本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
自动扩缩组中实例的运行状况检查
Amazon EC2 Auto Scaling 持续监控自动扩缩组中实例的运行状态,以保持所需容量。
自动扩缩组中的所有实例均以 Healthy 状态开始。除非 Amazon EC2 Auto Scaling 收到实例运行状况不佳的通知,否则将认为它们运行状况良好。当实例运行状况不佳且必须更换时,它可以接收来自各种来源的通知。这些源包括以下内容:
-
Amazon EC2
-
Elastic Load Balancing
-
VPC Lattice
-
Amazon EBS
-
您定义的自定义运行状况检查
Amazon EC2 Auto Scaling 确定某个 InService 实例运行状况不佳时,会以一个新的实例替换该实例,以维持组的所需容量。新实例使用自动扩缩组的当前设置及其关联的启动模板或启动配置启动。
以下流程图说明在自动扩缩组中启动新实例的过程。首先启动实例。如果启动成功,则该实例将添加到自动扩缩组。然后,Amazon EC2 Auto Scaling 使用内置的 Amazon EC2 状态检查对该实例执行运行状况检查,并在宽限期后执行您为该组启用的任何可选运行状况检查。这些运行状况检查会定期持续进行。如果任何运行状况检查失败,则该实例将被替换。
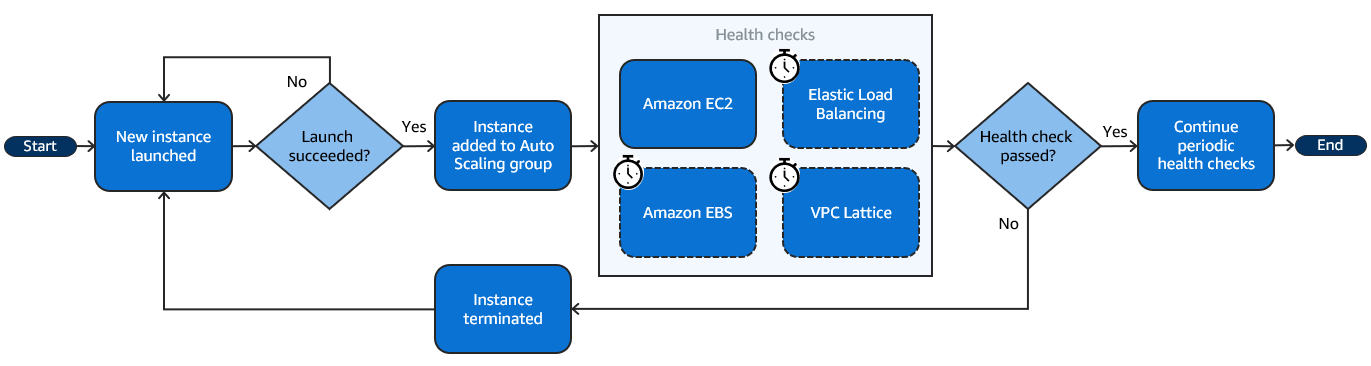
当实例意外终止(例如竞价型实例中断或用户手动终止)时,也可能出现运行状况不佳的实例。同样,在这些情况下,Amazon EC2 Auto Scaling 将自动启动替换实例以维持所需容量。