本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
启用用户模拟以监控 Spark 用户和任务活动
借助 EMR Notebooks,您可以在 Spark 集群上配置用户模拟。此功能可帮助您跟踪从 Notebook 编辑器内启动的作业活动。此外,EMR Notebooks 有一个内置的 Jupyter Notebook 小组件,可用于在 Notebook 编辑器的查询输出旁边显示 Spark 任务详细信息。默认情况下,此小部件处于可用状态,无需特殊配置。但是,要查看历史记录服务器,您的客户端必须配置为查看主节点上托管的 Amazon EMR Web 界面。
注意
EMR Notebooks 在控制台中作为 Amazon EMR Studio Workspaces 提供。通过控制台中的创建 Workspace 按钮,可以创建新的 Notebooks。要访问或创建 Workspaces,EMR Notebooks 用户需要额外的 IAM 角色权限。有关更多信息,请参阅 Amazon EMR Notebooks 是控制台中的 Amazon EMR Studio Workspaces 和 Amazon EMR 控制台。
设置 Spark 用户模拟
默认情况下,用户使用 Notebook 编辑器提交的 Spark 作业似乎源自一个模糊的 livy 用户身份。您可以为集群配置用户模拟,以便这些任务与运行代码的用户身份相关联。系统会为在 Notebook 中运行代码的每个用户身份在主节点上创建 HDFS 用户目录。例如,如果用户 NbUser1 从 Notebook 编辑器运行代码,您可以连接主节点并可以看到 hadoop fs -ls /user 显示目录 /user/user_NbUser1。
您可以在 core-site 和 livy-conf 配置分类中设置属性以启用该功能。如果您让 Amazon EMR 同时创建集群和 Notebook,那么默认情况下,此功能将不可用。有关使用配置分类自定义应用程序的更多信息,请参阅《Amazon EMR 版本指南》中的配置应用程序。
使用以下配置分类和值为 EMR Notebooks 启用用户模拟:
[ { "Classification": "core-site", "Properties": { "hadoop.proxyuser.livy.groups": "*", "hadoop.proxyuser.livy.hosts": "*" } }, { "Classification": "livy-conf", "Properties": { "livy.impersonation.enabled": "true" } } ]
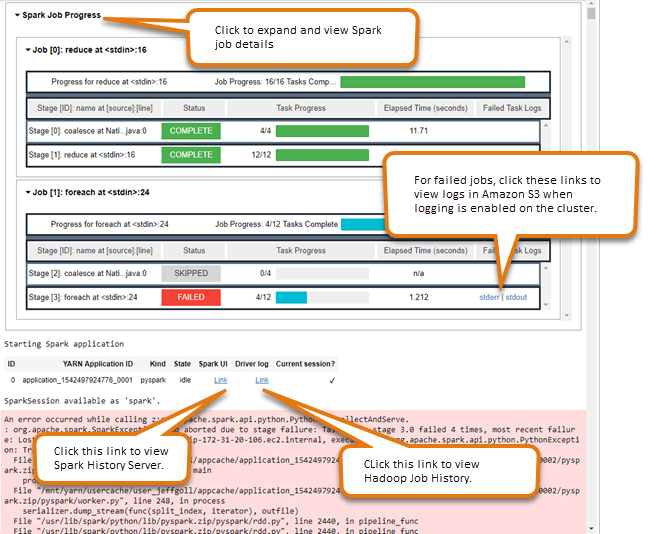
使用 Spark 任务监控小组件
如果运行代码的 Notebook 编辑器在 EMR 集群上执行 Spark 任务,那么输出中会包含一个用于监控 Spark 任务的 Jupyter Notebook 小组件。此小组件会提供任务详细信息、指向 Spark 历史记录服务器页面和 Hadoop 任务历史记录页面的有用链接,以及指向 Amazon S3 中有关任何失败任务的任务日志的便捷链接。
要查看集群主节点上的历史记录服务器页面,您必须根据需要设置 SSH 客户端和代理。有关更多信息,请参阅 查看 Amazon EMR 集群上托管的 Web 界面。要查看 Amazon S3 中的日志,必须启用集群日志记录,这是新集群的默认设置。有关更多信息,请参阅查看归档到 Amazon S3 的日志文件。
以下是一个 Spark 任务监控示例。