本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
HBase 在亚马逊 S3(亚马逊 S3 存储模式)上
当你 HBase 在 Amazon EMR 5.2.0 或更高版本上运行时,你可以 HBase 在 Amazon S3 上启用,它具有以下优势:
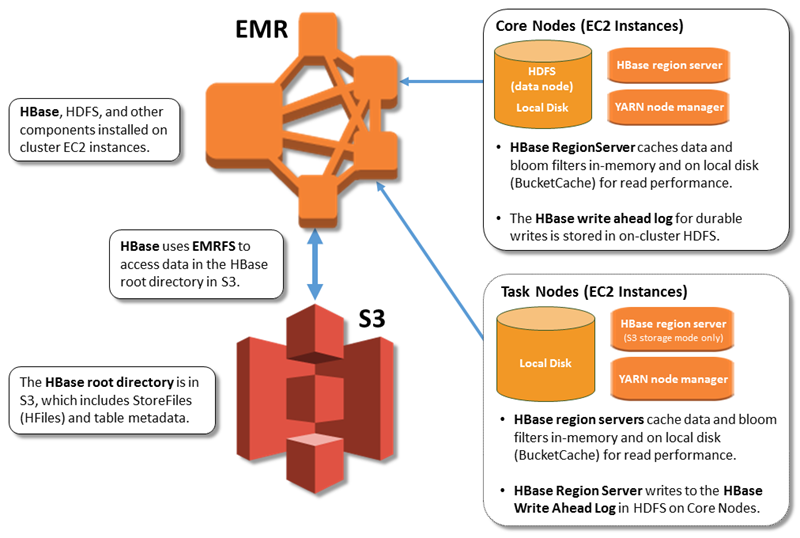
HBase 根目录存储在 Amazon S3 中,包括 HBase 存储文件和表元数据。此数据在集群外部持续存在且可跨 Amazon EC2 可用区访问,您无需使用快照或其它方法进行恢复。
对于 Amazon S3 中的存储文件,您可以针对计算要求而非数据要求调整 Amazon EMR 集群的大小(在 HDFS 上为 3 倍复制)。
使用 Amazon EMR 版本 5.7.0 及更高版本,您可设置只读副本集群,这允许您将数据的只读副本保留在 Amazon S3 中。如果主集群变得不可用,您可以访问只读副本集群中的数据以同时执行读取操作。
在 Amazon EMR 6.2.0 到 7.3.0 版本中,持久 HFile 跟踪使用名为的 HBase 系统表
hbase:storefile来直接跟踪用于读取操作的 HFile 路径。默认情况下,此功能处于启用状态,不需要执行手动迁移。在高于 7.3.0 的版本中, HFile 使用文件跟踪器跟踪HFile 路径,将路径直接存储在存储目录中的元文件中。
注意
使用 7.4.0 之前的 Amazon EMR 版本并迁移到 EMR-7.4.0 及更高版本的用户,请参阅从先前 HBase 版本迁移并按照可用的升级文档进行操作,以确保平稳过渡。
下图显示了 Amazon S3 HBase 上与相关的 HBase 组件。
HBase 在 Amazon S3 上启用
您可以使用亚马逊 EMR 控制台、或亚马逊 EMR API 在 Amazon S3 HBase 上启用。 Amazon CLI该配置是集群创建期间的一个选项。使用控制台时,您可以通过 Advanced options (高级选项) 选择相应设置。在使用 Amazon CLI时,使用 --configurations 选项提供 JSON 配置对象。配置对象的属性指定了 Amazon S3 中的存储模式和根目录位置。您指定的 Amazon S3 位置应位于 Amazon EMR 集群所在的区域内。在 Amazon S3 中,一次只能有一个活动集群使用同一个HBase 根目录。有关控制台步骤和使用创建集群的详细示例 Amazon CLI,请参阅。使用创建集群 HBase以下 JSON 代码段中显示了示例配置对象。
{ "Classification": "hbase-site", "Properties": { "hbase.rootdir": "s3://amzn-s3-demo-bucket/my-hbase-rootdir"} }, { "Classification": "hbase", "Properties": { "hbase.emr.storageMode":"s3" } }
注意
如果您使用 Amazon S3 存储桶作为 f rootdir o HBase r,则必须在 Amazon S3 URI 的末尾添加一个斜杠。例如,为了避免出现问题,您必须使用 "hbase.rootdir: s3://amzn-s3-demo-bucket/",而不是 "hbase.rootdir: s3://amzn-s3-demo-bucket"。
使用只读副本集群
在 Amazon S3 HBase 上使用设置主集群后,您可以创建和配置一个只读副本集群,该集群提供对与主集群相同数据的只读访问权限。当您需要同步访问权限以查询数据或在主集群变得不可用的情况下进行连续访问时,这会很有用。只读副本功能适用于 Amazon EMR 5.7.0 版和更高版本。
主集群和只读副本集群的设置方式相同,但有一个重要差异。两者都指向相同的 hbase.rootdir 位置。不过,只读副本集群的 hbase 分类包括 "hbase.emr.readreplica.enabled":"true" 属性。
只读副本集群设计用于只读操作,不应对其执行任何手动压缩或写入操作。对于 7.4.0 之前的 Amazon EMR 版本,当启用了只读副本功能时,建议在只读副本集群上禁用压缩。这种预防措施是必要的,因为在主群集上启用了持续 HFile 跟踪功能后,只读副本群集可能会压缩系统表,这可能会导致主群集 FileNotFoundException 上出现问题。在只读副本集群上禁用压缩可防止主集群和只读副本集群之间的数据不一致。
例如,对于前面主题中所示的主集群的 JSON 分类,EMR 版本低于 7.4.0 的只读副本集群的配置如下:
{ "Classification": "hbase-site", "Properties": { "hbase.rootdir": "s3://amzn-s3-demo-bucket/my-hbase-rootdir", "hbase.regionserver.compaction.enabled": "false" } }, { "Classification": "hbase", "Properties": { "hbase.emr.storageMode":"s3", "hbase.emr.readreplica.enabled":"true" } }
对于 7.3.0 之后的 Amazon EMR 版本,我们现在使用存储文件跟踪功能,因此无需禁用压缩。
添加数据时同步只读副本
由于只读副本 HBase StoreFiles 和主集群写入 Amazon S3 的元数据,因此只读副本仅与 Amazon S3 数据存储一样最新。在写入数据时,以下指导信息可帮助您最大程度地缩短主集群和只读副本之间的滞后时间。
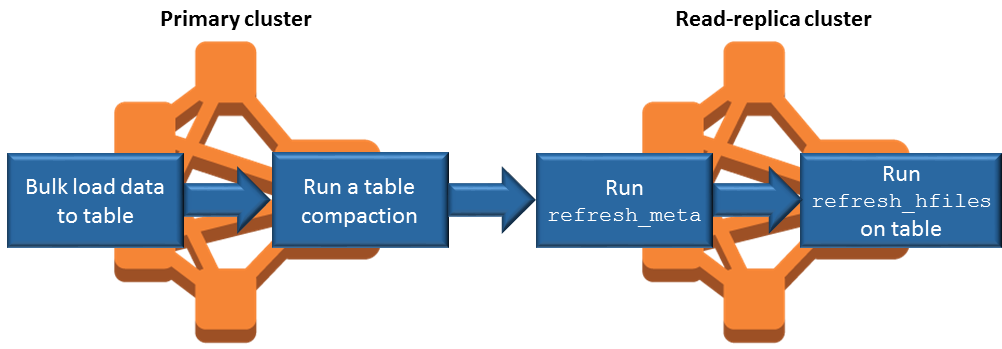
如果可能,请在主集群上批量加载数据。有关更多信息,请参阅 Apache HBase 文档中的批量加载
。 将存储文件写入 Amazon S3 的刷新操作应在添加数据后尽快进行。手动刷新或优化刷新设置以最大限度地减少滞后时间。
如果压缩可能会自动运行,请运行手动压缩以避免触发压缩时出现不一致。
在只读副本集群上,当任何元数据发生更改时(例如,发生 HBase 区域拆分或压缩时,或者添加或删除表时),请运行该
refresh_meta命令。在只读副本集群上,在表中添加或更改记录后,运行
refresh_hfiles命令。
持续 HFile 跟踪
持续 HFile 跟踪使用名为的 HBase 系统表hbase:storefile来直接跟踪用于读取操作的 HFile 路径。向表中添加更多数据后,会向表中添加新的 HFile 路径 HBase。这删除了在关键写入路径操作中作为提交机制的重命名 HBase 操作,并通过从hbase:storefile系统表中读取而不是文件系统目录列表来缩短打开 HBase 区域时的恢复时间。此功能在 Amazon EMR 版本 6.2.0 至 7.3.0 中默认启用,无需任何手动迁移步骤。
注意
使用 HBase storefile 系统表进行持续 HFile 跟踪不支持 HBase 区域复制功能。有关 HBase 区域复制的更多信息,请参阅时间轴一致的高可用读取
禁用持续 HFile 跟踪
从 Amazon EMR 6.2.0 版本开始,永久 HFile 跟踪默认处于启用状态。要禁用持续 HFile 跟踪,请在启动集群时指定以下配置替代:
{ "Classification": "hbase-site", "Properties": { "hbase.storefile.tracking.persist.enabled":"false", "hbase.hstore.engine.class":"org.apache.hadoop.hbase.regionserver.DefaultStoreEngine" } }
注意
重新配置 Amazon EMR 集群时,必须更新所有实例组。
手动同步存储文件表
创建新 HFile 实例后,storefile 表会保持最新状态。但是,如果 storefile 表由于任意原因与数据文件不同步,则可以使用以下命令手动同步数据:
同步线上区域中的存储文件表:
hbase org.apache.hadoop.hbase.client.example.RefreshHFilesClient <table>
同步离线区域中的存储文件表:
删除存储文件表 znode。
echo "ls /hbase/storefile/loaded" | sudo -u hbase hbase zkcli [<tableName>, hbase:namespace] # The TableName exists in the list echo "delete /hbase/storefile/loaded/<tableName>" | sudo -u hbase hbase zkcli # Delete the Table ZNode echo "ls /hbase/storefile/loaded" | sudo -u hbase hbase zkcli [hbase:namespace]分配区域(在“hbase shell”中运行)。
hbase cli> assign '<region name>'如果分配失败。
hbase cli> disable '<table name>' hbase cli> enable '<table name>'
扩缩存储文件表
默认情况下,存储文件表可拆分为四个区域。如果存储文件表的写入负载仍然较重,之后可以手动拆分该表。
要拆分特定的热点区域,请使用以下命令(在“hbase shell”中运行)。
hbase cli> split '<region name>'
要拆分该表,请使用以下命令(在“hbase shell”中运行)。
hbase cli> split 'hbase:storefile'
存储文件跟踪
默认情况下,我们使用FileBasedStoreFileTracker实现。此实现直接在存储目录中创建新文件,无需进行重命名操作。它在内存中保存已提交的 hfile 实例列表,以每个存储目录中的元文件为后盾。每当提交新的 hfile 时,给定存储中的跟踪文件列表都会更新,并使用列表内容写入新的元文件,同时丢弃包含过时列表的先前元文件。有关存储文件跟踪的更多信息, HBase 请参阅 Apache 参考指南中的存储文件跟踪
从 Amazon EMR 版本 7.4.0 开始, FileBasedStoreFile 追踪器实现默认处于启用状态:
{ "Classification": "hbase-site", "Properties": { hbase.store.file-tracker.impl: "org.apache.hadoop.hbase.regionserver.storefiletracker.FileBasedStoreFileTracker" } }
要禁用该 FileBasedStoreFileTracker 实现,请在启动集群时指定以下配置替代:
{ "Classification": "hbase-site", "Properties": { hbase.store.file-tracker.impl: "org.apache.hadoop.hbase.regionserver.storefiletracker.DefaultStoreFileTracker" } }
注意
重新配置 Amazon EMR 集群时,必须更新所有实例组。
运营注意事项
HBase 区域服务器用于 BlockCache 将读取的数据存储在内存中 BucketCache ,并将读取的数据存储在本地磁盘上。此外,区域服务器用于 MemStore 将写入的数据存储在内存中,并使用预写日志将数据写入到 HDFS 中,然后再将数据写入到 Amazon HBase StoreFiles S3 中。集群的读取性能与可从内存中或磁盘缓存中读取记录的频率有关。缓存失误会导致从 Amazon S3 StoreFile 中读取记录,与从 HDFS 读取相比,Amazon S3 的延迟和标准差明显更高。此外,Amazon S3 的最大请求速率低于可从本地缓存中检索内容的速率,因此对于需要进行大量读取操作的工作负载来说,缓存数据可能非常重要。有关 Amazon S3 性能的更多信息,请参阅《Amazon Simple Storage Service 用户指南》中的性能优化。
为了提高性能,建议您在 EC2 实例存储中尽可能多地缓存数据集。由于 BucketCache 使用区域服务器的 EC2 实例存储,因此您可以选择具有足够实例存储的 EC2 实例类型,然后添加 Amazon EBS 存储以适应所需的缓存大小。您还可以使用hbase.bucketcache.size属性增加附加的实例存储和 EBS 卷BucketCache 的大小。默认设置为 8192MB。
对于写入, MemStore 刷新频率以及小规模和主要压缩期间的 StoreFiles 存在次数可以显著增加区域服务器的响应时间。为了获得最佳性能,请考虑增加MemStore 刷新和 HRegion 块乘数的大小,这会增加主要压缩之间的间隔时间,但如果您使用只读副本,也会增加一致性的延迟。在某些情况下,使用较大的文件块大小(但小于 5GB)触发 EMRFS 中的 Amazon S3 分段上载功能也许能够获得更佳性能。Amazon EMR 的数据块大小默认为 128MB。有关更多信息,请参阅HDFS 配置。在通过刷新和压缩来衡量性能时,我们很少看到有客户的数据块大小超过 1GB。此外,当 StoreFiles 需要 HBase 压缩的服务器较少时,压缩服务器和区域服务器的性能会达到最佳状态。
由于需要对大量目录进行重命名,因此从 Amazon S3 中删除表需要花费大量时间。请考虑禁用表而不是删除表。
有一个 HBase 更干净的过程可以清理旧的 WAL 文件并存储文件。对于 Amazon EMR 版本 5.17.0 及更高版本,全局启用清理器,且以下配置属性可用于控制清理器行为。
| 配置属性 | 默认 值 | 说明 |
|---|---|---|
|
|
1 |
分配给清理的线程数已过期 HFiles。 |
|
|
1 |
分配给清理的线程数过期很少 HFiles。 |
|
|
设置为所有可用内核的四分之一。 |
要扫描旧WALs 目录的线程数。 |
|
|
2 |
旧WALs 目录 WALs 下要清理的线程数。 |
对于 Amazon EMR 5.17.0 及更早版本,在运行大量工作负载时,清理器操作会影响查询性能;因此,我们建议您只在非高峰时间启用清理器。清理器有以下 HBase shell 命令:
cleaner_chore_enabled查询是否启用了清理器。cleaner_chore_run手动运行清理器来删除文件。cleaner_chore_switch启用或禁用清理器并返回清理器的先前状态。例如,cleaner_chore_switch true启用清理器。
HBase 在 Amazon S3 上进行性能调整的属性
在 Amazon S3 HBase 上使用时,可以调整以下参数以调整工作负载的性能。
| 配置属性 | 默认 值 | 说明 |
|---|---|---|
|
|
8192 |
在区域服务器 Amazon EC2 实例存储和 EBS 卷上预留的用于 BucketCache 存储的磁盘空间量,以 MB 为单位。此设置适用于所有区域服务器实例。较大的 BucketCache 尺寸通常对应于性能的提高 |
|
|
134217728 |
触发对 Amazon S3 的 memstore 刷新的数据限制(以字节为单位)。 |
|
|
4 |
一个乘数,用于确定阻止更新的 MemStore 上限。如果 MemStore 超出值 |
|
|
10 |
在阻止更新之前 StoreFiles ,商店中可以存在的最大数量。 |
|
|
10737418240 |
区域被拆分之前的大小上限。 |
关闭并恢复集群而不丢失数据
要在不丢失尚未写入 Amazon S3 的数据的情况下关闭 Amazon EMR 集群,您应该将 MemStore 缓存刷新到 Amazon S3 以写入新的存储文件。首先,您需要禁用所有表格。在向集群添加步骤时,可使用以下步骤配置。有关更多信息,请参阅《Amazon EMR 管理指南》中的使用 Amazon CLI 和控制台执行步骤。
Name="Disable all tables",Jar="command-runner.jar",Args=["/bin/bash","/usr/lib/hbase/bin/disable_all_tables.sh"]
或者,您可以直接运行以下 bash 命令。
bash /usr/lib/hbase/bin/disable_all_tables.sh
禁用所有表后,使用 HBase shell 和以下命令刷新hbase:meta表。
flush 'hbase:meta'
然后,您可以运行 Amazon EMR 集群上提供的 shell 脚本来刷新缓存。MemStore 您可以将它作为步骤添加,也可以使用集群中 Amazon CLI直接运行它。该脚本会禁用所有 HBase 表,这会导致每个区域 MemStore的服务器刷新到 Amazon S3。如果此脚本成功完成,数据将保留在 Amazon S3 中,并且可以终止集群。
要使用相同 HBase 数据重启集群,请在 Amazon Web Services 管理控制台 或中使用hbase.rootdir配置属性指定与前一个集群相同的 Amazon S3 位置。