本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
# 用于 Ranger 与 Amazon EMR 集成的 Apache Spark 插件
亚马逊 EMR 集成了 EMR,为 SparkSQL 提供了精细 RecordServer 的访问控制。EMR RecordServer 是一个在 Apache Ranger-enabled 集群的所有节点上运行的特权进程。当 Spark 驱动程序或执行器运行 SparkSQL 语句时,所有元数据和数据请求都会通过。 RecordServer要了解有关 EMR 的更多信息 RecordServer,请参阅页面。[适用于 Apache Ranger 的 Amazon EMR 组件](emr-ranger-components.md)
**Topics**
+ [支持的功能](#emr-ranger-spark-supported-features)
+ [重新部署服务定义以使用 INSERT、ALTER 或 DDL 语句](#emr-ranger-spark-redeploy-service-definition)
+ [安装服务定义](#emr-ranger-spark-install-servicedef)
+ [创建 SparkSQL 策略](#emr-ranger-spark-create-sparksql)
+ [注意事项](#emr-ranger-spark-considerations)
+ [限制](#emr-ranger-spark-limitations)
## 支持的功能
| SQL statement/Ranger 操作 | STATUS | 支持的 EMR 版本 |
| --- | --- | --- |
| SELECT | 支持 | 截至 5.32 |
| SHOW DATABASES | 支持 | 截至 5.32 |
| SHOW COLUMNS | 支持 | 截至 5.32 |
| SHOW TABLES | 支持 | 截至 5.32 |
| SHOW TABLE PROPERTIES | 支持 | 截至 5.32 |
| DESCRIBE TABLE | 支持 | 截至 5.32 |
| INSERT OVERWRITE | 支持 | 自 5.34 和 6.4 起 |
| INSERT INTO | 支持 | 自 5.34 和 6.4 起 |
| ALTER TABLE | 支持 | 截至 6.4 |
| CREATE TABLE | 支持 | 自 5.35 和 6.7 起 |
| CREATE DATABASE | 支持 | 自 5.35 和 6.7 起 |
| DROP TABLE | 支持 | 自 5.35 和 6.7 起 |
| DROP DATABASE | 支持 | 自 5.35 和 6.7 起 |
| DROP VIEW | 支持 | 自 5.35 和 6.7 起 |
| CREATE VIEW | 不支持 | |
使用 SparkSQL 时支持以下功能:
+ Fine-grained 对 Hive Metastore 中的表进行访问控制,并且可以在数据库、表和列级别创建策略。
+ Apache Ranger 策略可以包括对用户和组的授予策略和拒绝策略。
+ 审核事件提交到 CloudWatch 日志。
## 重新部署服务定义以使用 INSERT、ALTER 或 DDL 语句
**注意**
从 Amazon EMR 6.4 开始,您可以将 Spark SQL 与以下语句结合使用: INSERT INTO (插入)、INSERT OVERWRITE (插入覆盖)或更改 LTER TABLE (表格语句)。从 Amazon EMR 6.7 开始,您可以使用 Spark SQL 创建或删除数据库和表。如果您在部署了 Apache Spark 服务定义的 Apache Ranger 服务器上具有现有安装程序,请使用以下代码重新部署服务定义。
```
# Get existing Spark service definition id calling Ranger REST API and JSON processor
curl --silent -f -u {{}}:{{}} \
-H "Accept: application/json" \
-H "Content-Type: application/json" \
-k 'https://*{{}}*:6182/service/public/v2/api/servicedef/name/amazon-emr-spark' | jq .id
# Download the latest Service definition
wget https://s3.amazonaws.com/elasticmapreduce/ranger/service-definitions/version-2.0/ranger-servicedef-amazon-emr-spark.json
# Update the service definition using the Ranger REST API
curl -u {{}}:{{}} -X PUT -d @ranger-servicedef-amazon-emr-spark.json \
-H "Accept: application/json" \
-H "Content-Type: application/json" \
-k 'https://*{{}}*:6182/service/public/v2/api/servicedef/{{}}'
```
## 安装服务定义
安装 EMR 的 Apache Spark 服务定义要求先安装 Ranger Admin 服务器。请参阅[设置 Ranger Admin 服务器,以便与 Amazon EMR 集成](emr-ranger-admin.md)。
按照以下步骤安装 Apache Spark 服务定义:
**步骤 1: SSH 进入 Apache Ranger Admin 服务器**
例如:
```
ssh ec2-user@ip-xxx-xxx-xxx-xxx.ec2.internal
```
**步骤 2: 下载服务定义和 Apache Ranger Admin 服务器插件**
在临时目录中,下载服务定义。此服务定义由 Ranger 2.x 版本支持。
```
mkdir /tmp/emr-spark-plugin/
cd /tmp/emr-spark-plugin/
wget https://s3.amazonaws.com/elasticmapreduce/ranger/service-definitions/version-2.0/ranger-spark-plugin-2.x.jar
wget https://s3.amazonaws.com/elasticmapreduce/ranger/service-definitions/version-2.0/ranger-servicedef-amazon-emr-spark.json
```
**步骤 3: 安装适用于 Amazon EMR 的 Apache Spark 插件**
```
export RANGER_HOME=.. # Replace this Ranger Admin's home directory eg /usr/lib/ranger/ranger-2.0.0-admin
mkdir $RANGER_HOME/ews/webapp/WEB-INF/classes/ranger-plugins/amazon-emr-spark
mv ranger-spark-plugin-2.x.jar $RANGER_HOME/ews/webapp/WEB-INF/classes/ranger-plugins/amazon-emr-spark
```
**步骤 4: 注册 Amazon EMR 的 Apache Spark 服务定义**
```
curl -u **:*_<_**_password_ **_for_** _ranger admin user_**_>_* -X POST -d @ranger-servicedef-amazon-emr-spark.json \
-H "Accept: application/json" \
-H "Content-Type: application/json" \
-k 'https://**:6182/service/public/v2/api/servicedef'
```
如果此命令成功运行,您将在 Ranger 管理界面中看到一个名为 AMAZON-EMR-SPARK “” 的新服务,如下图所示(显示的是 Ranger 版本 2.0)。
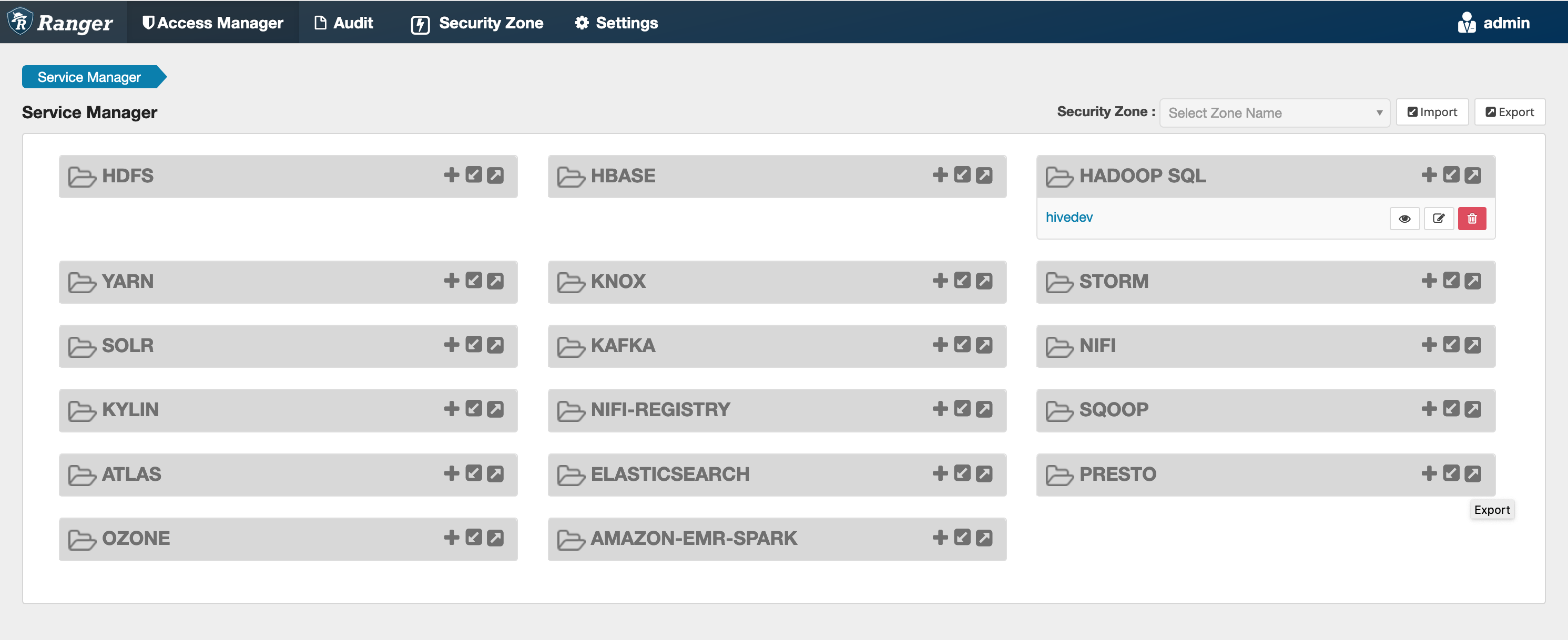
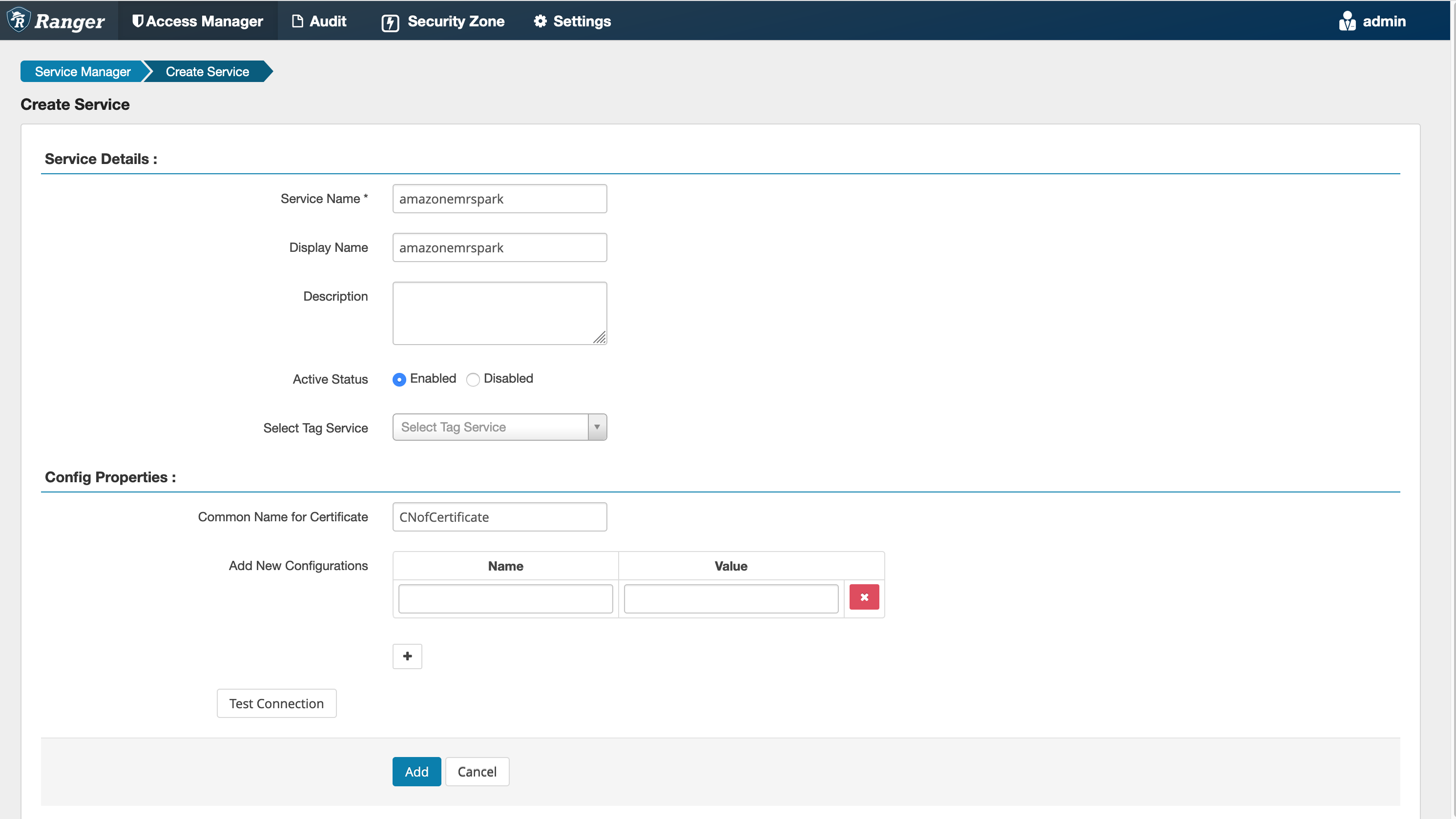
**步骤 5:创建 AMAZON-EMR-SPARK应用程序的实例**
**Service Name (服务名称)**(如果显示):将使用的服务名称。建议的值为 **amazonemrspark**。请记下此服务名称,创建 EMR 安全配置时将要用到。
**Display Name (显示名称):**要为此实例显示的名称。建议的值为 **amazonemrspark**。
**Common Name For Certificate (凭证的公用名称)**:凭证中的 CN 字段,用于从客户端插件连接到管理服务器。此值必须与为插件创建的 TLS 凭证中的 CN 字段匹配。
**注意**
此插件的 TLS 凭证应该已在 Ranger Admin 服务器的信任库中注册。有关更多信息,请参阅[用于 Apache Ranger 与 Amazon EMR 集成的 TLS 证书](emr-ranger-admin-tls.md)。
## 创建 SparkSQL 策略
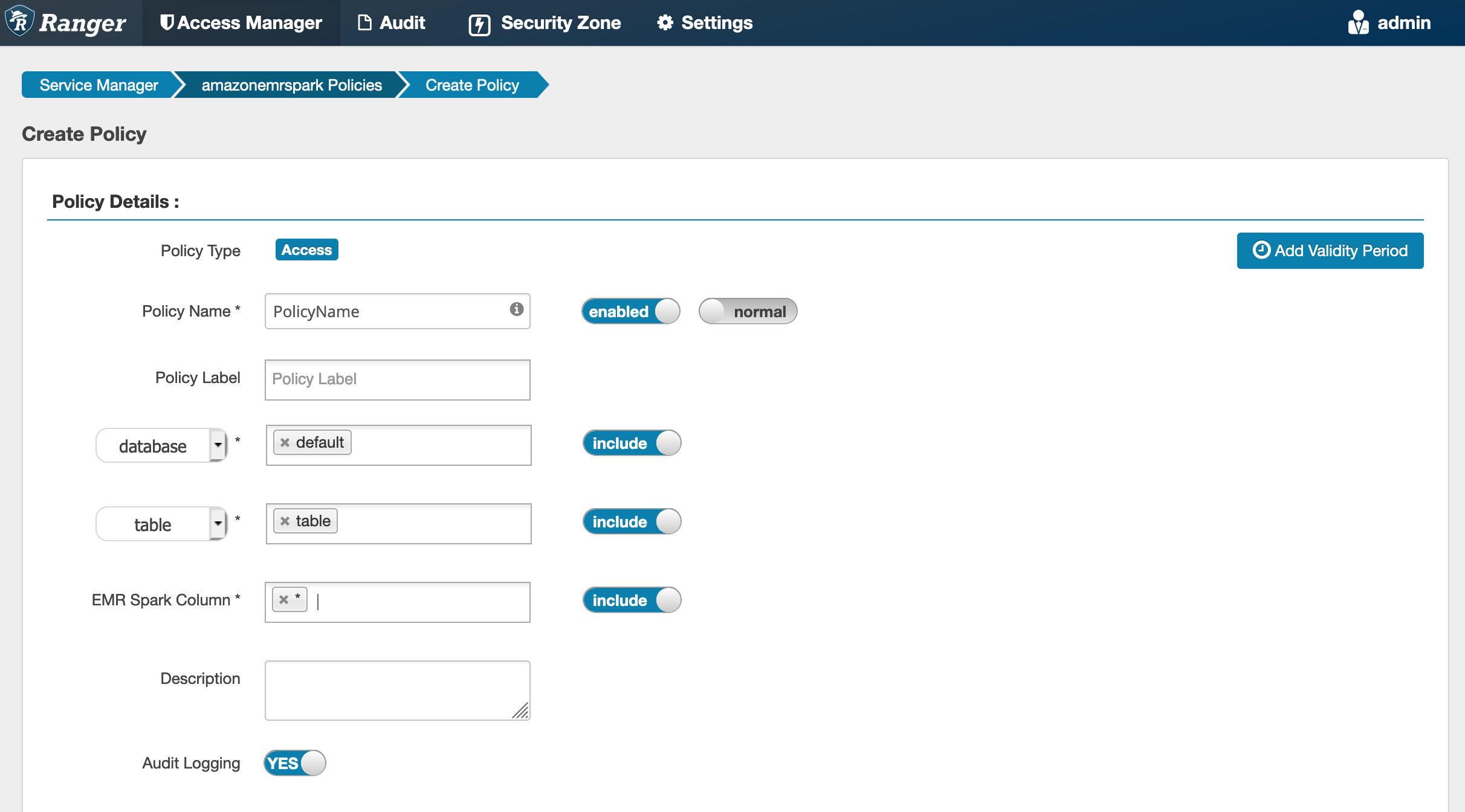
创建新策略时,要填写的字段包括:
**Policy Name (策略名称)**:此策略的名称。
**Policy Label (策略标注)**:您可以在此策略上放置的标注。
**Database (数据库)**:应用此策略的数据库。通配符“\*”表示所有数据库。
**Table(表)**:应用此策略的表。通配符“\*”表示所有表。
**EMR Spark Column (EMR Spark 列)**:应用此策略的列。通配符“\*”表示所有列。
**Description (描述)**:策略的描述。
要指定用户和组,请在下方输入用户和组以授予权限。您还可以指定 **allow**(允许)条件和 **deny**(拒绝)条件的排除项。
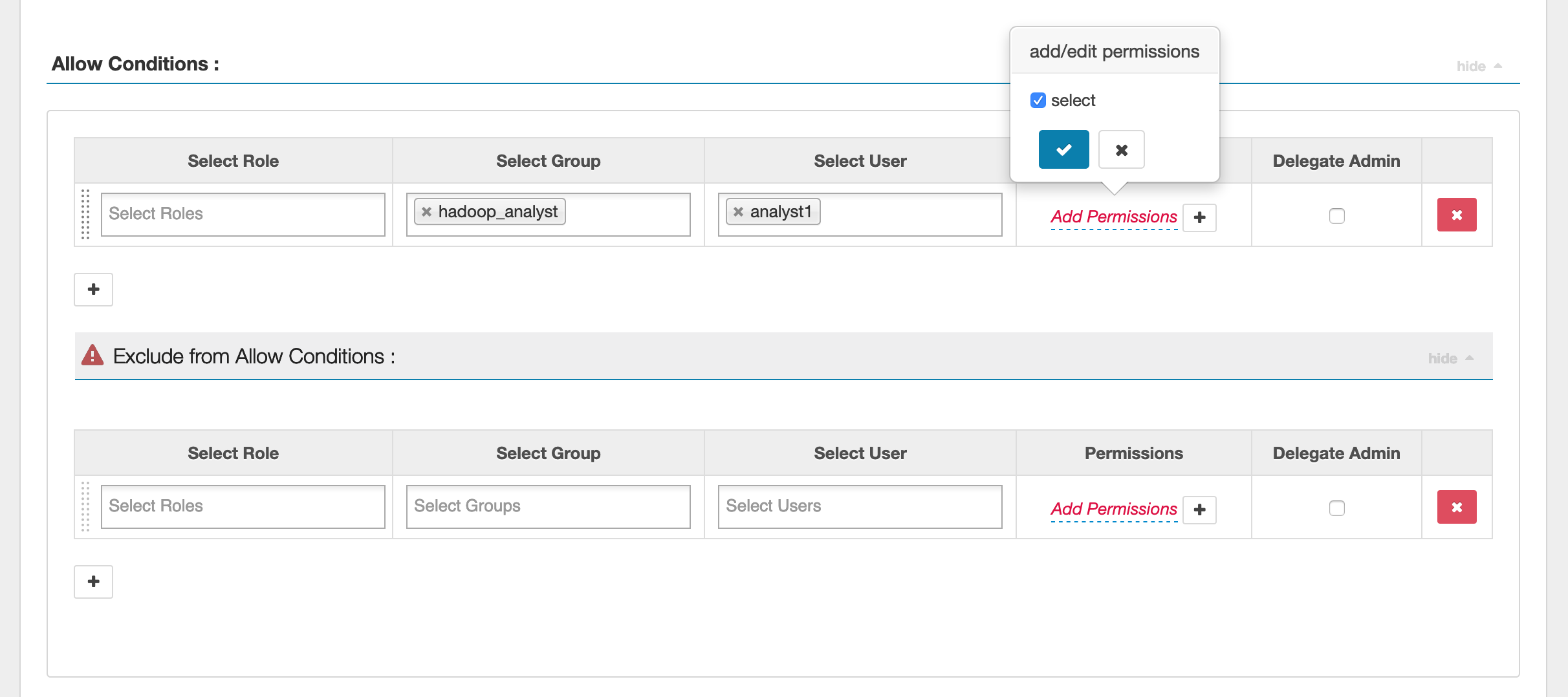
指定允许和拒绝条件后,单击 **Save (保存)**。
## 注意事项
EMR 集群中的每个节点都必须能够通过端口 9083 连接到主节点。
## 限制
以下是当前针对 Apache Spark 插件的限制:
+ Record 服务器将始终连接到 Amazon EMR 集群上运行的 HMS。如果需要,将 HMS 配置为连接到远程模式。不应将配置值放入 Apache Spark Hive-site.xml 配置文件中。
+ 使用 EMR 无法读取在 CSV 或 Avro 上使用 Spark 数据源创建的表。 RecordServer使用 Hive 创建和写入数据,并使用 Record 读取。
+ 不支持 Delta Lake、Hudi 和 Iceberg 表。
+ 用户必须有权访问默认数据库。这是 Apache Spark 的要求。
+ Ranger Admin 服务器不支持自动完成。
+ Amazon EMR 的 SparkSQL 插件不支持行筛选器或数据掩码。
+ 将 ALTER TABLE 与 Spark SQL 结合使用时,分区位置必须是表位置的子目录。不支持将数据插入分区位置与表位置不同的分区中。