本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
在 Amazon EMR 中通过 Zeppelin 使用 Flink 作业
简介
Amazon EMR 发布了 6.10.0 及更高版本,支持与 Apache Flink 的 Apache Zeppelin 集成。您可以通过 Zeppelin Notebooks 以交互方式提交 Flink 作业。使用 Flink 解释器,您可以执行 Flink 查询、定义 Flink 流媒体和批处理作业,以及在 Zeppelin Notebooks 可视化输出。Flink 解释器基于 Flink REST API 构建。这使您可以从 Zeppelin 环境中访问和操作 Flink 作业,以执行实时数据处理和分析。
Flink 解释器中有四个子解释器。它们的用途不同,但都在 JVM 中,与 Flink 共享相同的预配置入口点(ExecutionEnviroment、StreamExecutionEnvironment、BatchTableEnvironment、StreamTableEnvironment)。解释器如下:
-
%flink:创建ExecutionEnvironment、StreamExecutionEnvironment、BatchTableEnvironment、StreamTableEnvironment并提供 Scala 环境 -
%flink.pyflink:提供一个 Python 环境 -
%flink.ssql:提供流式 SQL 环境 -
%flink.bsql:提供批处理 SQL 环境
先决条件
-
使用 Amazon EMR 6.10.0 及更高版本创建的集群支持 Zeppelin 与 Flink 集成。
-
要根据这些步骤的要求查看 EMR 集群上托管的 Web 界面,必须配置 SSH 隧道以允许入站访问。有关更多信息,请参阅 Configure proxy settings to view websites hosted on the primary node。
在 EMR 集群上配置 Zeppelin-Flink
使用以下步骤将 Apache Zeppelin 上的 Apache Flink 配置为在 EMR 集群上运行:
-
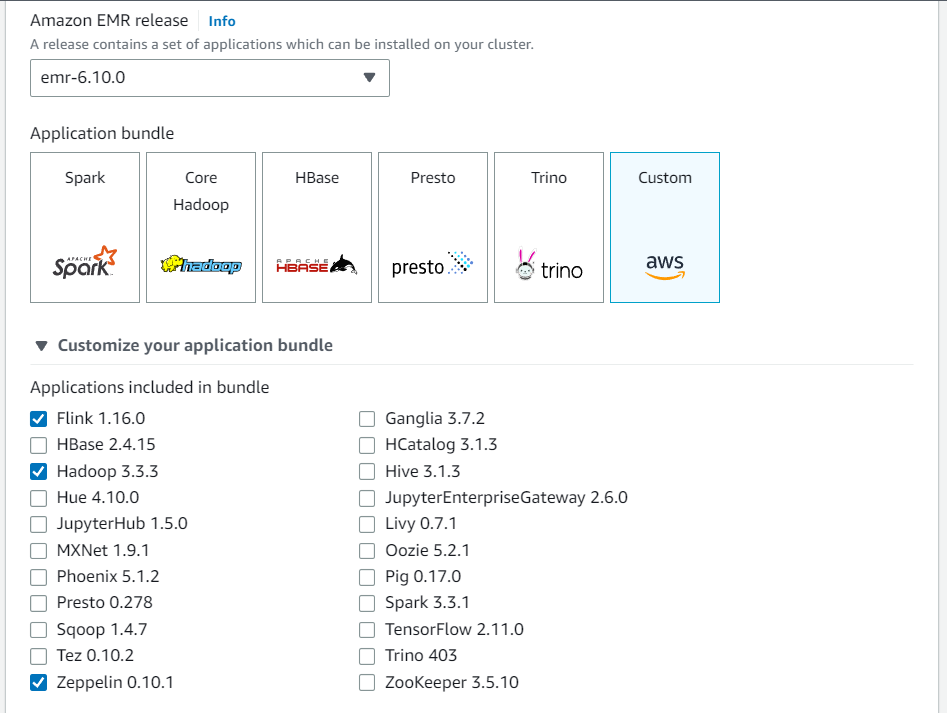
从 Amazon EMR 控制台创建新集群。为 Amazon EMR 版本选择 emr-6.10.0 或更高版本。然后,选择使用“自定义”选项自定义您的应用程序捆绑包。在您的捆绑包中至少包含 Flink、Hadoop 和 Zeppelin。
-
使用您首选的设置创建集群的其余部分。
-
一旦集群开始运行,在控制台中选择集群以查看其详细信息并打开“应用程序”选项卡。从“应用程序”用户界面部分选择“Zeppelin”,以打开 Zeppelin 网页界面。请确保您已设置了对 Zeppelin Web 界面的访问,包含连接到主节点的 SSH 隧道和代理连接,如 先决条件 中所述。
-
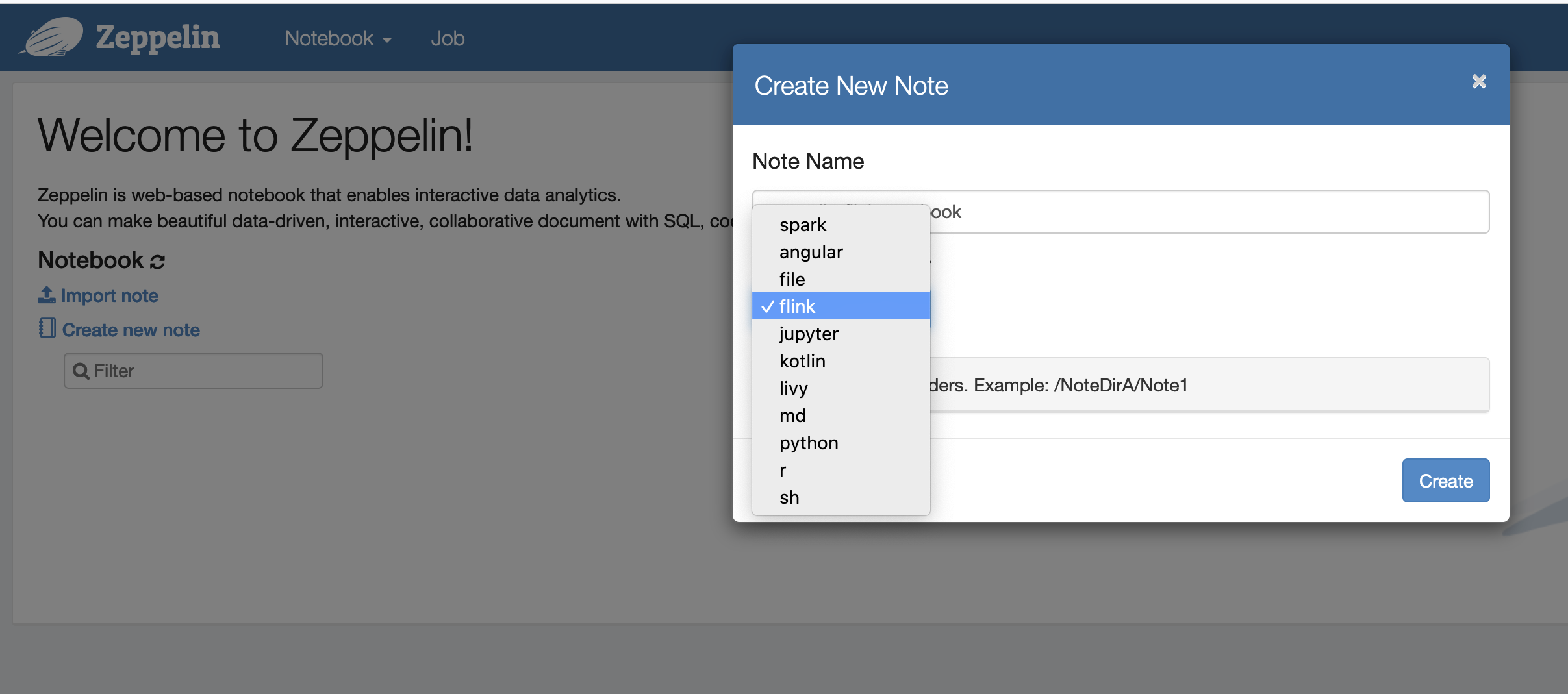
现在,您可以使用 Flink 作为默认解释器在 Zeppelin Notebook 中创建新笔记。
-
请参阅以下代码示例,这些示例演示了如何从 Zeppelin Notebook 运行 Flink 作业。
在 EMR 集群上使用 Zeppelin-Flink 运行 Flink 作业
-
示例 1,Flink Scala
a) Batch Ex WordCount ample (SCALA)
%flink val data = benv.fromElements("hello world", "hello flink", "hello hadoop") data.flatMap(line => line.split("\\s")) .map(w => (w, 1)) .groupBy(0) .sum(1) .print()b) 直播 WordCount 示例 (SCALA)
%flink val data = senv.fromElements("hello world", "hello flink", "hello hadoop") data.flatMap(line => line.split("\\s")) .map(w => (w, 1)) .keyBy(0) .sum(1) .print senv.execute()
-
示例 2,Flink 流式传输 SQL
%flink.ssql SET 'sql-client.execution.result-mode' = 'tableau'; SET 'table.dml-sync' = 'true'; SET 'execution.runtime-mode' = 'streaming'; create table dummy_table ( id int, data string ) with ( 'connector' = 'filesystem', 'path' = 's3://s3-bucket/dummy_table', 'format' = 'csv' ); INSERT INTO dummy_table SELECT * FROM (VALUES (1, 'Hello World'), (2, 'Hi'), (2, 'Hi'), (3, 'Hello'), (3, 'World'), (4, 'ADD'), (5, 'LINE')); SELECT * FROM dummy_table;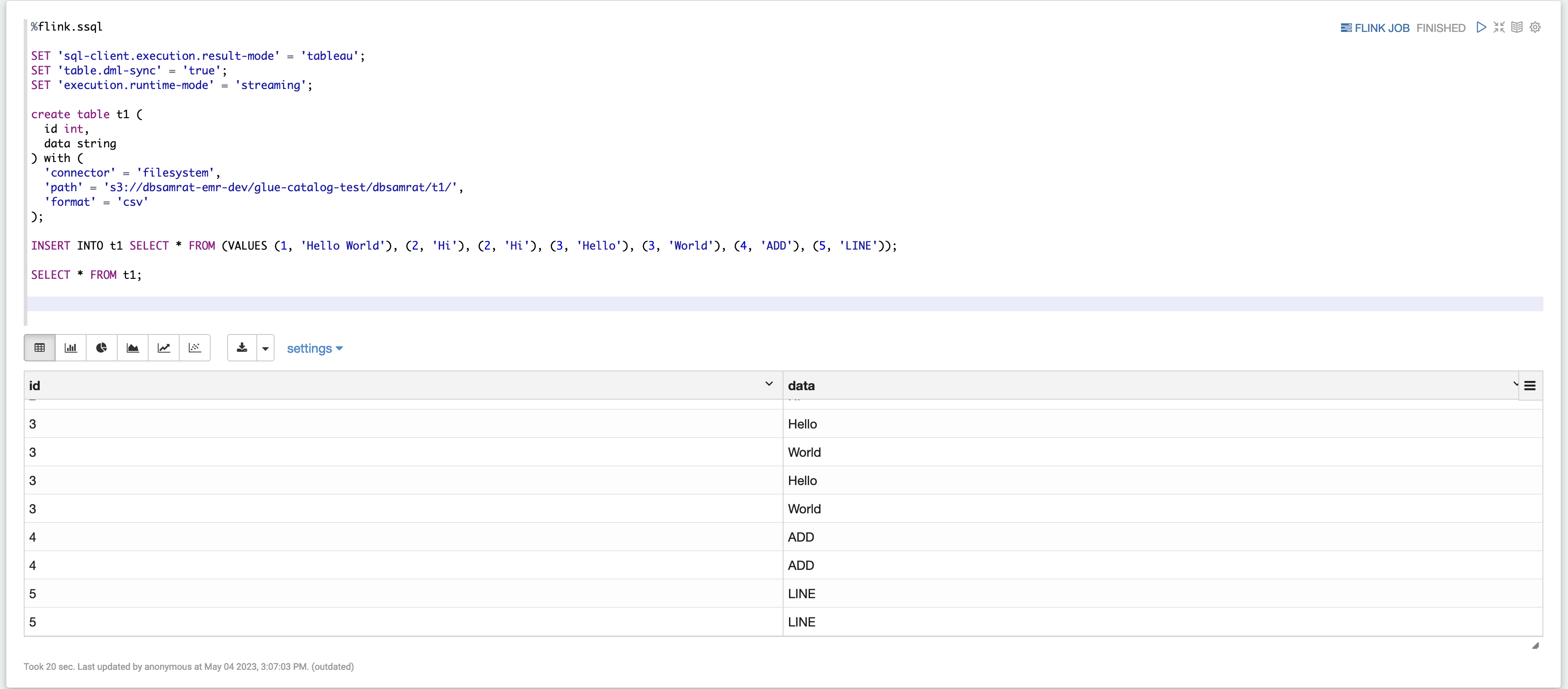
-
示例 3,Pyflink。请注意,您必须将名为
word.txt的示例文本文件上传到 S3 存储桶。%flink.pyflink import argparse import logging import sys from pyflink.common import Row from pyflink.table import (EnvironmentSettings, TableEnvironment, TableDescriptor, Schema, DataTypes, FormatDescriptor) from pyflink.table.expressions import lit, col from pyflink.table.udf import udtf def word_count(input_path, output_path): t_env = TableEnvironment.create(EnvironmentSettings.in_streaming_mode()) # write all the data to one file t_env.get_config().set("parallelism.default", "1") # define the source if input_path is not None: t_env.create_temporary_table( 'source', TableDescriptor.for_connector('filesystem') .schema(Schema.new_builder() .column('word', DataTypes.STRING()) .build()) .option('path', input_path) .format('csv') .build()) tab = t_env.from_path('source') else: print("Executing word_count example with default input data set.") print("Use --input to specify file input.") tab = t_env.from_elements(map(lambda i: (i,), word_count_data), DataTypes.ROW([DataTypes.FIELD('line', DataTypes.STRING())])) # define the sink if output_path is not None: t_env.create_temporary_table( 'sink', TableDescriptor.for_connector('filesystem') .schema(Schema.new_builder() .column('word', DataTypes.STRING()) .column('count', DataTypes.BIGINT()) .build()) .option('path', output_path) .format(FormatDescriptor.for_format('canal-json') .build()) .build()) else: print("Printing result to stdout. Use --output to specify output path.") t_env.create_temporary_table( 'sink', TableDescriptor.for_connector('print') .schema(Schema.new_builder() .column('word', DataTypes.STRING()) .column('count', DataTypes.BIGINT()) .build()) .build()) @udtf(result_types=[DataTypes.STRING()]) def split(line: Row): for s in line[0].split(): yield Row(s) # compute word count tab.flat_map(split).alias('word') \ .group_by(col('word')) \ .select(col('word'), lit(1).count) \ .execute_insert('sink') \ .wait() logging.basicConfig(stream=sys.stdout, level=logging.INFO, format="%(message)s") word_count("s3://s3_bucket/word.txt", "s3://s3_bucket/demo_output.txt")
-
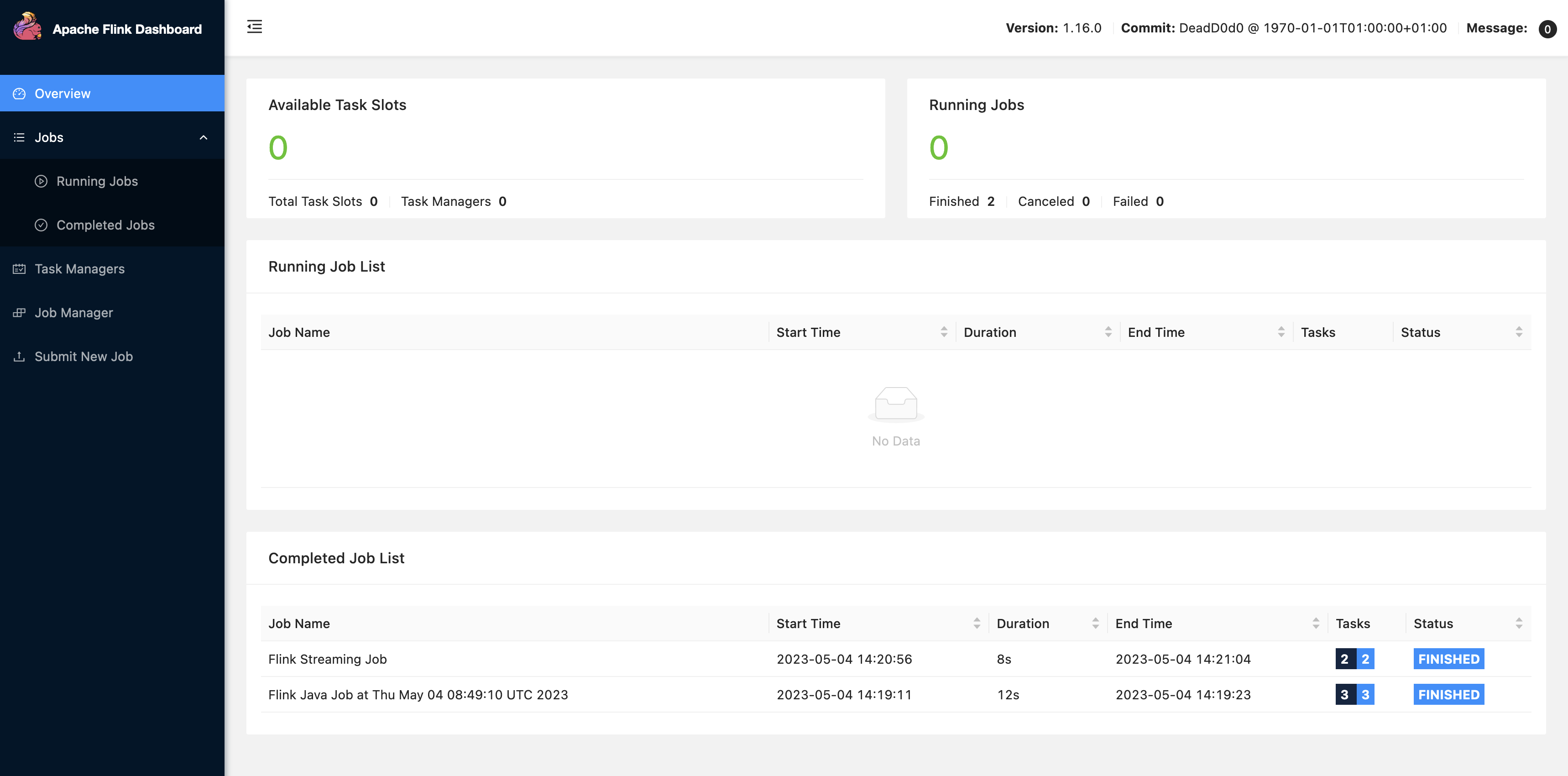
在 Zeppelin 用户界面中选择 FLINK 作业即可访问和查看 Flink Web 用户界面。
-
在浏览器的另一个选项卡中选择 FLINK 作业,会路由到 Flink Web 控制台。