本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
教程:Amazon EMR 入门
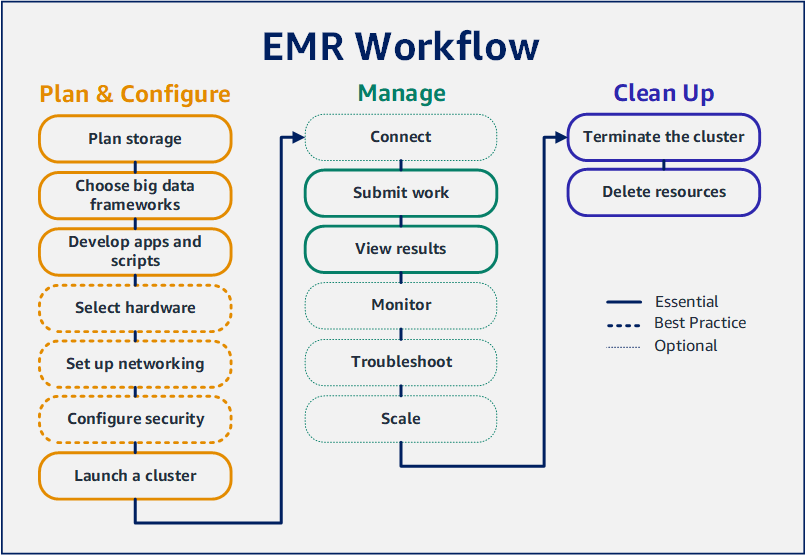
演示快速设置 Amazon EMR 集群并运行 Spark 应用程序的工作流。
设置 Amazon EMR 集群
借助 Amazon EMR,您可以设置集群以便在几分钟内使用大数据框架处理和分析数据。本教程向您展示如何使用 Spark 启动示例集群,以及如何运行存储在 Amazon S3 存储桶中的简单 PySpark 脚本。它涵盖了三个主要工作流类别中的基本 Amazon EMR 任务:计划和配置、管理以及清除。
在学习本教程时,您可以找到指向更详细主题的链接,以及 后续步骤 部分中其他步骤的想法。如果您有任何疑问或遇到困难,请在我们的论坛
先决条件
-
在启动 Amazon EMR 集群之前,请确保您已完成 设置 Amazon EMR 之前 中的任务。
成本
-
您创建的示例集群将在实际环境中运行。该集群产生最低费用。为避免额外费用,请确保您完成本教程最后一步中的清理任务。根据 Amazon EMR 定价,费用按秒计算。费用也因区域而有所不同。有关更多信息,请参阅 Amazon EMR 定价
。 -
对于您在 Amazon S3 中存储的小文件,也可能会产生最低费用。如果您在 Amazon 免费套餐的使用限制范围内,则可以免除 Amazon S3 的部分或全部费用。有关更多信息,请参阅 Amazon S3 定价
和Amazon 免费套餐 。
步骤 1:配置数据资源并启动 Amazon EMR 集群
为 Amazon EMR 准备存储
当您使用 Amazon EMR 时,您可以从各种文件系统中进行选择,以存储输入数据、输出数据和日志文件。在本教程,您可以使用 EMRFS 将数据存储在 S3 存储桶中。EMRFS 是 Hadoop 文件系统的一种实现方式,允许您读取常规文件并将其写入到 Amazon S3。有关更多信息,请参阅使用 Amazon EMR 处理存储和文件系统。
要为本教程创建存储桶,请参照《Amazon Simple Storage Service 控制台用户指南》中的如何创建 S3 存储桶?。在您计划启动 Amazon EMR 集群的同一 Amazon 地区创建存储桶。例如,美国西部(俄勒冈)us-west-2。
您用于 Amazon EMR 的存储桶和文件夹具有以下限制:
-
名称由小写字母、数字、句点 (.) 和连字符 (-) 组成。
-
名称不能以数字结尾。
-
对于所有 Amazon 账户,存储桶名称必须是唯一的。
-
输出文件夹必须为空。
为 Amazon EMR 准备含有输入数据的应用程序
为 Amazon EMR 准备应用程序的最常见方法是将应用程序及其输入数据上传至 Amazon S3。然后,您在向集群提交工作时,指定脚本和数据的 Amazon S3 位置。
在此步骤中,您将示例 PySpark 脚本上传到您的 Amazon S3 存储桶。我们提供了一个 PySpark 脚本供您使用。该脚本处理食品企业检查数据并在 S3 存储桶中返回结果文件。结果文件列出了红色类违规最多的十大企业。
您还可以将示例输入数据上传到 Amazon S3 以供 PySpark 脚本处理。输入数据是修正版,其中包含 2006 年至 2020 年华盛顿州金县卫生部门的检查结果。有关更多信息,请参阅 King County Open Data: Food Establishment Inspection Data
name,inspection_result,inspection_closed_business,violation_type,violation_points 100 LB CLAM,Unsatisfactory,FALSE,BLUE,5 100 PERCENT NUTRICION,Unsatisfactory,FALSE,BLUE,5 7-ELEVEN #2361-39423A,Complete,FALSE,,0
为 EMR 准备示例 PySpark 脚本
-
将下面的示例代码复制到您选择的编辑器中的新文件中。
import argparse from pyspark.sql import SparkSession def calculate_red_violations(data_source, output_uri): """ Processes sample food establishment inspection data and queries the data to find the top 10 establishments with the most Red violations from 2006 to 2020. :param data_source: The URI of your food establishment data CSV, such as 's3://amzn-s3-demo-bucket/food-establishment-data.csv'. :param output_uri: The URI where output is written, such as 's3://amzn-s3-demo-bucket/restaurant_violation_results'. """ with SparkSession.builder.appName("Calculate Red Health Violations").getOrCreate() as spark: # Load the restaurant violation CSV data if data_source is not None: restaurants_df = spark.read.option("header", "true").csv(data_source) # Create an in-memory DataFrame to query restaurants_df.createOrReplaceTempView("restaurant_violations") # Create a DataFrame of the top 10 restaurants with the most Red violations top_red_violation_restaurants = spark.sql("""SELECT name, count(*) AS total_red_violations FROM restaurant_violations WHERE violation_type = 'RED' GROUP BY name ORDER BY total_red_violations DESC LIMIT 10""") # Write the results to the specified output URI top_red_violation_restaurants.write.option("header", "true").mode("overwrite").csv(output_uri) if __name__ == "__main__": parser = argparse.ArgumentParser() parser.add_argument( '--data_source', help="The URI for you CSV restaurant data, like an S3 bucket location.") parser.add_argument( '--output_uri', help="The URI where output is saved, like an S3 bucket location.") args = parser.parse_args() calculate_red_violations(args.data_source, args.output_uri) -
将该文件保存为
health_violations.py。 -
将
health_violations.py上传到您为本教程创建的 Amazon S3 存储桶中。有关说明,请参阅 Amazon Simple Storage Service 入门指南中的将对象上传到存储桶。
为 EMR 准备示例输入数据
-
下载 zip 文件 food_establishment_data.zip。
-
解压并保存
food_establishment_data.zip至 计算机的food_establishment_data.csv。 -
将 CSV 文件上载到您为本教程创建的 S3 存储桶。有关说明,请参阅 Amazon Simple Storage Service 入门指南中的将对象上传到存储桶。
有关为 EMR 设置数据的更多信息,请参阅准备输入数据以供 Amazon EMR 处理。
启动 Amazon EMR 集群
您在准备存储位置和应用程序之后,则可以启动示例 Amazon EMR 集群。在此步骤,您使用最新的 Amazon EMR 版本启动 Apache Spark 集群。
步骤 2:将工作提交到 Amazon EMR 集群
提交工作并查看结果
启动集群后,可以向正在运行的集群提交工作,从而处理分析数据。提交工作至 Amazon EMR 集群,作为 step (步骤)。步骤是由一个或多个任务组成的工作单位。例如,您可以提交一个步骤来计算值,或传输和处理数据。可以在创建集群时提交步骤,也可以将步骤提交到正在运行的集群。教程这部分内容中,您向正在运行的集群提交health_violations.py步骤。要了解有关步骤的更多信息,请参阅将工作提交到 Amazon EMR 集群。
有关步骤生命周期的更多信息,请参阅运行步骤以处理数据。
查看结果
步骤成功运行后,您可以在 Amazon S3 输出文件夹中查看其输出结果。
查看 health_violations.py 的结果
打开 Amazon S3 控制台,网址为 https://console.aws.amazon.com/s3/
。 -
选择 Bucket name (存储桶名称),然后选择您在提交步骤时指定的输出文件夹。例如,
amzn-s3-demo-bucket然后myOutputFolder。 -
验证以下项目是否位于输出文件夹中:
-
称为
_SUCCESS的小格式对象。 -
以前缀
part-开头的 CSV 文件,包含结果。
-
-
选择包含结果的对象,然后选择 Download (下载) 以将结果保存到本地文件系统。
-
在选定编辑器中打开结果。输出文件列出了红色违规最多的十大食品企业。输出文件还显示每个机构的红色违规总数。
以下是
health_violations.py结果的示例。name, total_red_violations SUBWAY, 322 T-MOBILE PARK, 315 WHOLE FOODS MARKET, 299 PCC COMMUNITY MARKETS, 251 TACO TIME, 240 MCDONALD'S, 177 THAI GINGER, 153 SAFEWAY INC #1508, 143 TAQUERIA EL RINCONSITO, 134 HIMITSU TERIYAKI, 128
有关 Amazon EMR 集群输出的更多信息,请参阅为 Amazon EMR 集群输出配置位置。
当您使用 Amazon EMR 时,您可能希望连接到正在运行的集群,以读取日志文件、调试集群或使用类似于 Spark shell 的 CLI 工具。通过 Amazon EMR,您可以使用 Secure Shell(SSH)协议连接到集群。本部分介绍如何配置 SSH、集群连接以及查看 Spark 的日志文件。有关连接到集群的更多信息,请参阅 对 Amazon EMR 集群节点进行身份验证。
授权与集群的 SSH 连接
在连接到集群之前,您需要修改集群安全组以授权入站 SSH 连接。Amazon EC2 安全组充当虚拟防火墙以控制至您的集群的入站和出站流量。为本教程创建集群时,Amazon EMR 代表您创建了以下安全组:
- ElasticMapReduce-主人
-
与主节点关联的默认 Amazon EMR 托管安全组。在 Amazon EMR 集群中,主节点是管理集群的 Amazon EC2 实例。
- ElasticMapReduce-奴隶
-
与核心和任务节点关联的默认安全组。
使用 Connect 连接到您的集群 Amazon CLI
无论您的操作系统如何,都可以使用 Amazon CLI创建 SSH 连接到集群。
要连接到您的集群并使用查看日志文件 Amazon CLI
-
使用以下命令开启与集群的 SSH 连接。
<mykeypair.key>替换为 key pair 文件的完整路径和文件名。例如C:\Users\<username>\.ssh\mykeypair.pem。aws emr ssh --cluster-id<j-2AL4XXXXXX5T9>--key-pair-file<~/mykeypair.key> -
导航到
/mnt/var/log/spark访问集群主节点 (master node) 上的 Spark 日志。然后查看该位置的文件。有关主节点 (master node) 上其他日志文件的列表,请参阅 查看主节点上的日志文件。cd /mnt/var/log/spark ls
EC2 上的 Amazon EMR 也是 Uni Amazon SageMaker AI fied Studio 支持的计算类型。有关如何在 Un ified Studio 中使用和管理 EC2 资源上的 EMR,请参阅在 EC2 上管理 Amazon EMR。 Amazon SageMaker AI
第 3 步:清除 Amazon EMR 资源
终止集群
既然您已向集群提交工作并查看了PySpark 应用程序的结果,就可以终止集群了。终止集群会停止所有集群关联的 Amazon EMR 费用和 Amazon EC2 实例。
在终止集群后,Amazon EMR 将有关集群的元数据免费保留两个月。归档元数据有助于为新任务克隆集群 (clone the cluster) 或为了参考的目的重新访问集群配置。元数据不包括集群写入 S3 的数据,或存储在集群上的 HDFS 中的数据。
注意
Amazon EMR 控制台不允许您在关闭集群后从列表视图中终止集群。当 Amazon EMR 清除其元数据时,终止的集群将从控制台消失。
删除 S3 资源
为避免产生额外费用,您应删除 Amazon S3 存储桶。删除存储桶意味着将删除本教程中的所有 Amazon S3 资源。您的存储桶应包含:
-
剧 PySpark 本
-
输入数据集
-
您的输出结果文件夹
-
您的日志文件夹
如果您将PySpark 脚本或输出保存在其他位置,则可能需要采取额外的步骤来删除存储的文件。
注意
在删除存储桶之前,必须终止集群。否则,可能不允许您清空存储桶。
要删除存储桶,请参照《Amazon Simple Storage Service 用户指南》中如何删除 S3 存储桶?的说明。
后续步骤
您现在已经从头到尾启动了第一个 Amazon EMR 集群。您还完成了基本的 EMR 任务,例如:准备和提交大数据应用程序、查看结果以及终止集群。
可以使用以下主题了解如何自定义 Amazon EMR 工作流程的更多信息。
了解 Amazon EMR 的大数据应用程序
在《Amazon EMR 版本指南》中发现并比较您可以在集群上安装的大数据应用程序。《发布指南 (Release Guide)》详细介绍了每个 EMR 发布版本,并包括使用 Amazon EMR 上的 Spark 和 Hadoop 等框架的提示。
规划集群硬件、联网和安全
本教程中,您将创建一个简单的 EMR 集群,而无需配置高级选项。高级选项允许您指定 Amazon EC2 实例类型、集群联网和集群安全性。有关规划和启动满足您要求的集群的更多信息,请参阅规划、配置和启动 Amazon EMR 集群和Amazon EMR 中的安全性。
管理集群
深入了解如何在管理 Amazon EMR 集群中运行的集群。要管理集群,您可以连接到集群、调试步骤以及跟踪集群活动和健康状况。您还可以通过 EMR 托管扩展,调整集群资源以响应工作负载需求。
使用不同的界面
除了亚马逊 EMR 控制台之外,您还可以使用、网络服务 API 或众多支持的应用程序之一来管理 Amazon EMR。 Amazon Command Line Interface Amazon SDKs有关更多信息,请参阅 管理界面。
您可以通过多种方式与安装在 Amazon EMR 集群上的应用程序进行交互。某些应用程序(如 Apache Hadoop)会发布您可以查看的 Web 界面。有关更多信息,请参阅查看 Amazon EMR 集群上托管的 Web 界面。
浏览 EMR 技术博客
有关新的 Amazon EMR 功能的示例演练和深入的技术讨论,请参阅Amazon 大数据博客