本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
Iceberg 的工作原理
Iceberg 跟踪表中而非目录中的单个数据文件。这样,写入器便可在原位置创建数据文件(文件不会移动或更改)。此外,写入器只能在显式提交时将文件添加到表中。表状态在元数据文件中维护。对表状态的所有更改都会创建一个新的元数据文件,该文件会原子式替换旧的元数据。表元数据文件跟踪表架构、分区配置和其他属性。
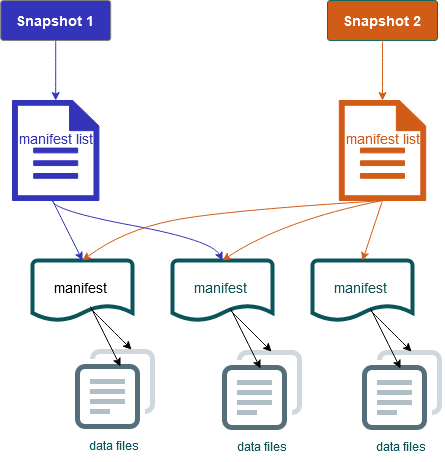
其还包括表内容的快照。每个快照都是表中数据文件在某个时间点的完整集合。快照在元数据文件中列出,但快照中的文件存储在单独的清单文件中。通过在表元数据文件之间的原子转换来实现快照隔离。读取器使用加载表元数据时最新的快照。读取器在刷新并选取新的元数据位置之前不会受到更改的影响。快照中的数据文件存储在一个或多个清单文件中,其中包含表中每个数据文件、分区数据及其指标一行。快照是清单中所有文件的并集。清单文件还可以在快照之间共享,以避免重写不常更改的元数据。
Iceberg 快照图
Iceberg 提供以下功能:
-
支持 Simple Storage Service (Amazon S3) 数据湖中的 ACID 事务处理和时间行程。
-
提交重试次数受益于乐观并发
的性能优势。 -
由于解决了文件级冲突问题,因此具有高并发能力。
-
通过元数据中每列的最小最大统计数据,您可以跳过文件,从而提高选择性查询的性能。
-
您可以通过分区发展将表整理为灵活的分区布局,以便能够更新分区架构。然后,查询和数据量可以在不依赖物理目录的情况下进行更改。
-
支持架构发展
和强制执行。 -
Iceberg 表充当幂等性数据汇和可重放的源。其能够通过一次精确的管道支持流式处理和批处理。幂等性数据汇会跟踪过去成功的写入操作。因此,数据汇可以在失败时再次请求数据,并可在数据已多次发送时丢弃数据。
-
查看历史记录和谱系,包括表发展、操作历史记录和每次提交的统计数据。
-
从现有数据集迁移时,支持数据格式(Parquet、ORC、Avro)和分析引擎(Spark、Trino、PrestoDB、Flink、Hive)选择。