本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
DataBrew 项目会议概述
在 DataBrew 项目会话中,您在交互式工作区中工作。

左侧窗格显示数据的当前视图。右侧窗格显示项目的转换配方(该配方当前为空)。
在数据网格的右上角,有三个选项卡:GRID、SCHEMA 和 PROFILE。选择其中一个选项卡将在工作区中显示相应的视图;接下来将描述这些视图。
网格视图
网格视图是默认视图,在其中会以表格格式显示样本。使用以下过程简要介绍网格视图。
浏览网格视图
-
首先查看整个空间:
-
向左和向右滚动以查看所有列。
-
向上和向下滚动以查看所有数据值。
-
使用工作区底部的缩放控件调整网格的放大倍数。
-
-
在右上角,查看样本中显示的列数以及样本中的当前行数。
要更改显示哪些列,请选择 N 列链接(其中 N 是当前显示的列数)。选择所需的列,然后选择显示选定列。
-
现在你可以开始尝试 DataBrew 变换了。尝试以下操作:
-
在转换工具栏中,选择选择格式、转换为大写。
-
对于源列,选择包含字符数据的列。
-
保留其他设置的默认值。
-
要查看转换后的数据是什么样子,请选择预览更改。然后,要将此转换添加到您的配方,请选择应用。
无论何时应用数据转换,都要将其 DataBrew 添加到配方的工作副本中。它显示在工作区的右侧。
-
尝试以下操作:
-
在转换工具栏中,选择创建、基于函数。
-
在选择函数中,选择
SQUARE ROOT。 -
对于源列,选择包含数值数据的列。
-
保留其他设置的默认值。
-
选择预览更改以查看转换后的数据是什么样子。然后,要将此转换添加到您的配方,请选择应用。
-
-
通过选择配方折叠右上角的配方窗格。要展开配方窗格,请再次选择配方。
发布配方的新版本。
随着您继续应用转换,配方中的步骤数会增加。您可以随时发布配方的新版本。发布食谱可在其他地方使用 DataBrew。通过执行此操作,您可以运行配方作业来转换整个数据集,而不是仅转换项目数据样本。
发布配方也鼓励采用渐进、迭代的方法进行配方开发:可以随时发布配方的新版本,这样便可以根据需要回退到“上次已知的正确”配方版本。
发布配方的新版本
在配方窗格中,选择发布。输入此版本配方的描述,然后选择发布。
架构视图
如果选择架构选项卡,视图会发生变化,如以下屏幕截图所示。

在架构视图中,您可以查看有关每列中数据值的统计信息。
在最左边的列中 Show/Hide,选择任意数据列。列详细信息窗格将显示在右侧。此窗格将显示列值的统计信息摘要。
可通过在列名中输入新名称来重命名列。
可通过拖放列来重新排列列顺序。
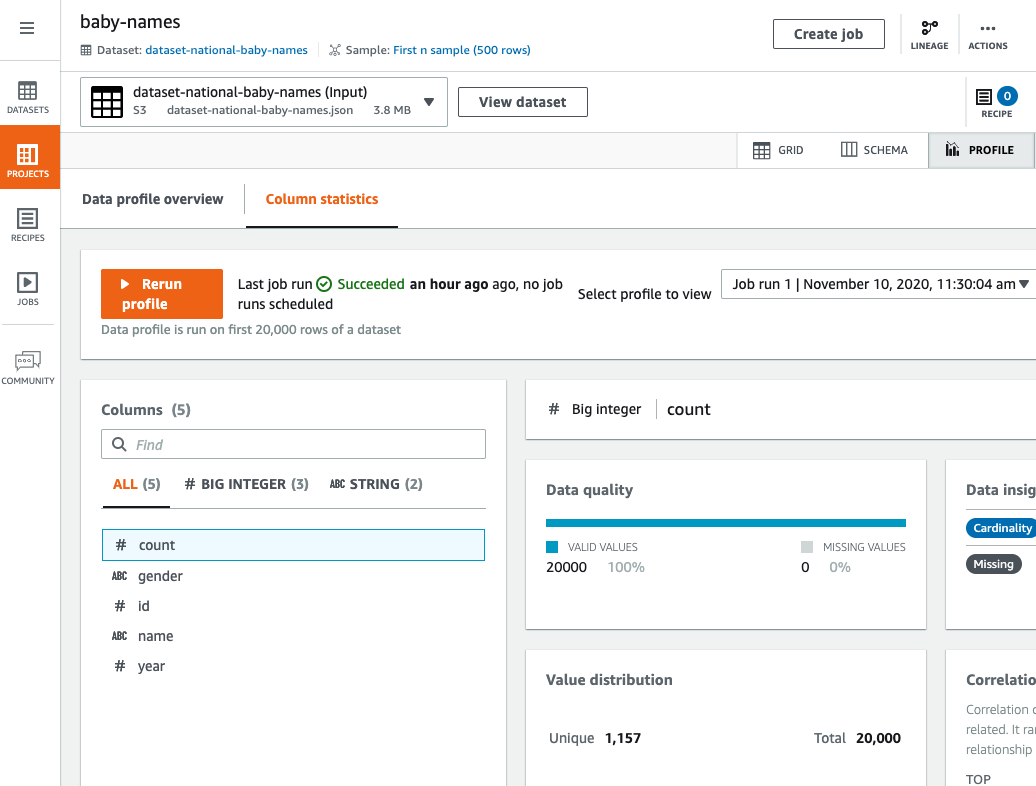
配置文件视图
如果选择配置文件选项卡,则可以查看有关项目的详细体积信息。在执行此操作之前,您需要运行 DataBrew 任务来创建配置文件。
浏览配置文件视图
-
选择创建作业,然后输入作业的名称。
-
对于作业输出,选择 CSV 作为文件类型。
-
在您的 Amazon 账户中找到或创建您想要写入任务输出的 Amazon S3 存储桶和文件夹: DataBrew
-
如果已有此 Amazon S3 存储桶和文件夹,请选择浏览并找到它们。确保您对这两者拥有写入权限。
-
如果没有此 Amazon S3 存储桶和文件夹,请创建它们:
打开 Amazon S3 控制台,网址为 https://console.aws.amazon.com/s3/
。 -
如果没有 Amazon S3 存储桶,请选择创建存储桶。对于存储桶名称,请为新存储桶输入一个唯一名称。选择 创建存储桶 。
-
从存储桶列表中,选择您想要使用的存储桶。
-
请选择 Create folder(创建文件夹)。对于文件夹名称,输入
databrew-output,然后选择创建文件夹。
-
-
DataBrew 要获得访问权限,请选择允许写入您的 Amazon S3 输出位置的 IAM 角色。
对于您的 Amazon 账户拥有的 S3 地点,您可以选择
AwsGlueDataBrewDataAccessRole服务托管角色。这样做可以 DataBrew 访问您拥有的 S3 资源。 -
将其他设置保留默认值,然后选择创建并运行作业。
-
作业运行完成后,工作区将显示数据配置文件的图形摘要。
数据剖析概览选项卡将显示数据特征的简要摘要,如以下屏幕截图所示。

列统计数据选项卡将显示数据值的逐列细分: