本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
在 Amazon EMR 中配置 Flink
使用 Hive 元存储和 Glue 目录配置 Flink
亚马逊 EMR 版本 6.9.0 及更高版本支持 Hive Metastore 和 Amazon Glue Catalog,并通过 Apache Flink 连接到 Hive。本部分概括介绍了使用 Flink 配置 Amazon Glue 目录和 Hive 元存储所需的步骤。
使用 Hive 元存储
-
创建 EMR 集群,其中包含版本 6.9.0 或更高版本,并至少包含两个应用程序:Hive 和 Flink。
-
使用脚本运行程序将以下脚本作为步骤函数执行:
hive-metastore-setup.shsudo cp /usr/lib/hive/lib/antlr-runtime-3.5.2.jar /usr/lib/flink/lib sudo cp /usr/lib/hive/lib/hive-exec-3.1.3*.jar /lib/flink/lib sudo cp /usr/lib/hive/lib/libfb303-0.9.3.jar /lib/flink/lib sudo cp /usr/lib/flink/opt/flink-connector-hive_2.12-1.15.2.jar /lib/flink/lib sudo chmod 755 /usr/lib/flink/lib/antlr-runtime-3.5.2.jar sudo chmod 755 /usr/lib/flink/lib/hive-exec-3.1.3*.jar sudo chmod 755 /usr/lib/flink/lib/libfb303-0.9.3.jar sudo chmod 755 /usr/lib/flink/lib/flink-connector-hive_2.12-1.15.2.jar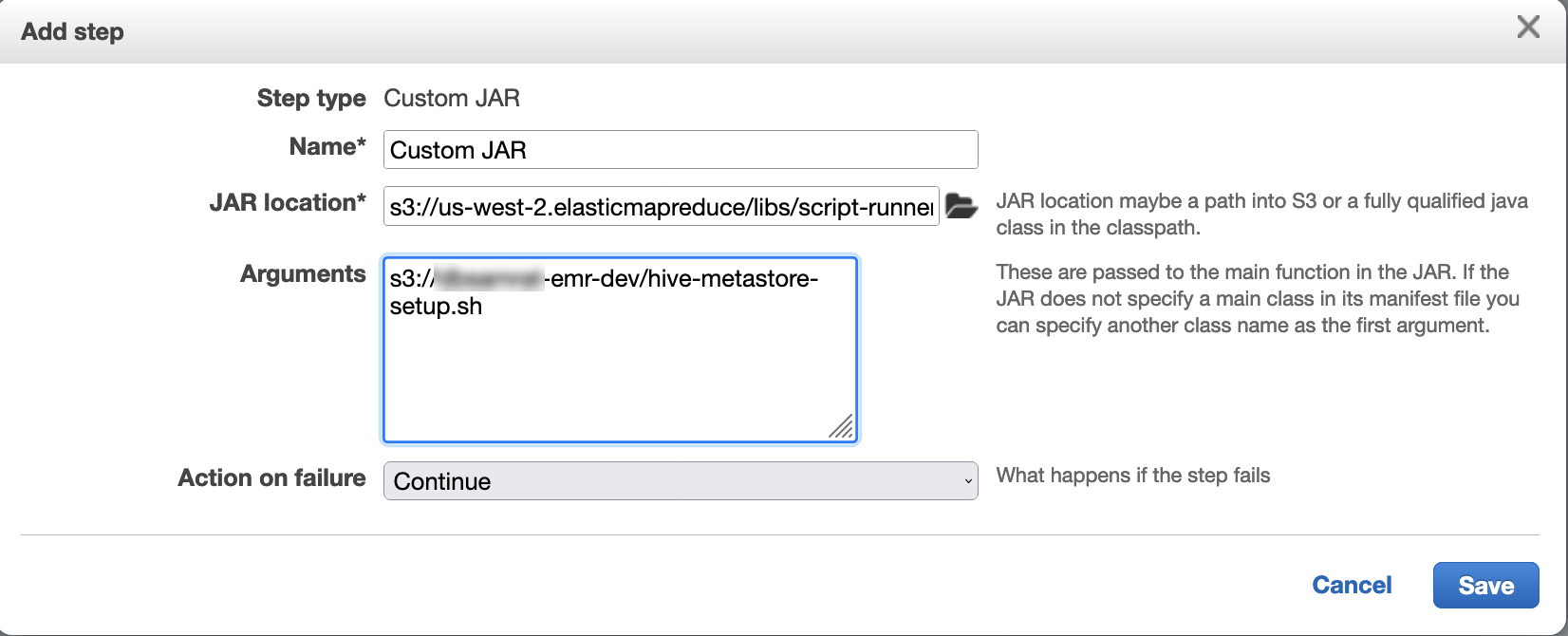
使用 Amazon Glue 数据目录
-
创建 EMR 集群,其中包含版本 6.9.0 或更高版本,并至少包含两个应用程序:Hive 和 Flink。
-
在 Amazon Glue 数据目录设置中选择用于 Hive 表元数据,以在集群中启用数据目录。
-
使用脚本运行程序并将以下脚本作为阶跃函数执行:在 Amazon EMR 集群上运行命令和脚本:
glue-catalog-setup.sh
sudo cp /usr/lib/hive/auxlib/aws-glue-datacatalog-hive3-client.jar /usr/lib/flink/lib sudo cp /usr/lib/hive/lib/antlr-runtime-3.5.2.jar /usr/lib/flink/lib sudo cp /usr/lib/hive/lib/hive-exec-3.1.3*.jar /lib/flink/lib sudo cp /usr/lib/hive/lib/libfb303-0.9.3.jar /lib/flink/lib sudo cp /usr/lib/flink/opt/flink-connector-hive_2.12-1.15.2.jar /lib/flink/lib sudo chmod 755 /usr/lib/flink/lib/aws-glue-datacatalog-hive3-client.jar sudo chmod 755 /usr/lib/flink/lib/antlr-runtime-3.5.2.jar sudo chmod 755 /usr/lib/flink/lib/hive-exec-3.1.3*.jar sudo chmod 755 /usr/lib/flink/lib/libfb303-0.9.3.jar sudo chmod 755 /usr/lib/flink/lib/flink-connector-hive_2.12-1.15.2.jar
使用配置文件配置 Flink
您可以使用 Amazon EMR 配置 API 通过配置文件配置 Flink。目前,可在 API 中配置的文件包括:
-
flink-conf.yaml -
log4j.properties -
flink-log4j-session -
log4j-cli.properties
Flink 的主配置文件的名称为 flink-conf.yaml。
要配置用于 Flink 的任务槽数量,请从 Amazon CLI
-
创建文件
configurations.json并输入以下内容:[ { "Classification": "flink-conf", "Properties": { "taskmanager.numberOfTaskSlots":"2" } } ] -
接下来,使用以下配置创建集群:
aws emr create-cluster --release-labelemr-7.13.0\ --applications Name=Flink \ --configurations file://./configurations.json \ --regionus-east-1\ --log-uri s3://myLogUri\ --instance-type m5.xlarge \ --instance-count2\ --service-role EMR_DefaultRole_V2 \ --ec2-attributes KeyName=YourKeyName,InstanceProfile=EMR_EC2_DefaultRole
注意
您也可以使用 Flink API 更改某些配置。有关更多信息,请参阅 Flink 文档中的概念
对于 Amazon EMR 5.21.0 及更高版本,您可以覆盖集群配置,并为运行的集群中的每个实例组指定额外的配置分类。您可以使用 Amazon EMR 控制台、 Amazon Command Line Interface (Amazon CLI) 或软件开发工具包来完成此操作。 Amazon 有关更多信息,请参阅为运行的集群中的实例组提供配置。
并行选项
作为应用程序所有者,您最了解应将哪些资源分配给 Flink 中的任务。对于本文档中的示例,请使用与您用于应用程序的任务实例相同的任务数量。通常,我们建议对初始并行级别执行此操作,但您也可以使用任务槽来增加并行粒度,它一般不应超过每实例虚拟内核
在包括多个主节点的 EMR 集群中配置 Flink
在具有多个主节点的 Amazon EMR 集群的主节点故障转移过程中,Flink 的 of 仍然可用。 JobManager 从 Amazon EMR 5.28.0 开始,还会自动 JobManager 启用高可用性。无需手动配置。
在 Amazon EMR 5.27.0 或更早版本中, JobManager 这是单点故障。当 JobManager 失败时,它会丢失所有作业状态,并且不会恢复正在运行的作业。您可以通过配置应用程序尝试次数、检查点并启用 Flink 的状态存储来实现 JobManager ZooKeeper 高可用性,如以下示例所示:
[ { "Classification": "yarn-site", "Properties": { "yarn.resourcemanager.am.max-attempts": "10" } }, { "Classification": "flink-conf", "Properties": { "yarn.application-attempts": "10", "high-availability": "zookeeper", "high-availability.zookeeper.quorum": "%{hiera('hadoop::zk')}", "high-availability.storageDir": "hdfs:///user/flink/recovery", "high-availability.zookeeper.path.root": "/flink" } } ]
您必须同时为 YARN 和 Flink 配置最大的应用程序主尝试次数。有关更多信息,请参阅 YARN 集群高可用性的配置
配置内存进程大小
对于使用 Flink 1.11.x 的 Amazon EMR 版本,您必须在中同时配置 () 和 JobManager (jobmanager.memory.process.size) 的内存进程总大小。 TaskManager taskmanager.memory.process.size flink-conf.yaml您可以通过使用配置 API 来配置集群或通过 SSH 手动取消这些字段来设置这些值。Flink 提供以下默认值。
-
jobmanager.memory.process.size:1600m -
taskmanager.memory.process.size:1728m
要排除 JVM 元空间和开销,请使用 Flink 总内存大小 (taskmanager.memory.flink.size) 而非 taskmanager.memory.process.size。taskmanager.memory.process.size 的默认值为 1280m。不建议同时设置 taskmanager.memory.process.size 和 taskmanager.memory.flink.size。
所有使用 Flink 1.12.0 及更高版本的 Amazon EMR 版本,都将 Flink 的开源设置中列出的默认值作为 Amazon EMR 上的默认值,因此您无需自行配置。
配置日志输出文件大小
Flink 应用程序容器创建并写入三种类型的日志文件:.out 文件、.log 文件和 .err 文件。仅限将 .err 文件压缩并从文件系统中删除,而将 .log 和 .out 日志文件保留在文件系统中。为确保这些输出文件保持可管理以及集群保持稳定,您可以在 log4j.properties 设置文件的上限数量并限制其大小。
Amazon EMR 版本 5.30.0 及更高版本
从 Amazon EMR 5.30.0 开始,Flink 使用带有配置分类名称 flink-log4j. 的 log4j2 日志记录框架。以下示例配置演示 log4j2 格式。
[ { "Classification": "flink-log4j", "Properties": { "appender.main.name": "MainAppender", "appender.main.type": "RollingFile", "appender.main.append" : "false", "appender.main.fileName" : "${sys:log.file}", "appender.main.filePattern" : "${sys:log.file}.%i", "appender.main.layout.type" : "PatternLayout", "appender.main.layout.pattern" : "%d{yyyy-MM-dd HH:mm:ss,SSS} %-5p %-60c %x - %m%n", "appender.main.policies.type" : "Policies", "appender.main.policies.size.type" : "SizeBasedTriggeringPolicy", "appender.main.policies.size.size" : "100MB", "appender.main.strategy.type" : "DefaultRolloverStrategy", "appender.main.strategy.max" : "10" }, } ]
Amazon EMR 版本 5.29.0 及较早版本
对于 Amazon EMR 5.29.0 及更早版本,Flink 使用 log4j 日志记录框架。下面的示例配置演示了 log4j 格式。
[ { "Classification": "flink-log4j", "Properties": { "log4j.appender.file": "org.apache.log4j.RollingFileAppender", "log4j.appender.file.append":"true", # keep up to 4 files and each file size is limited to 100MB "log4j.appender.file.MaxFileSize":"100MB", "log4j.appender.file.MaxBackupIndex":4, "log4j.appender.file.layout":"org.apache.log4j.PatternLayout", "log4j.appender.file.layout.ConversionPattern":"%d{yyyy-MM-dd HH:mm:ss,SSS} %-5p %-60c %x - %m%n" }, } ]
将 Flink 配置为使用 Java 11 运行
Amazon EMR 6.12.0 及更高版本为 Flink 提供 Java 11 运行时系统支持。以下各节介绍如何配置集群以为 Flink 提供 Java 11 运行时系统支持。
在创建集群时配置 Flink for Java 11
使用以下步骤创建包含 Flink 和 Java 11 运行时系统的 EMR 集群。添加 Java 11 运行时系统支持所在的配置文件是 flink-conf.yaml。
在正在运行的集群上配置 Flink for Java 11
使用以下步骤更新包含 Flink 和 Java 11 运行时系统的 EMR 集群。添加 Java 11 运行时系统支持所在的配置文件是 flink-conf.yaml。
在正在运行的集群上确认 Flink 的 Java 运行时系统
要确定正在运行的集群的 Java 运行时系统,请使用 SSH 登录主节点,如 Connect to the primary node with SSH 中所述。然后运行以下命令:
ps -ef | grep flink
包含 -ef 选项的 ps 命令列出了系统上所有正在运行的进程。您可以使用 grep 过滤该输出,以查找提及 flink 字符串的内容。查看 Java 运行时环境(JRE)值的输出 jre-XX。在以下输出中,jre-11 表示在运行时系统为 Flink 选择了 Java 11。
flink 19130 1 0 09:17 ? 00:00:15 /usr/lib/jvm/jre-11/bin/java -Djava.io.tmpdir=/mnt/tmp -Dlog.file=/usr/lib/flink/log/flink-flink-historyserver-0-ip-172-31-32-127.log -Dlog4j.configuration=file:/usr/lib/flink/conf/log4j.properties -Dlog4j.configurationFile=file:/usr/lib/flink/conf/log4j.properties -Dlogback.configurationFile=file:/usr/lib/flink/conf/logback.xml -classpath /usr/lib/flink/lib/flink-cep-1.17.0.jar:/usr/lib/flink/lib/flink-connector-files-1.17.0.jar:/usr/lib/flink/lib/flink-csv-1.17.0.jar:/usr/lib/flink/lib/flink-json-1.17.0.jar:/usr/lib/flink/lib/flink-scala_2.12-1.17.0.jar:/usr/lib/flink/lib/flink-table-api-java-uber-1.17.0.jar:/usr/lib/flink/lib/flink-table-api-scala-bridge_2.12-1.17.0.
或者,使用 SSH 登录主节点,然后使用命令 flink-yarn-session -d 启动 Flink YARN 会话。输出显示了 Flink 的 Java 虚拟机(JVM),如以下 java-11-amazon-corretto 示例所示:
2023-05-29 10:38:14,129 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: containerized.master.env.JAVA_HOME, /usr/lib/jvm/java-11-amazon-corretto.x86_64