Amazon Athena HBase 连接器
Amazon Athena HBase 连接器使 Amazon Athena 可以与 Apache HBase 实例通信,以便您可以使用 SQL 查询 HBase 数据。
与传统的关系数据存储不同,HBase 集合没有集架构。HBase 没有元数据存储。HBase 集合中的每个条目均可具有不同字段和数据类型。
HBase 连接器支持两种生成表架构信息的机制:基本架构推理和 Amazon Glue Data Catalog 元数据。
默认设置为架构推理。此选项将扫描您的集合中的少量文档,形成所有字段的并集,并强制使用非重叠数据类型的字段。此选项适用于条目大多为统一的集合。
对于具有更多数据类型的集合,该连接器支持从 Amazon Glue Data Catalog 检索元数据。如果该连接器发现与您的 HBase 命名空间和集合名称相匹配的 Amazon Glue 数据库和表,它将从相应的 Amazon Glue 表中获取其架构信息。在您创建 Amazon Glue 表时,我们建议您将其设置为您可能想从 HBase 集合访问的所有字段的超集。
如果您在账户中启用了 Lake Formation,则您在 Amazon Serverless Application Repository 中部署的 Athena 联合身份 Lambda 连接器的 IAM 角色必须在 Lake Formation 中具有 Amazon Glue Data Catalog 的读取权限。
此连接器可以作为联合目录注册到 Glue Data Catalog。此连接器支持 Lake Formation 中在目录、数据库、行和标签级别定义的数据访问控制。此连接器使用 Glue 连接将配置属性集中保存到 Glue 中。
先决条件
可以使用 Athena 控制台或 Amazon Serverless Application Repository 将该连接器部署到您的 Amazon Web Services 账户。有关更多信息,请参阅创建数据来源连接或使用 Amazon Serverless Application Repository 部署数据来源连接器。
参数
使用本节中的参数来配置 HBase 连接器。
注意
2024 年 12 月 3 日及之后创建的 Athena 数据来源连接器使用 Amazon Glue 连接。
下面列出的参数名称和定义适用于在 2024 年 12 月 3 日之前创建的 Athena 数据来源连接器,可能与相应的 Amazon Glue 连接属性不同。从 2024 年 12 月 3 日起,仅在手动部署早期版本的 Athena 数据来源连接器时才使用以下参数。
我们建议您使用 Glue 连接对象来配置 HBase 连接器。要执行此操作,请将 HBase 连接器 Lambda 的 glue_connection 环境变量设置为要使用的 Glue 连接的名称。
Glue 连接属性
使用以下命令来获取 Glue 连接对象的架构。此架构包含可用于控制连接的所有参数。
aws glue describe-connection-type --connection-type HBASE
Lambda 环境属性
-
glue_connection – 指定与联合连接器关联的 Glue 连接的名称。
注意
-
所有使用 Glue 连接的连接器都必须使用 Amazon Secrets Manager 来存储凭证。
-
使用 Glue 连接创建的 HBase 连接器不支持使用多路复用处理程序。
-
使用 Glue 连接创建的 HBase 连接器仅支持
ConnectionSchemaVersion2。
-
spill_bucket - 为超出 Lambda 函数限制的数据指定 Amazon S3 存储桶。
-
spill_prefix -(可选)默认为指定
spill_bucket(称为athena-federation-spill)中的子文件夹。我们建议您在此位置配置 Amazon S3 存储生命周期,以删除早于预定天数或小时数的溢出内容。 -
spill_put_request_headers —(可选)用于溢出的 Amazon S3
putObject请求的请求标头和值的 JSON 编码映射(例如{"x-amz-server-side-encryption" : "AES256"})。有关其他可能的标头,请参阅《Amazon Simple Storage Service API 参考》中的 PutObject。 -
kms_key_id -(可选)默认情况下,将使用经过 AES-GCM 身份验证的加密模式和随机生成的密钥对溢出到 Amazon S3 的任何数据进行加密。要让您的 Lambda 函数使用 KMS 生成的更强的加密密钥(如
a7e63k4b-8loc-40db-a2a1-4d0en2cd8331),您可以指定 KMS 密钥 ID。 -
disable_spill_encryption -(可选)当设置为
True时,将禁用溢出加密。默认值为False,此时将使用 AES-GCM 对溢出到 S3 的数据使用进行加密 - 使用随机生成的密钥,或者使用 KMS 生成密钥。禁用溢出加密可以提高性能,尤其是当您的溢出位置使用服务器端加密时。 -
disable_glue -(可选)如果存在且设置为 true,则该连接器不会尝试从 Amazon Glue 检索补充元数据。
-
glue_catalog –(可选)使用此选项指定跨账户 Amazon Glue 目录。默认情况下,该连接器将尝试从其自己的 Amazon Glue 账户中获取元数据。
-
default_hbase – 如果存在,则指定在不存在特定于目录的环境变量时要使用的 HBase 连接字符串。
-
enable_case_insensitive_match –(可选)如果是
true,则对 HBase 中的表名执行不区分大小写的搜索。默认值为false。如果查询包含大写的表名,则使用该参数。
指定连接字符串
您可以提供一个或多个属性,用于定义与该连接器配合使用的 HBase 实例的 HBase 连接详细信息。为此,请设置一个与您要在 Athena 中使用的目录名称相对应的 Lambda 环境变量。例如,假设您要使用以下查询来查询 Athena 中的两个不同 HBase 实例:
SELECT * FROM "hbase_instance_1".database.table
SELECT * FROM "hbase_instance_2".database.table
您必须向 Lambda 函数中添加以下两个环境变量,然后才能使用这两个 SQL 语句:hbase_instance_1 和 hbase_instance_2。每个环境变量的值均应为以下格式的 HBase 连接字符串:
master_hostname:hbase_port:zookeeper_port
使用密钥
您可以选择将 Amazon Secrets Manager 用于您的连接字符串详细信息的部分值或全部值。要将 Athena 联合查询功能与 Secrets Manager 配合使用,连接到您的 Lambda 函数的 VPC 应该拥有互联网访问权限
如果您使用语法 ${my_secret} 将来自 Secrets Manager 的密钥的名称放入您的连接字符串中,该连接器会将该密钥名称替换为来自 Secrets Manager 的您的用户名和密码值。
例如,假设您将 hbase_instance_1 的 Lambda 环境变量设置为以下值:
${hbase_host_1}:${hbase_master_port_1}:${hbase_zookeeper_port_1}
Athena 查询联合软件开发工具包 (SDK) 将自动尝试从 Secrets Manager 检索名为的密钥 hbase_instance_1_creds 的密钥,然后注入该值来替换 ${hbase_instance_1_creds}。${
} 字符组合所包含的该连接字符串的任何部分将被解释为来自 Secrets Manager 的密钥。如果您指定了该连接器在 Secrets Manager 中无法找到的密钥名称,则该连接器不会替换该文本。
在 Amazon Glue 中设置数据库和表
该连接器的内置架构推理仅支持在 HBase 中序列化为字符串的值(例如,String.valueOf(int))。由于该连接器的内置架构推理功能有限,因此您可能需要改为将 Amazon Glue 用于元数据。要使 Amazon Glue 表可与 HBase 配合使用,您必须拥有名称与 HBase 命名空间相匹配的 Amazon Glue 数据库和表,以及您要为其提供补充元数据的表。使用 HBase 列系列命名约定是可选的,但不是必需的。
将 Amazon Glue 表用于补充元数据
-
当您在 Amazon Glue 控制台中编辑表和数据库时,可以添加以下表属性:
hbase-metadata-flag – 此属性将向 HBase 连接器指明该连接器可将该表用于补充元数据。只要表属性的列表中存在
hbase-metadata-flag属性,您就可以为hbase-metadata-flag提供任何值。-
hbase-native-storage-flag – 可以使用此标记切换该连接器支持的两种值序列化模式。默认情况下,当此字段不存在时,该连接器将假定所有值都以字符串形式存储在 HBase 中。因此,它将尝试解析来自 HBase 的字符串形式的数据类型(如
INT、BIGINT和DOUBLE)。如果使用 Amazon Glue 中的表上的任何值设置此字段,该连接器将切换到“本机”存储模式,并尝试使用以下函数以字节形式读取INT、BIGINT、BIT和DOUBLE:ByteBuffer.wrap(value).getInt() ByteBuffer.wrap(value).getLong() ByteBuffer.wrap(value).get() ByteBuffer.wrap(value).getDouble()
-
请确保使用适合 Amazon Glue 的数据类型,如本文档中所列。
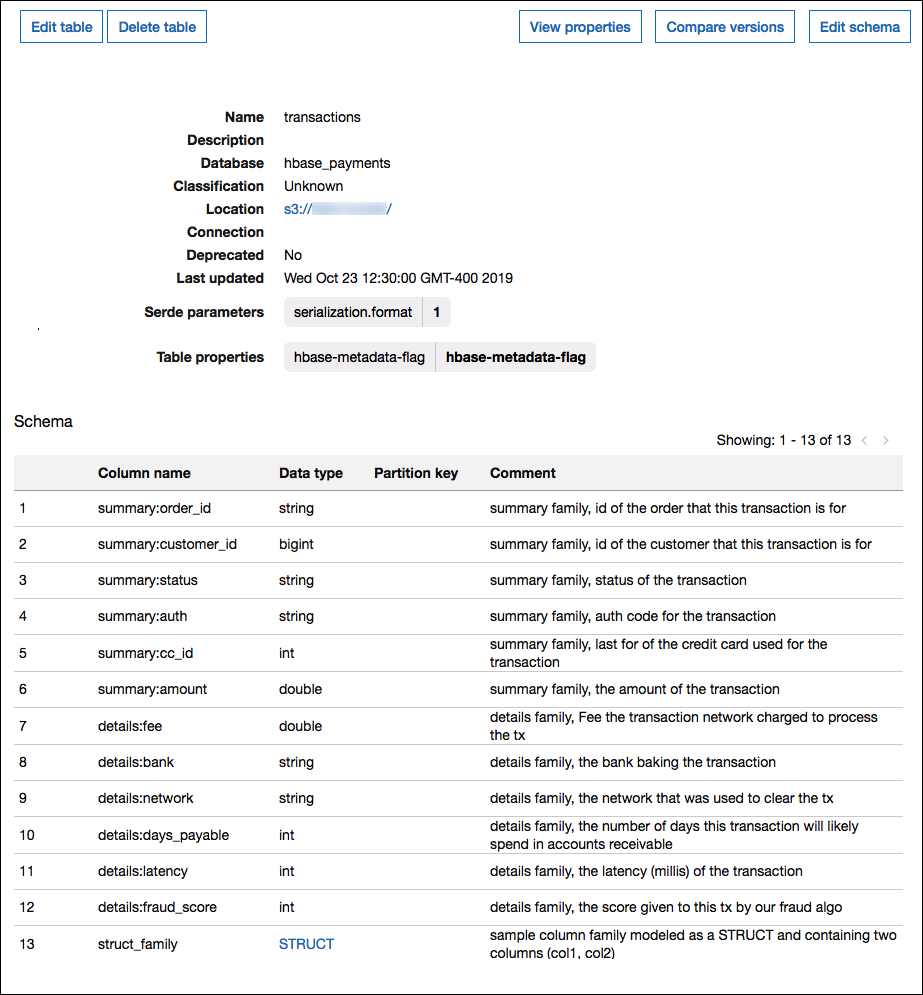
为列系列建模
Athena HBase 连接器支持两种为 HBase 列系列建模的方法:完全限定(扁平化)命名(如 family:column),或使用 STRUCT 对象。
在 STRUCT 模型中,STRUCT 字段的名称应与列系列相匹配,并且 STRUCT 的子级应与该系列的列名称相匹配。但是,由于复杂类型(如 STRUCT)尚不完全支持谓词下推和列式读取,因此目前不建议使用 STRUCT。
下图显示了使用两种方法的组合在 Amazon Glue 中配置的表。
数据类型支持
该连接器将以基本字节类型的形式检索所有 HBase 值。然后,根据您在 Amazon Glue Data Catalog 中定义表的方式,它会将值映射到下表中的一种 Apache Arrow 数据类型。
| Amazon Glue 数据类型 | Apache Arrow 数据类型 |
|---|---|
| 整数 | INT |
| bigint | BIGINT |
| double | FLOAT8 |
| 浮点数 | FLOAT4 |
| 布尔值 | BIT |
| binary | VARBINARY |
| 字符串 | VARCHAR |
注意
如果您不使用 Amazon Glue 补充您的元数据,则该连接器的架构推理将仅使用数据类型 BIGINT、FLOAT8 和 VARCHAR。
所需权限
有关此连接器所需 IAM policy 的完整详细信息,请查看 athena-hbase.yamlPolicies 部分。以下列表汇总了所需的权限。
-
Amazon S3 写入权限 – 连接器需要对 Amazon S3 中的位置具有写入权限,以溢出大型查询的结果。
-
Athena GetQueryExecution – 当上游 Athena 查询终止时,该连接器将使用此权限快速失败。
-
Amazon Glue Data Catalog – HBase 连接器需要针对 Amazon Glue Data Catalog 的只读访问权限,以获取架构信息。
-
CloudWatch Logs – 该连接器需要针对 CloudWatch Logs 的访问权限,以存储日志。
-
Amazon Secrets Manager 读取权限 - 如果您选择在 Secrets Manager 中存储 HBase 端点详细信息,则必须授予该连接器针对这些秘密的访问权限。
-
VPC 访问权限 - 该连接器需要能够连接和断开您的 VPC 接口,以便它能连接到 VPC 并与您的 HBase 实例通信。
性能
Athena HBase 连接器将尝试通过并行读取每个区域服务器,来并行处理针对您的 HBase 实例的查询。Athena HBase 连接器可执行谓词下推,以减少查询扫描的数据量。
Lambda 函数还执行投影下推,以减少查询扫描的数据。但是,选择列的子集有时会导致更长的查询执行运行时。LIMIT 子句可减少扫描的数据量,但如果未提供谓词,则预期要使用包含 LIMIT 子句的 SELECT 查询来扫描至少 16 MB 的数据。
HBase 容易出现查询失败和不同的查询执行时间。您可能需要多次重试查询才能成功。HBase 连接器能够灵活地应对并发造成的节流。
传递查询
HBase 连接器支持传递查询,并且以 NoSQL 为基础。有关使用筛选查询 Apache HBase 的信息,请参阅 Apache 文档中的 Filter language
要在 HBase 中执行传递查询,请使用以下语法:
SELECT * FROM TABLE( system.query( database => 'database_name', collection => 'collection_name', filter => '{query_syntax}' ))
以下 HBase 传递查询示例对 default 数据库 employee 集合中年龄为 24 或 30 岁的员工进行了筛选。
SELECT * FROM TABLE( system.query( DATABASE => 'default', COLLECTION => 'employee', FILTER => 'SingleColumnValueFilter(''personaldata'', ''age'', =, ''binary:30'')' || ' OR SingleColumnValueFilter(''personaldata'', ''age'', =, ''binary:24'')' ))
许可证信息
Amazon Athena HBase 连接器项目已经根据 Apache-2.0 许可证
其他资源
有关此连接器的更多信息,请访问 GitHub.com 上的相应站点