本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
将 Amazon EMR 与 Amazon Lake Formation
Amazon Lake Formation 是一项托管服务,可帮助您发现、分类、清理和保护亚马逊简单存储服务 (S3) Simple Service 数据湖中的数据。Lake Formation 在列、行或单元级别提供对 Glue 数据目录中的数据库和表的精 Amazon 细访问。有关更多信息,请参阅什么是 Amazon Lake Formation?
使用 Amazon EMR 发行版本 6.7.0 及更高版本,您可以将基于 Lake Formation 的访问控制应用于您提交到 Amazon EMR 集群的 Spark、Hive 和 Presto 作业。要与 Lake Formation 集成,您必须创建具有运行时角色的 EMR 集群。运行时角色是您与 Amazon EMR 作业或查询关联的 Amazon Identity and Access Management (IAM) 角色。然后,Amazon EMR 使用此角色访问 Amazon 资源。有关更多信息,请参阅 Amazon EMR 步骤的运行时角色。
Amazon EMR 如何与 Lake Formation 结合使用
将亚马逊 EMR 与 Lake Formation 集成后,您可以使用 StepAPI 或 AI Studio 对亚马逊 EMR 集群执行查询。 SageMaker 然后,Lake Formation 通过 Amazon EMR 的临时凭证提供对数据的访问。此过程称为凭证售卖。有关更多信息,请参阅什么是 Amazon Lake Formation?
以下是 Amazon EMR 如何访问受 Lake Formation 安全策略保护的数据的高级概览。
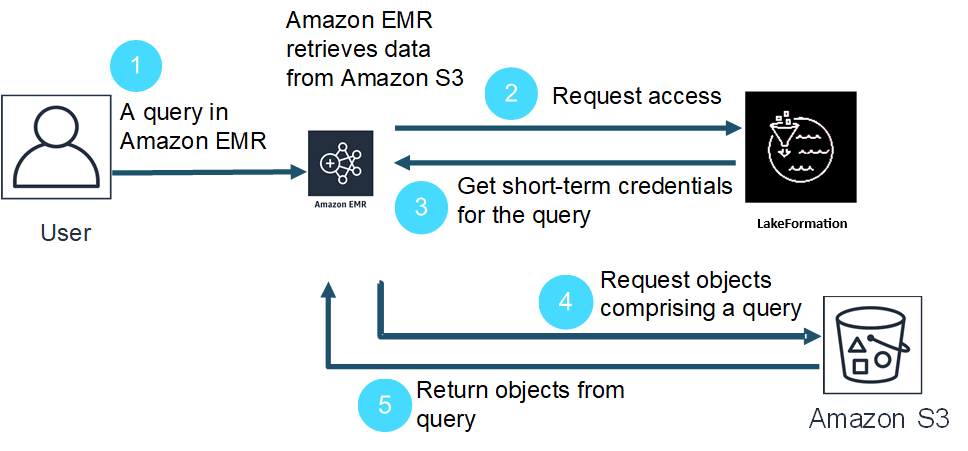
-
用户对 Lake Formation 中的数据提交 Amazon EMR 查询。
-
Amazon EMR 从 Lake Formation 请求临时凭证以授予用户数据访问权限。
-
Lake Formation 返回临时凭证。
-
Amazon EMR 发送查询请求以从 Amazon S3 检索数据。
-
Amazon EMR 接收来自 Amazon S3 的数据,进行筛选,然后根据用户在 Lake Formation 中定义的用户权限返回结果。
有关将用户和组添加到 Lake Formation 策略中的更多信息,请参阅授予数据目录权限。
先决条件
集成 Amazon EMR 和 Lake Formation 之前,您必须满足以下要求:
-
在 Amazon EMR 集群上开启运行时角色授权。
-
使用 Amazon Glue 数据目录作为元数据存储。
-
在 Lake For Amazon mation 中定义和管理访问 Glue 数据目录中数据库、表和列的权限。有关更多信息,请参阅什么是 Amazon Lake Formation?