本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
Amazon EMR 开启 EC2 — CloudWatch 使用自定义指标和日志进行增强监控
概览
Amazon EMR 提供了强大、经济实惠的大数据处理功能。要最大限度地提高性能和资源利用率,必须进行有效的监控。Amazon 为 EMR 集群 CloudWatch 提供了全面的可观察性,使您能够实时跟踪指标和日志。本文档概述了如何:
-
将 CloudWatch 代理配置为将日志上 EC2 的 EMR 发送到 CloudWatch
-
通过分类添加自定义 Hadoop、YARN 和 HBase 指标
-
通过内置仪表板监控指标
-
通过日志组跟踪集群 CloudWatch 日志
先决条件和背景
默认情况下,Amazon EMR CloudWatch 每五分钟向其发送一次基本指标,不收取额外费用。在 EMR 7.0+ 版本中,您可以将代理部署到: CloudWatch
-
每隔一分钟收集 34 个额外的详细指标(需支付额外费用)
-
从所有集群节点收集指标
-
在将数据发送到主节点之前,先聚合主节点上的数据 CloudWatch
-
通过 EMR 控制台的 “监控” 选项卡或控制台访问指标 CloudWatch
EMR 7.1 扩展了这些功能,允许您将代理配置为从 Hadoop、YARN 和组件中捕获专门的指标。 HBase 对于使用 Prometheus 的环境,可以将指标转发到适用于 Prometheus 的亚马逊托管服务。
CloudWatch 日志的代理配置
要捕获 EMR 登录信息 CloudWatch,请创建一个 c loudwatch-config.json 文件来定义要收集哪些日志文件:
cloudwatch-config.
{ "logs": { "logs_collected": { "files": { "collect_list": [ { "file_path": "/mnt/var/log/hadoop-yarn/hadoop-yarn-resourcemanager-*", "log_group_name": "/emr/yarn/resourcemnger", "log_stream_name": "{instance_id}", "publish_multi_logs" : true }, { "file_path": "/var/log/hadoop-hdfs/hadoop-hdfs-namenode-*", "log_group_name": "/emr/hdfs/namenode", "log_stream_name": "{instance_id}", "publish_multi_logs" : true } ] } } }
用于 CloudWatch 代理配置的引导脚本
要将您的自定义 CloudWatch 配置应用于 EMR 节点,请创建一个引导脚本,该脚本将使用您的设置重新启动 CloudWatch 代理。此脚本可确保代理在集群配置后使用您的特定日志收集参数运行。
创建引导脚本
创建一个名为 cloudwatch-agent-bootstrap.sh 的文件,其中包含以下内容:
#!/bin/bash set -xe EMR_SECONDARY_BA_SCRIPT=$(cat <<'EOF' while true; do NODEPROVISIONSTATE=$(sed -n '/localInstance [{]/,/[}]/ {/nodeProvisionCheckinRecord [{]/,/[}]/ {/status:/ p}}' /emr/instance-controller/lib/info/job-flow-state.txt | awk '{ print $2 }') if [ "$NODEPROVISIONSTATE" == "SUCCESSFUL" ]; then sleep 10 echo "Running my post provision bootstrap" NODETYPE=$(cat /mnt/var/lib/instance-controller/extraInstanceData.json | jq -r '.instanceRole' | awk '{print tolower($0)}') # Copy config file on the instance sudo aws s3 cp s3://amzn-s3-demo-bucket1/cloudwatch-config.json /opt/aws/amazon-cloudwatch-agent/etc/stdout_log_config.json # Start the agent with the created config file sudo /opt/aws/amazon-cloudwatch-agent/bin/amazon-cloudwatch-agent-ctl -m ec2 -a append-config -c file:/opt/aws/amazon-cloudwatch-agent/etc/stdout_log_config.json # Restart CW Agent sudo systemctl restart amazon-cloudwatch-agent # Status CW Agent echo "Status CW Agent" sudo /usr/bin/amazon-cloudwatch-agent-ctl -m ec2 -a status exit fi sleep 10 done EOF ) echo "${EMR_SECONDARY_BA_SCRIPT}" | tee -a /tmp/emr-secondary-ba.sh chmod u+x /tmp/emr-secondary-ba.sh /tmp/emr-secondary-ba.sh > /tmp/emr-secondary-ba.log 2>&1 & exit 0
用您的存储桶名称替换示例存储桶。
重要配置说明
重要
在上传脚本之前,请<amzn-s3-demo-bucket1>替换为您存储上一步中的 c loudwatch-config.json 文件的 S3 存储桶的实际名称。这样可以确保引导脚本可以在集群初始化期间检索您的配置文件。
这个引导脚本将:
-
等待节点配置完成
-
下载您的自定义 CloudWatch 配置
-
停止任何正在运行的 CloudWatch 代理
-
使用您的特定配置重新启动代理
-
记录代理的状态以进行故障排除
Hadoop、YARN 和 HBase
除了默认 CloudWatch 指标外,您还可以通过为 EMR 集群组件配置特定于应用程序的自定义指标来增强监控能力。Amazon EMR 的配置 API 提供了一种灵活的方式来准确定义您要收集的指标。
配置自定义指标
您可以通过两种方式实现自定义指标收集:
-
在为新集群创建集群期间
-
通过 EMR 控制台对现有集群进行重新配置
创建分类文件
分类文件定义了应从集群中收集哪些特定组件指标。以下是收集自定义 Hadoop 指标的示例结构:
[ { "Classification": "emr-metrics", "Configurations": [ { "Classification": "emr-hadoop-hdfs-datanode-metrics", "Properties": { "Hadoop:service=DataNode,name=DataNodeActivity-*": "DatanodeNetworkErrors,TotalReadTime,TotalWriteTime,BytesRead,BytesWritten,RemoteBytesRead,RemoteBytesWritten,ReadBlockOpNumOps,ReadBlockOpAvgTime,WriteBlockOpNumOps,WriteBlockOpAvgTime", "otel.metric.export.interval": "30000" } }, { "Classification": "emr-hadoop-yarn-nodemanager-metrics", "Properties": { "Hadoop:service=NodeManager,name=JvmMetrics": "MemNonHeapUsedM,MemNonHeapCommittedM,MemNonHeapMaxM,MemHeapUsedM,MemHeapCommittedM,MemHeapMaxM,MemMaxM", "Hadoop:service=NodeManager,name=NodeManagerMetrics": "ContainerCpuUtilization,NodeCpuUtilization,ContainersCompleted,ContainersFailed,ContainersKilled,ContainersLaunched,ContainersRolledBackOnFailure,ContainersRunning,ContainerUsedMemGB,ContainerUsedVMemGB,ContainerLaunchDurationNumOps,ContainerLaunchDurationAvgTime", "otel.metric.export.interval": "20000" } } ], "Properties": {} } ]
实施步骤
-
创建包含所需指标分类的 JSON 文件。
-
根据您的监控要求自定义指标。
-
保存文件并将其上传到您的 S3 存储桶。
-
创建新集群或重新配置现有集群时,请引用此文件。
最佳实践
-
仅收集能为您的工作负载提供有意义见解的指标。
-
根据您的监控需求考虑指标收集间隔。
-
查看 Amazon 文档,了解每个组件的可用指标的完整列表。
-
将相关指标分组到同一个分类中,以便更好地进行组织。
这种方法使您可以将监控重点放在特定 EMR 应用程序的最关键指标上,从而更深入地了解集群性能。
部署具有集成功能的 EMR 集群 CloudWatch
按照以下步骤创建 Amazon EMR 集群,该集群会自动将日志和自定义指标发送到: CloudWatch
步骤 1:启用代 CloudWatch 理
通过 Amazon 管理控制台创建 EMR 集群时:
-
在创建集群期间,导航到 “应用程序” 部分。
-
选中您的主要应用程序(Hadoop、Spark 等)的复选框。
-
滚动查找并选择 Amazon A CloudWatch gent 选项。
-
这将在您的集群上启用代理,这对于收集增强的指标和日志至关重要。
CloudWatch 代理将安装在集群中的所有节点上,使其能够按配置的时间间隔收集系统和应用程序指标。
名称和应用程序
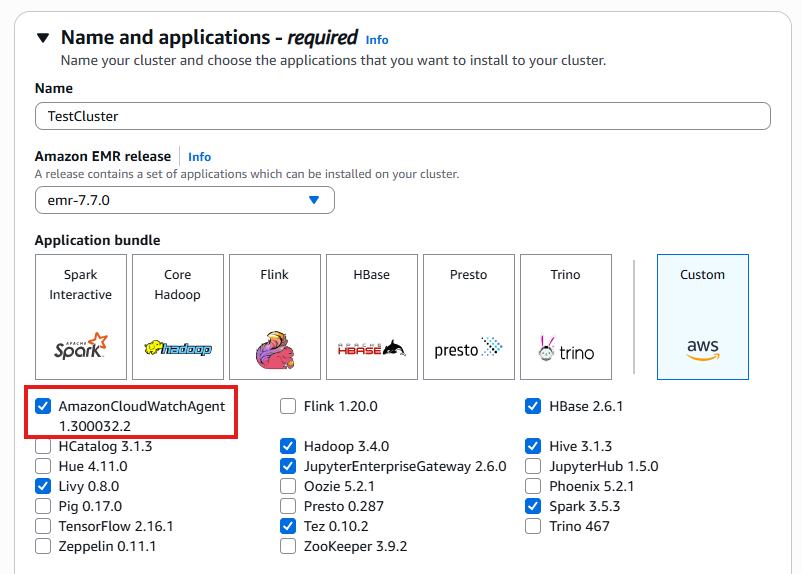
创建集群并显示可用的捆绑包。
注意
该 CloudWatch 代理在 EMR 7.0 及更高版本中可用。本指南中描述的自定义指标收集和日志转发需要启用此组件。
步骤 2:为日志收集添加引导操作
要将 CloudWatch 代理配置为收集特定日志文件并将其转发到 CloudWatch:
-
在 EMR 集群创建向导中,导航到 “引导操作” 部分
-
单击 “添加引导操作”
-
从下拉菜单中选择自定义操作
-
为您的引导操作提供一个名称(例如,配置 CloudWatch 代理)
-
在脚本位置字段中,输入 cloudwatch-agent-bootstrap .sh 脚本的 S3 路径(例如 s3://your-bucket-name/cloudwatch-agent-bootstrap.sh)
-
单击 “添加” 以保存引导操作
此引导操作将在集群启动期间执行,确保使用您的自定义设置正确配置,以收集和转发配置文件中指定的日志文件。 CloudWatchagent
配置节点后,代理将自动开始收集日志,从而通过 CloudWatch 日志提供对集群操作的近乎实时的可见性。
Bootstrap actions (引导操作)
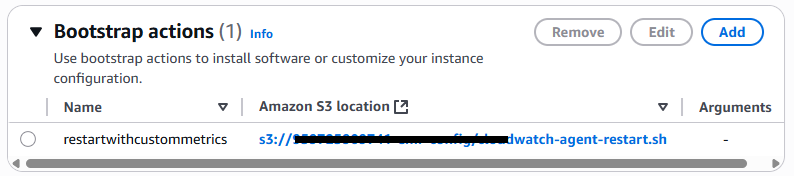
使用引导操作。
步骤 3:配置自定义指标集合
要启用自定义 Hadoop、YARN 或超出默认设置的 HBase 指标的收集,请执行以下操作:
-
在 EMR 集群创建向导中,导航到配置部分。
-
单击 “编辑配置” 按钮展开配置选项。
-
从配置方法下拉列表中选择从 Amazon S3 加载 J SON 选项。
-
输入您的自定义指标分类文件的 S3 URI 路径(例如 s3://amzn-s3-demo-bucket1/ emr-metrics-classification .json)。
-
单击 “加载” 解析配置。
-
验证配置是否正确显示在控制台界面中。
-
单击 “保存更改”,将这些指标配置应用于您的集群。
此步骤指示 CloudWatch 代理收集分类文件中定义的特定组件指标。这些指标将按您的配置中指定的时间间隔收集并发布到 CloudWatch,在那里可以对其进行可视化和分析。
自定义指标可以更深入地了解集群的性能特征,从而可以更精确地监控和排查您的 EMR 应用程序。
软件设置
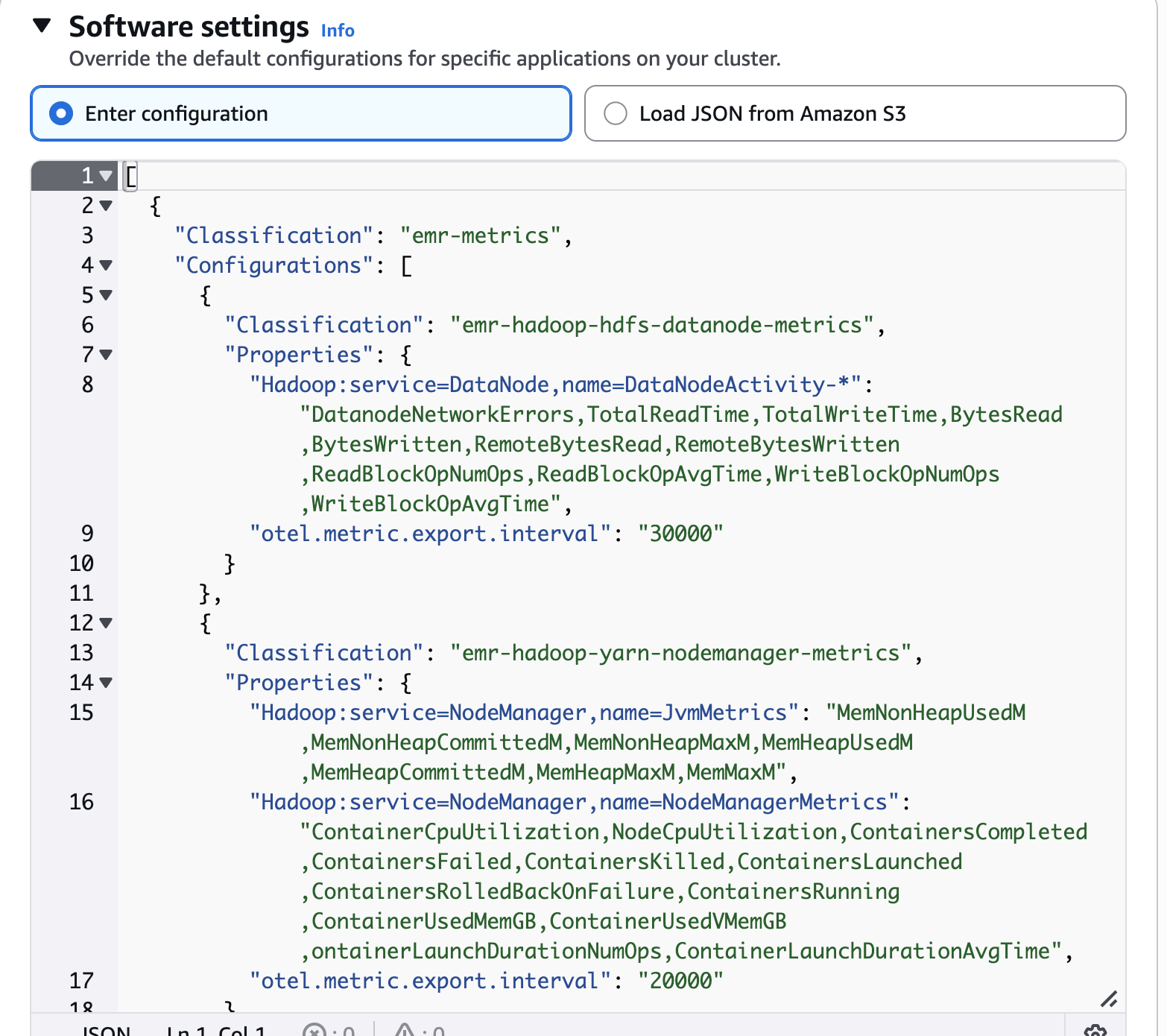
覆盖默认配置。
更新正在运行的集群的指标配置
您可以按照以下步骤修改现有 EMR 集群的指标收集设置,而不会中断操作:
-
在 Amazon 管理控制台中导航到您的活动 EMR 集群。
-
在集群详细信息视图中选择配置选项卡。
-
找到实例组配置部分。
-
单击 “重新配置” 按钮修改设置。
-
选择从 Amazon S3 加载 J SON 或直接编辑配置。
-
输入更新后的指标分类文件位置或在编辑器中进行更改。
-
应用更改以更新指标收集行为。
这种重新配置功能允许您随着工作负载需求的变化而调整监控方法。 CloudWatch 代理将自动适应新的配置,无需重新启动集群或停机即可收集更新的指标集。
重要
配置更改可能需要几分钟才能传播到群集中的所有节点。继续监控您的 CloudWatch 仪表板,以确认新指标按预期显示。
集群配置
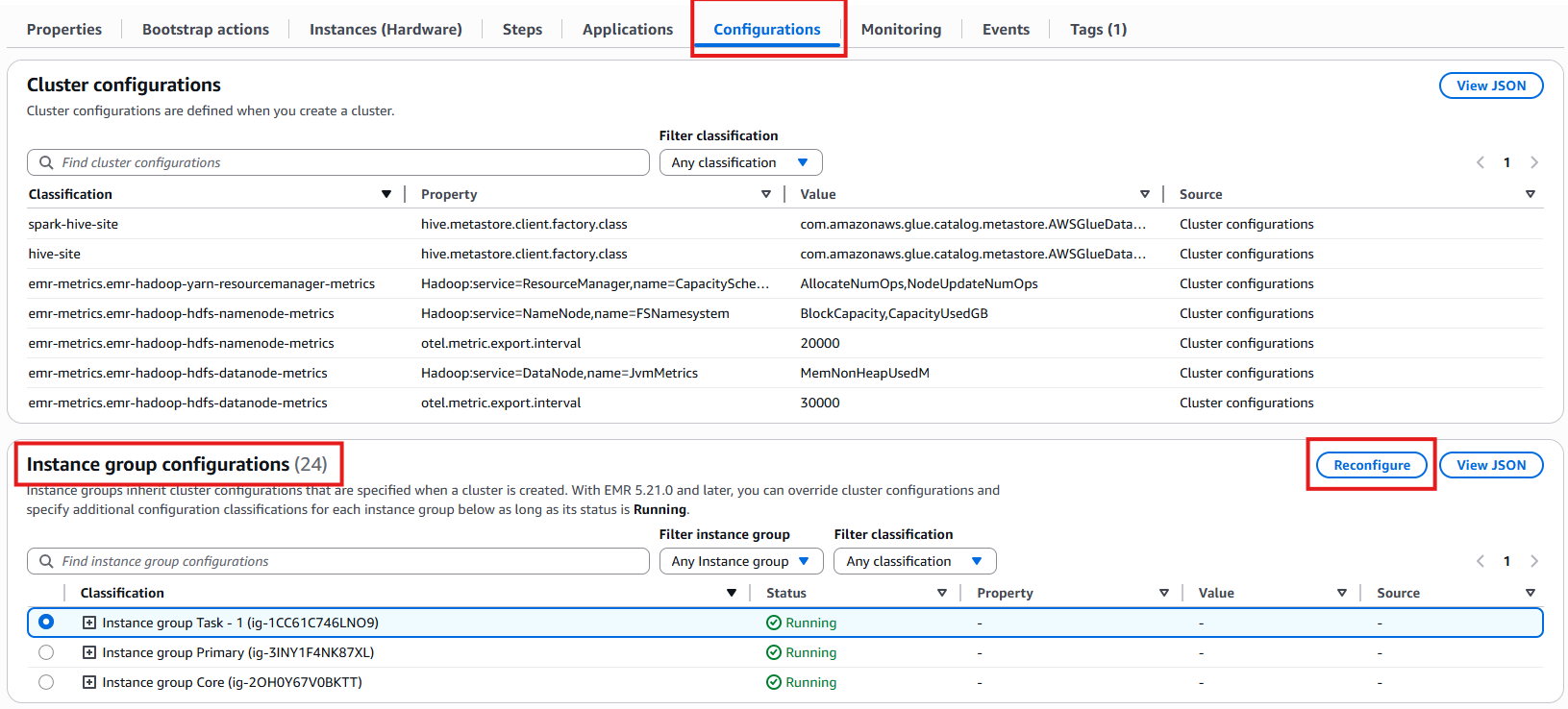
实例组配置。
验证您的集成 CloudWatch
完成配置步骤后,是时候验证您的监控设置是否正常运行了:
步骤 1:部署 EMR 集群
-
检查所有配置设置以确保准确性。
-
确保正确引用了引导操作和分类文件。
-
单击 “创建集群” 以启动您的 EMR 环境。
-
等待集群进入运行状态(通常为 5-15 分钟)。
步骤 2:执行测试应用程序
提交多个测试 Spark 应用程序以生成有意义的指标:
-
运行一个处理示例数据的简单 Spark 作业。
-
执行运行时间较长的分析任务以观察资源利用率。
-
测试不同的应用程序配置以比较性能指标。
应用程序完成后(或正在运行时):
-
导航到 CloudWatch 控制台。
-
检查您配置的日志组中是否有应用程序日志。
-
检查指标仪表板,观察特定于 CPU、内存和应用程序的指标。
-
验证分类文件中定义的自定义指标是否出现在中 CloudWatch。
此验证过程可确认您的 CloudWatch 集成是否正确捕获了日志和指标,从而使您可以全面了解 EMR 集群的性能和应用程序行为。
访问日志组中的 CloudWatch EMR 日志
在 EMR 集群运行并正确配置 CloudWatch 代理之后,您的应用程序和系统日志将显示在日志中 CloudWatch 。请按照以下步骤访问和分析它们:
查看您的日志组
-
在 Amazon 管理 CloudWatch 控制台中导航到控制台。
-
从左侧导航窗格中选择日志组。
-
查找由您的配置创建的日志组,例如:
-
/emr/yarn/resourcemnger用于 YARN ResourceManager 日志。
-
/emr/hdfs/namenode用于 HDFS NameNode 日志。
-
配置文件中指定的任何其他日志组。
-
每个日志组都包含按实例 ID 组织的日志流,允许您跟踪集群中特定节点的日志。
处理日志数据
-
搜索日志数据:使用 Lo CloudWatch gs Insights 在日志组中执行结构化查询。
-
创建指标:从日志模式中提取指标以创建自定义 CloudWatch 指标。
-
设置警报:根据特定的错误模式或日志频率配置警报。
-
导出日志:下载日志以进行离线分析或存档。
日志保留
注意
默认情况下,日志保留 30 天。如果出于合规性或分析目的需要,您可以修改每个日志组的保留策略,以便将日志保留更长的时间。
CloudWatch 日志为您的所有 EMR 日志数据提供了一个集中位置,无需通过 SSH 连接到各个集群节点来解决问题或分析应用程序行为。
在 EMR 监控控制面板中查看自定义指标
使用 CloudWatch 代理和自定义指标配置运行 EMR 集群后,您可以直接在 EMR 控制台中轻松监控这些指标:
访问您的自定义指标
-
在 Amazon 管理控制台中导航到您的 EMR 集群。
-
在集群详细信息页面中选择监控选项卡。
-
找到监控仪表板顶部附近的筛选指标分类下拉列表。
-
使用此筛选器选择特定的指标类别:
-
选择要查看的 HDFS NameNode 和 DataNode 指标。
-
选择 YARN 以查看 ResourceManager 容器指标。
-
选择 HBase特HBase定的性能数据。
-
选择您定义的自定义指标分类。
-
控制面板将动态更新以显示所选指标的图表,显示一段时间内的绩效趋势。
使用指标可视化
-
调整时间范围:更改时间窗以查看最近的活动或历史趋势。
-
比较指标:显示多个相关指标 side-by-side以进行相关性分析。
-
缩放功能:专注于出现异常或模式的特定时间段。
-
刷新数据:使用最新的指标数据近乎实时地更新可视化效果。
这种集成的监控方法允许您在统一的控制面板中跟踪标准 EMR 指标和自定义指标,从而无需离开 EMR 控制台即可更轻松地识别性能问题、资源限制或应用程序瓶颈。
CloudWatch 指标
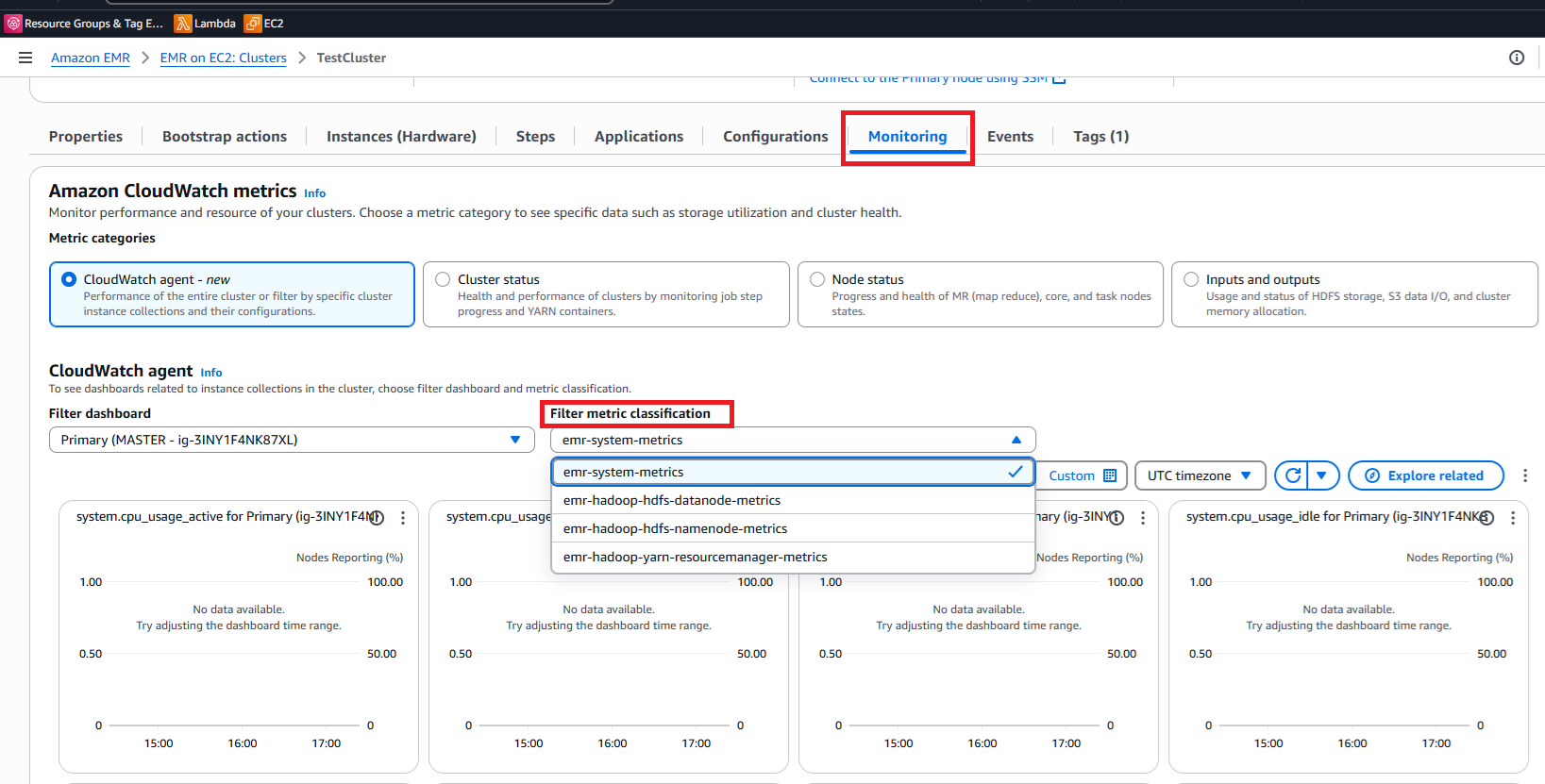
筛选指标分类。