本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
Amazon EMR 的高级扩展
从 Amazon EMR on EC2 版本 7.0 开始,您可以利用高级扩展来控制集群的资源利用率。Advanced Scaling 引入了利用率-性能量表,用于根据业务需求调整资源利用率和性能级别。您设置的值决定了您的集群是更侧重于资源节约,还是更侧重于纵向扩展以处理快速完成至关重要的对服务水平协议 (SLA) 敏感的工作负载。当调整扩展值时,托管扩展会解释您的意图并智能地进行扩展以优化资源。有关托管扩展的更多信息,请参阅为 Amazon EMR 配置托管扩展。
高级缩放设置
您为高级扩展设置的值会根据您的需求优化集群。值范围为 1-100。可能的值为 1、25、50、75 和 100。如果将索引设置为除这些值之外的其他值,则会导致验证错误。
扩展值与资源利用率策略相对应。以下列表定义了其中几个:
利用率优化 [1]:此设置可防止资源过度预置。当您希望降低成本并优先考虑高效的资源利用率时,请使用较低的值。它会导致集群纵向扩展不太激进。这对于经常出现工作负载峰值并且您不希望资源增长过快的使用案例非常有效。
平衡 [50]:这可以平衡资源利用率和作业性能。此设置适用于大多数阶段都有稳定运行时的稳定工作负载。它也适用于混合了短期和长期运行阶段的工作负载。如果不确定要选择哪个设置,建议从此设置开始。
性能优化 [100] - 此策略优先考虑性能。集群会积极纵向扩展,以确保作业快速完成并达到性能目标。性能优化适用于快速运行时间至关重要的对服务水平协议 (SLA) 敏感的工作负载。
注意
可用的中间值在各种策略之间提供中间地带,以便微调集群的高级扩展行为。
高级缩放的好处
由于您的环境和要求存在变化(例如,更改数据量、成本目标调整和 SLA 实施等),集群扩展可以帮助您调整集群配置以实现目标。主要优势包括:
增强的精细控制:引入利用率-性能设置使您能够根据要求轻松调整集群的扩展行为。您可以根据自己的使用模式纵向扩展以满足对计算资源的需求,也可以缩减以节省资源。
改善成本优化:您可以根据要求选择低利用率值,以便更轻松地实现成本目标。
开始使用优化
设置和配置
按照以下步骤设置性能指标并优化扩展策略。
以下命令使用利用率优化的
[1]扩展策略更新现有集群:aws emr put-managed-scaling-policy --cluster-id 'cluster-id' \ --managed-scaling-policy '{ "ComputeLimits": { "UnitType": "Instances", "MinimumCapacityUnits": 1, "MaximumCapacityUnits": 2, "MaximumOnDemandCapacityUnits": 2, "MaximumCoreCapacityUnits": 2 }, "ScalingStrategy": "ADVANCED", "UtilizationPerformanceIndex": "1" }' \ --region "region-name"属性
ScalingStrategy和UtilizationPerformanceIndex是新增的,与扩展优化相关。您可以通过在托管扩展策略中为UtilizationPerformanceIndex属性设置相应的值(1、25、50、75 和 100)来选择不同的扩展策略。要恢复到默认托管扩展策略,请运行
put-managed-scaling-policy命令,但不要包含ScalingStrategy和UtilizationPerformanceIndex属性。(这是可选的。) 以下示例展示了如何执行此操作:aws emr put-managed-scaling-policy \ --cluster-id 'cluster-id' \ --managed-scaling-policy '{"ComputeLimits":{"UnitType":"Instances","MinimumCapacityUnits":1,"MaximumCapacityUnits":2,"MaximumOnDemandCapacityUnits":2,"MaximumCoreCapacityUnits":2}}' \ --region "region-name"
使用监控指标跟踪集群利用率
从 EMR 版本 7.3.0 开始,Amazon EMR 发布了四个与内存和虚拟 CPU 相关的新指标。您可以使用这些指标来衡量各个扩展策略的集群利用率。这些指标适用于任何使用案例,但您可以使用此处提供的详细信息来监控高级扩展。
可用的有用指标包括:
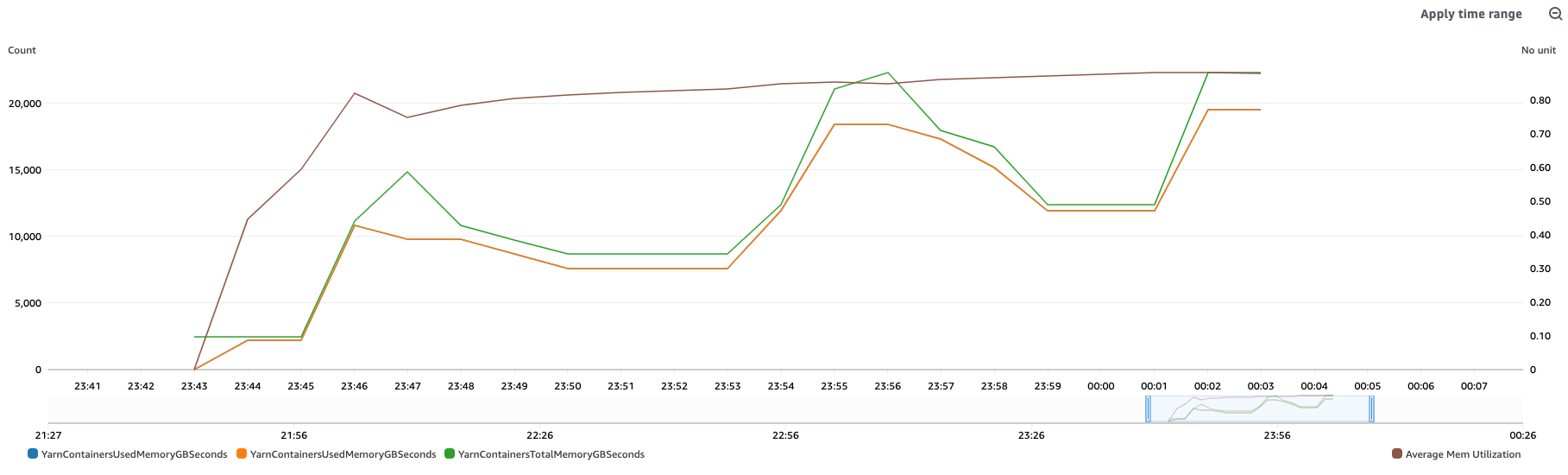
YarnContainersUsedMemoryGBSeconds— 由 YARN 管理的应用程序消耗的内存量。
YarnContainersTotalMemoryGBSeconds— 集群内分配给 YARN 的总内存容量。
YarnNodesUsedVCPUSeconds— 由 YARN 管理的每个应用程序的 VCPU 总秒数。
YarnNodesTotalVCPUSeconds— 消耗的内存总计 VCPU 秒数,包括 yarn 未准备就绪的时间窗口。
您可以使用 Logs Insight Amazon CloudWatch s 分析资源指标。功能包括一种专门构建的查询语言,可帮助您提取与资源使用和扩展相关的指标。
以下查询可以在 Amazon CloudWatch 控制台中运行,它使用度量数学计算平均内存利用率 (e1),方法是将消耗内存的运行总和 (e2) 除以总内存的运行总和 (e3):
{ "metrics": [ [ { "expression": "e2/e3", "label": "Average Mem Utilization", "id": "e1", "yAxis": "right" } ], [ { "expression": "RUNNING_SUM(m1)", "label": "RunningTotal-YarnContainersUsedMemoryGBSeconds", "id": "e2", "visible": false } ], [ { "expression": "RUNNING_SUM(m2)", "label": "RunningTotal-YarnContainersTotalMemoryGBSeconds", "id": "e3", "visible": false } ], [ "AWS_EMR_ManagedResize", "YarnContainersUsedMemoryGBSeconds", "ACCOUNT_ID", "793684541905", "COMPONENT", "ManagerService", "JOB_FLOW_ID", "cluster-id", { "id": "m1", "label": "YarnContainersUsedMemoryGBSeconds" } ], [ ".", "YarnContainersTotalMemoryGBSeconds", ".", ".", ".", ".", ".", ".", { "id": "m2", "label": "YarnContainersTotalMemoryGBSeconds" } ] ], "view": "timeSeries", "stacked": false, "region": "region", "period": 60, "stat": "Sum", "title": "Memory Utilization" }
要查询日志,可以在 Amazon 控制台 CloudWatch 中选择。有关为编写查询的更多信息 CloudWatch,请参阅 Amazon Logs 用户指南中的使用 Lo CloudWatch gs Insights 分析 CloudWatch 日志数据。
下图显示了示例集群的这些指标:
注意事项和限制
扩展策略的有效性可能因您的工作负载特性和集群配置而异。我们建议您尝试不同的扩展设置,以确定最适合您使用案例的索引值。
Amazon EMR 高级扩展尤其适用于批处理工作负载。对于 SQL/data-warehousing 流式处理工作负载,我们建议使用默认的托管扩展策略以获得最佳性能。
在集群中启用节点标签配置时,不支持 Amazon EMR 高级扩展。如果在集群中同时启用了高级扩展和节点标签配置,则扩展行为就像启用了默认的托管扩展设置一样。
性能优化型扩展策略能够比默认托管扩展策略更长时间地保持高计算资源,从而加快作业执行速度。这种模式优先考虑快速纵向扩展以满足资源需求,从而加快作业完成速度。与默认策略相比,这可能会导致成本更高。
如果集群已经过优化并充分利用,启用高级扩展可能不会带来额外好处。在某些情况下,启用高级扩展可能会导致成本增加,因为工作负载可能会运行更长时间。在这些情况下,我们建议使用默认托管扩展策略,以确保最佳资源分配和成本效益。
在托管扩展环境中,随着设置从性能优化 [100] 调整为利用率优化 [1],重点从执行时间转向资源利用率。但是请务必注意,结果可能会因工作负载的性质和集群的拓扑而异。为确保您的使用案例获得最佳效果,强烈建议您使用工作负载测试扩展策略,以确定最合适的设置。
仅PerformanceUtilizationIndex接受以下值:
1
25
50
75
100
提交的任何其他值都会导致验证错误。