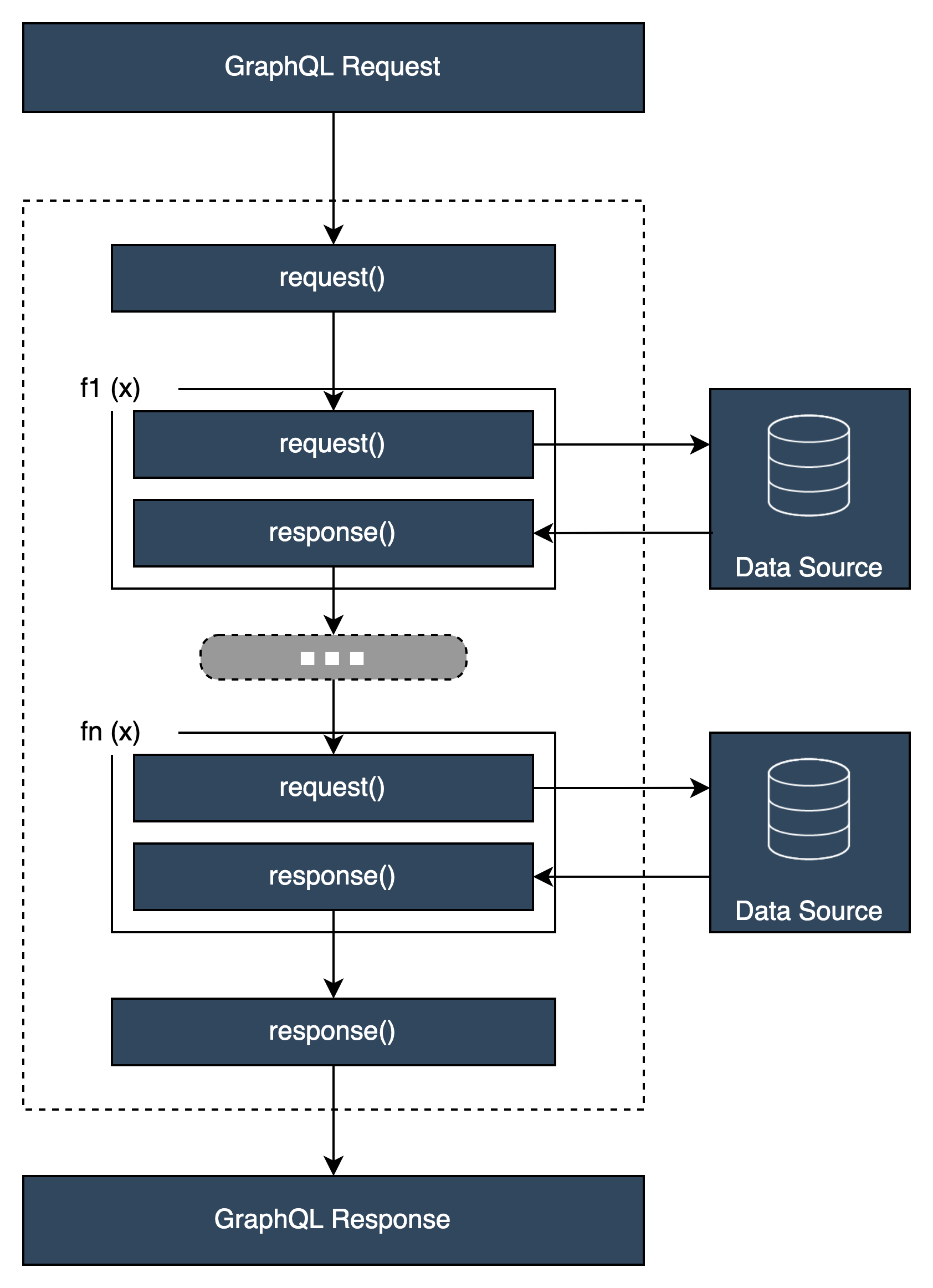
解析器处理程序结构
处理程序通常是名为 Request 和 Response 的函数:
export function request(ctx) { // Code goes here } export function response(ctx) { // Code goes here }
在单位解析器中,只有一组这样的函数。在管道解析器中,预备步骤和后续步骤具有一组这样的函数,并为每个函数额外提供一组这样的函数。为了直观地了解它的外观,让我们看一个简单的 Query 类型:
type Query { helloWorld: String! }
这是一个简单的查询,其中包含一个名为 helloWorld 且类型为 String 的字段。假设我们始终希望该字段返回字符串“Hello World”。为了实现该行为,我们需要将解析器添加到该字段中。在单位解析器中,我们可以添加如下内容:
export function request(ctx) { return {} } export function response(ctx) { return "Hello World" }
request 可以直接保留空白,因为我们不会请求或处理数据。我们还可以假设数据来源是 None,表明该代码不需要执行任何调用。响应仅返回“Hello World”。为了测试该解析器,我们需要使用该查询类型发出请求:
query helloWorldTest { helloWorld }
以下是一个名为 helloWorldTest 的查询,它返回 helloWorld 字段。在执行时,helloWorld 字段解析器也会执行并返回响应:
{ "data": { "helloWorld": "Hello World" } }
像这样返回常量是您可以执行的最简单操作。实际上,您将返回输入、列表等。以下是一个更复杂的示例:
type Book { id: ID! title: String } type Query { getBooks: [Book] }
此处,我们返回一个 Books 列表。假设我们使用 DynamoDB 表存储图书数据。我们的处理程序可能如下所示:
/** * Performs a scan on the dynamodb data source */ export function request(ctx) { return { operation: 'Scan' }; } /** * return a list of scanned post items */ export function response(ctx) { return ctx.result.items; }
我们的请求使用内置扫描操作搜索表中的所有条目,将结果存储在上下文中,然后将其传送到响应。响应获取结果项目,并在响应中返回它们:
{ "data": { "getBooks": { "items": [ { "id": "abcdefgh-1234-1234-1234-abcdefghijkl", "title": "book1" }, { "id": "aaaaaaaa-bbbb-cccc-dddd-eeeeeeeeeeee", "title": "book2" }, ... ] } } }
解析器上下文
在解析器中,处理程序链中的每个步骤必须了解以前步骤中的数据状态。可以存储一个处理程序的结果,并将其作为参数传递给另一个处理程序。GraphQL 定义了 4 个基本解析器参数:
| 解析器基本参数 | 说明 |
|---|---|
obj root、parent、等 |
父项的结果。 |
args |
为 GraphQL 查询中的字段提供的参数。 |
context |
为每个解析器提供的值,其中保存重要上下文信息,例如当前登录的用户或数据库的访问权限。 |
info |
该值保存与当前查询相关的字段特定信息以及架构详细信息。 |
在中 Amazon AppSync,context(ctx) 参数可以保存上述所有数据。它是根据请求创建的对象,并包含授权凭证、结果数据、错误、请求元数据等数据。上下文为程序员提供了一种简单方法,以处理来自请求的其他部分的数据。再看一下该代码片段:
/** * Performs a scan on the dynamodb data source */ export function request(ctx) { return { operation: 'Scan' }; } /** * return a list of scanned post items */ export function response(ctx) { return ctx.result.items; }
为请求提供了上下文 (ctx) 作为参数;这是请求的状态。它对表中的所有项目执行扫描,并将结果重新存储到 result 的上下文中。然后,将上下文传递给响应参数,该参数访问 result 并返回其内容。
请求和解析
在对 GraphQL 服务进行查询时,它必须在执行之前执行解析和验证过程。将解析您的请求并转换为抽象语法树,并对您的架构运行多种验证算法以验证树内容。在执行验证步骤后,将遍历并处理树的节点,调用解析器,将结果存储在上下文中,然后返回响应。例如,使用以下查询:
query { Person { //object type name //scalar age //scalar } }
我们返回具有 name 和 age 字段的 Person。在运行该查询时,树如下所示:
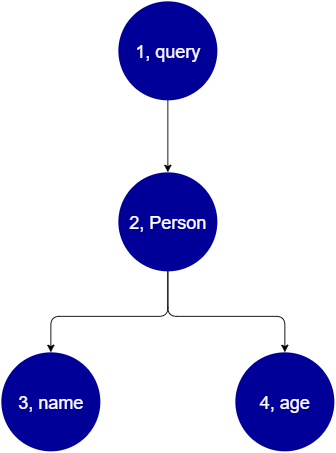
从树中可以看出,该请求在架构中搜索根以查找 Query。在查询中,将解析 Person 字段。从前面的示例中,我们知道这可能是来自用户的输入、值列表等。Person 很可能与包含我们所需的字段(name 和 age)的对象类型相关联。在找到这两个子字段后,它们按给定的顺序进行解析(先解析 name,然后解析 age)。在完全解析树后,将完成请求并将其发回到客户端。