Adding data to a source RDS database and querying it
To finish creating a zero-ETL integration that replicates data from Amazon RDS into Amazon Redshift, you must create a database in the target destination.
For connections with Amazon Redshift, connect to your Amazon Redshift cluster or workgroup and create a database with a reference to your integration identifier. Then, you can add data to your source RDS database and see it replicated in Amazon Redshift or Amazon SageMaker.
Topics
Creating a target database
Before you can start replicating data into Amazon Redshift, after you create an integration, you must create a database in your target data warehouse. This database must include a reference to the integration identifier. You can use the Amazon Redshift console or the Query editor v2 to create the database.
For instructions to create a destination database, see Create a destination database in Amazon Redshift.
Adding data to the source database
After you configure your integration, you can populate the source RDS database with data that you want to replicate into your data warehouse.
Note
There are differences between data types in Amazon RDS and the target analytics warehouse. For a table of data type mappings, see Data type differences between RDS and Amazon Redshift databases.
First, connect to the source database using the MySQL client of your choice. For instructions, see Connecting to your MySQL DB instance.
Then, create a table and insert a row of sample data.
Important
Make sure that the table has a primary key. Otherwise, it can't be replicated to the target data warehouse.
RDS for MySQL
The following example uses the MySQL Workbench utility
CREATE DATABASEmy_db; USEmy_db; CREATE TABLEbooks_table(ID int NOT NULL, Title VARCHAR(50) NOT NULL, Author VARCHAR(50) NOT NULL, Copyright INT NOT NULL, Genre VARCHAR(50) NOT NULL, PRIMARY KEY (ID)); INSERT INTObooks_tableVALUES (1, 'The Shining', 'Stephen King', 1977, 'Supernatural fiction');
RDS for PostgreSQL
The following example uses the psql
PostgreSQL interactive terminal. When connecting to the database, include the database
name that you want to replicate.
psql -hmydatabase.123456789012.us-east-2.rds.amazonaws.com -p 5432 -Uusername-dnamed_db; named_db=> CREATE TABLEbooks_table(ID int NOT NULL, Title VARCHAR(50) NOT NULL, Author VARCHAR(50) NOT NULL, Copyright INT NOT NULL, Genre VARCHAR(50) NOT NULL, PRIMARY KEY (ID)); named_db=> INSERT INTObooks_tableVALUES (1, 'The Shining', 'Stephen King', 1977, 'Supernatural fiction');
RDS for Oracle
The following example uses SQL*Plus to connect to your RDS for Oracle database.
sqlplus 'user_name@(DESCRIPTION=(ADDRESS=(PROTOCOL=TCP)(HOST=dns_name)(PORT=port))(CONNECT_DATA=(SID=database_name)))' SQL> CREATE TABLEbooks_table(ID int NOT NULL, Title VARCHAR(50) NOT NULL, Author VARCHAR(50) NOT NULL, Copyright INT NOT NULL, Genre VARCHAR(50) NOT NULL, PRIMARY KEY (ID)); SQL> INSERT INTObooks_tableVALUES (1, 'The Shining', 'Stephen King', 1977, 'Supernatural fiction');
Querying your Amazon RDS data in Amazon Redshift
After you add data to the RDS database, it's replicated into the destination database and is ready to be queried.
To query the replicated data
-
Navigate to the Amazon Redshift console and choose Query editor v2 from the left navigation pane.
-
Connect to your cluster or workgroup and choose your destination database (which you created from the integration) from the dropdown menu (destination_database in this example). For instructions to create a destination database, see Create a destination database in Amazon Redshift.
-
Use a SELECT statement to query your data. In this example, you can run the following command to select all data from the table that you created in the source RDS database:
SELECT * frommy_db."books_table";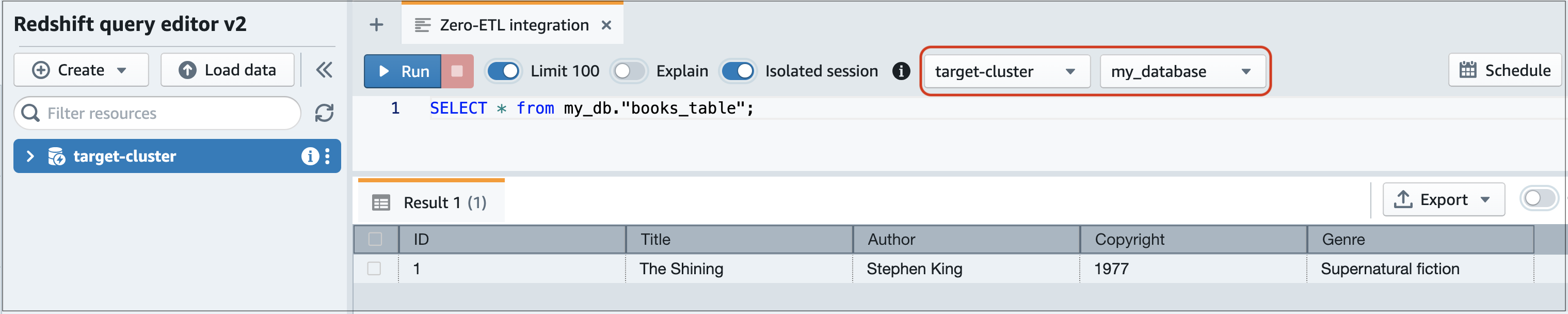
-
my_db -
books_table
-
You can also query the data using the a command line client. For example:
destination_database=# select * frommy_db."books_table"; ID | Title | Author | Copyright | Genre | txn_seq | txn_id ----+–------------+---------------+-------------+------------------------+----------+--------+ 1 | The Shining | Stephen King | 1977 | Supernatural fiction | 2 | 12192
Note
For case-sensitivity, use double quotes (" ") for schema, table, and column names. For more information, see enable_case_sensitive_identifier.
Data type differences between RDS and Amazon Redshift databases
The following tables show the mappings of RDS for MySQL, RDS for PostgreSQL, and RDS for Oracle data types to corresponding destination data types. Amazon RDS currently supports only these data types for zero-ETL integrations.
If a table in your source database includes an unsupported data type, the table goes
out of sync and isn't consumable by the destination target. Streaming from the source to the
target continues, but the table with the unsupported data type isn't available. To fix
the table and make it available in the target destination, you must manually revert the breaking change
and then refresh the integration by running ALTER DATABASE...INTEGRATION
REFRESH.
Note
You can't refresh zero-ETL integrations with an Amazon SageMaker lakehouse. Instead, delete and try to create the integration again.
RDS for MySQL
| RDS for MySQL data type | Target data type | Description | Limitations |
|---|---|---|---|
| INT | INTEGER | Signed four-byte integer | None |
| SMALLINT | SMALLINT | Signed two-byte integer | None |
| TINYINT | SMALLINT | Signed two-byte integer | None |
| MEDIUMINT | INTEGER | Signed four-byte integer | None |
| BIGINT | BIGINT | Signed eight-byte integer | None |
| INT UNSIGNED | BIGINT | Signed eight-byte integer | None |
| TINYINT UNSIGNED | SMALLINT | Signed two-byte integer | None |
| MEDIUMINT UNSIGNED | INTEGER | Signed four-byte integer | None |
| BIGINT UNSIGNED | DECIMAL(20,0) | Exact numeric of selectable precision | None |
| DECIMAL(p,s) = NUMERIC(p,s) | DECIMAL(p,s) | Exact numeric of selectable precision |
Precision greater than 38 and scale greater than 37 not supported |
| DECIMAL(p,s) UNSIGNED = NUMERIC(p,s) UNSIGNED | DECIMAL(p,s) | Exact numeric of selectable precision |
Precision greater than 38 and scale greater than 37 not supported |
| FLOAT4/REAL | REAL | Single precision floating-point number | None |
| FLOAT4/REAL UNSIGNED | REAL | Single precision floating-point number | None |
| DOUBLE/REAL/FLOAT8 | DOUBLE PRECISION | Double precision floating-point number | None |
| DOUBLE/REAL/FLOAT8 UNSIGNED | DOUBLE PRECISION | Double precision floating-point number | None |
| BIT(n) | VARBYTE(8) | Variable-length binary value | None |
| BINARY(n) | VARBYTE(n) | Variable-length binary value | None |
| VARBINARY(n) | VARBYTE(n) | Variable-length binary value | None |
| CHAR(n) | VARCHAR(n) | Variable-length string value | None |
| VARCHAR(n) | VARCHAR(n) | Variable-length string value | None |
| TEXT | VARCHAR(65535) | Variable-length string value up to 65,535 characters | None |
| TINYTEXT | VARCHAR(255) | Variable-length string value up to 255 characters | None |
| MEDIUMTEXT | VARCHAR(65535) | Variable-length string value up to 65,535 characters | None |
| LONGTEXT | VARCHAR(65535) | Variable-length string value up to 65,535 characters | None |
| ENUM | VARCHAR(1020) | Variable-length string value up to 1,020 characters | None |
| SET | VARCHAR(1020) | Variable-length string value up to 1,020 characters | None |
| DATE | DATE | Calendar date (year, month, day) | None |
| DATETIME | TIMESTAMP | Date and time (without time zone) | None |
| TIMESTAMP(p) | TIMESTAMP | Date and time (without time zone) | None |
| TIME | VARCHAR(18) | Variable-length string value up to 18 characters | None |
| YEAR | VARCHAR(4) | Variable-length string value up to 4 characters | None |
| JSON | SUPER | Semistructured data or documents as values | None |
RDS for PostgreSQL
Zero-ETL integrations for RDS for PostgreSQL don't support custom data types or data types created by extensions.
| RDS for PostgreSQL data type | Amazon Redshift data type | Description | Limitations |
|---|---|---|---|
| array | SUPER | Semistructured data or documents as values | None |
| bigint | BIGINT | Signed eight-byte integer | None |
| bigserial | BIGINT | Signed eight-byte integer | None |
| bit varying(n) | VARBYTE(n) | Variable-length binary value up to 16,777,216 bytes | None |
| bit(n) | VARBYTE(n) | Variable-length binary value up to 16,777,216 bytes | None |
| bit, bit varying | VARBYTE(16777216) | Variable-length binary value up to 16,777,216 bytes | None |
| boolean | BOOLEAN | Logical boolean (true/false) | None |
| bytea | VARBYTE(16777216) | Variable-length binary value up to 16,777,216 bytes | None |
| char(n) | CHAR(n) | Fixed-length character string value up to 65,535 bytes | None |
| char varying(n) | VARCHAR(65535) | Variable-length character string value up to 65,535 characters | None |
| cid | BIGINT |
Signed eight-byte integer |
None |
| cidr |
VARCHAR(19) |
Variable-length string value up to 19 characters |
None |
| date | DATE | Calendar date (year, month, day) |
Values greater than 294,276 A.D. not supported |
| double precision | DOUBLE PRECISION | Double precision floating-point numbers | Subnormal values not fully supported |
|
gtsvector |
VARCHAR(65535) |
Variable-length string value up to 65,535 characters |
None |
| inet |
VARCHAR(19) |
Variable-length string value up to 19 characters |
None |
| integer | INTEGER | Signed four-byte integer | None |
|
int2vector |
SUPER | Semistructured data or documents as values. | None |
| interval | INTERVAL | Duration of time | Only INTERVAL types that specify either a year to month or a day to second qualifier are supported. |
| json | SUPER | Semistructured data or documents as values | None |
| jsonb | SUPER | Semistructured data or documents as values | None |
| jsonpath | VARCHAR(65535) | Variable-length string value up to 65,535 characters | None |
|
macaddr |
VARCHAR(17) | Variable-length string value up to 17 characters | None |
|
macaddr8 |
VARCHAR(23) | Variable-length string value up to 23 characters | None |
| money | DECIMAL(20,3) | Currency amount | None |
| name | VARCHAR(64) | Variable-length string value up to 64 characters | None |
| numeric(p,s) | DECIMAL(p,s) | User-defined fixed precision value |
|
| oid | BIGINT | Signed eight-byte integer | None |
| oidvector | SUPER | Semistructured data or documents as values. | None |
| pg_brin_bloom_summary | VARCHAR(65535) | Variable-length string value up to 65,535 characters | None |
| pg_dependencies | VARCHAR(65535) | Variable-length string value up to 65,535 characters | None |
| pg_lsn | VARCHAR(17) | Variable-length string value up to 17 characters | None |
| pg_mcv_list | VARCHAR(65535) | Variable-length string value up to 65,535 characters | None |
| pg_ndistinct | VARCHAR(65535) | Variable-length string value up to 65,535 characters | None |
| pg_node_tree | VARCHAR(65535) | Variable-length string value up to 65,535 characters | None |
| pg_snapshot | VARCHAR(65535) | Variable-length string value up to 65,535 characters | None |
| real | REAL | Single precision floating-point number | Subnormal values not fully supported |
| refcursor | VARCHAR(65535) | Variable-length string value up to 65,535 characters | None |
| smallint | SMALLINT | Signed two-byte integer | None |
| smallserial | SMALLINT | Signed two-byte integer | None |
| serial | INTEGER | Signed four-byte integer | None |
| text | VARCHAR(65535) | Variable-length string value up to 65,535 characters | None |
| tid | VARCHAR(23) | Variable-length string value up to 23 characters | None |
| time [(p)] without time zone | VARCHAR(19) | Variable-length string value up to 19 characters | Infinity and -Infinity values not
supported |
| time [(p)] with time zone | VARCHAR(22) | Variable-length string value up to 22 characters | Infinity and -Infinity values not
supported |
| timestamp [(p)] without time zone | TIMESTAMP | Date and time (without time zone) |
|
| timestamp [(p)] with time zone | TIMESTAMPTZ | Date and time (with time zone) |
|
| tsquery | VARCHAR(65535) | Variable-length string value up to 65,535 characters | None |
| tsvector | VARCHAR(65535) | Variable-length string value up to 65,535 characters | None |
| txid_snapshot | VARCHAR(65535) | Variable-length string value up to 65,535 characters | None |
| uuid | VARCHAR(36) | Variable-length 36 character string | None |
| xid | BIGINT | Signed eight-byte integer | None |
| xid8 | DECIMAL(20, 0) | Fixed precision decimal | None |
| xml | VARCHAR(65535) | Variable-length string value up to 65,535 characters | None |
RDS for Oracle
Unsupported data types
The following RDS for Oracle data types are not supported by Amazon Redshift:
-
ANYDATA -
BFILE -
REF -
ROWID -
UROWID -
VARRAY -
SDO_GEOMETRY -
User-defined data types
Data type differences
The following table shows the data type differences that affect a zero-ETL integration when RDS for Oracle is the source and Amazon Redshift is the target.
| RDS for Oracle data type | Amazon Redshift data type |
|---|---|
|
BINARY_FLOAT |
FLOAT4 |
|
BINARY_DOUBLE |
FLOAT8 |
|
BINARY |
VARCHAR (Length) |
|
FLOAT (P) |
If precision is =< 24, then FLOAT4. If precision is > 24, then FLOAT8. |
|
NUMBER (P,S) |
If scale is => 0 and =< 37, then NUMERIC (p,s). If scale is => 38 and =< 127, then VARCHAR (Length). If scale is 0:
If scale is less than 0, then INT8. |
|
DATE |
If the scale is => 0 and =< 6, depending on the Redshift target column type, then one of the following:
If the scale is => 7 and =< 9, then VARCHAR (37). |
|
INTERVAL_YEAR TO MONTH |
If the length is 1–65,535, then VARCHAR (length in bytes). If the length is 65,536–2,147,483,647, then VARCHAR (65535). |
|
INTERVAL_DAY TO SECOND |
If the length is 1–65,535, then VARCHAR (length in bytes). If the length is 65,536–2,147,483,647, then VARCHAR (65535). |
|
TIMESTAMP |
If the scale is => 0 and =< 6, depending on the Redshift target column type, then one of the following:
If the scale is => 7 and =< 9, then VARCHAR (37). |
|
TIMESTAMP WITH TIME ZONE |
If the length is 1–65,535, then VARCHAR (length in bytes). If the length is 65,536–2,147,483,647, then VARCHAR (65535). |
|
TIMESTAMP WITH LOCAL TIME ZONE |
If the length is 1–65,535, then VARCHAR (length in bytes). If the length is 65,536–2,147,483,647, then VARCHAR (65535). |
|
CHAR |
If the length is 1–65,535, then VARCHAR (length in bytes). If the length is 65,536–2,147,483,647, then VARCHAR (65535). |
|
VARCHAR2 |
When the length is greater than 4,000 bytes, then VARCHAR (maximum LOB size). The maximum LOB size cannot exceed 63 KB. Amazon Redshift does not support VARCHARs larger than 64 KB. When the length is 4,000 bytes or less, then VARCHAR (length in bytes). |
|
NCHAR |
If the length is 1–65,535, then NVARCHAR (length in bytes). If the length is 65,536–2,147,483,647, then NVARCHAR (65535). |
|
NVARCHAR2 |
When the length is greater than 4,000 bytes, then NVARCHAR (maximum LOB size). The maximum LOB size cannot exceed 63 KB. Amazon Redshift does not support VARCHARs larger than 64 KB. When the length is 4,000 bytes or less, then NVARCHAR (length in bytes). |
|
RAW |
VARCHAR (Length) |
|
REAL |
FLOAT8 |
|
BLOB |
VARCHAR (maximum LOB size *2) The maximum LOB size cannot exceed 31 KB. Amazon Redshift does not support VARCHARs larger than 64 KB. |
|
CLOB |
VARCHAR (maximum LOB size) The maximum LOB size cannot exceed 63 KB. Amazon Redshift does not support VARCHARs larger than 64 KB. |
|
NCLOB |
NVARCHAR (maximum LOB size) The maximum LOB size cannot exceed 63 KB. Amazon Redshift does not support VARCHARs larger than 64 KB. |
|
LONG |
VARCHAR (maximum LOB size) The maximum LOB size cannot exceed 63 KB. Amazon Redshift does not support VARCHARs larger than 64 KB. |
|
LONG RAW |
VARCHAR (maximum LOB size *2) The maximum LOB size cannot exceed 31 KB. Amazon Redshift does not support VARCHARs larger than 64 KB. |
|
XMLTYPE |
VARCHAR (maximum LOB size) The maximum LOB size cannot exceed 63 KB. Amazon Redshift does not support VARCHARs larger than 64 KB. |
DDL operations for RDS for PostgreSQL
Amazon Redshift is derived from PostgreSQL, so it shares several features with RDS for PostgreSQL due to their common PostgreSQL architecture. Zero-ETL integrations leverage these similarities to streamline data replication from RDS for PostgreSQL to Amazon Redshift, mapping databases by name and utilizing the shared database, schema, and table structure.
Consider the following points when managing RDS for PostgreSQL zero-ETL integrations:
-
Isolation is managed at the database level.
-
Replication occurs at the database level.
-
RDS for PostgreSQL databases are mapped to Amazon Redshift databases by name, with data flowing to the corresponding renamed Redshift database if the original is renamed.
Despite their similarities, Amazon Redshift and RDS for PostgreSQL have important differences. The following sections outline Amazon Redshift system responses for common DDL operations.
Database operations
The following table shows the system responses for database DDL operations.
| DDL operation | Redshift system response |
|---|---|
CREATE DATABASE |
No operation |
DROP DATABASE |
Amazon Redshift drops all the data in the target Redshift database. |
RENAME DATABASE |
Amazon Redshift drops all the data in the original target database and resynchronize the data in the new target database. If the new database doesn't exist, you must manually create it. For instructions, see Create a destination database in Amazon Redshift. |
Schema operations
The following table shows the system responses for schema DDL operations.
| DDL operation | Redshift system response |
|---|---|
CREATE SCHEMA |
No operation |
DROP SCHEMA |
Amazon Redshift drops the original schema. |
RENAME SCHEMA |
Amazon Redshift drops the original schema then resynchronizes the data in the new schema. |
Table operations
The following table shows the system responses for table DDL operations.
| DDL operation | Redshift system response |
|---|---|
CREATE TABLE |
Amazon Redshift creates the table. Some operations cause table creation to fail, such as creating a table without a primary key or performing declarative partitioning. For more information, see Limitations and Troubleshooting Amazon RDS zero-ETL integrations. |
DROP TABLE |
Amazon Redshift drops the table. |
TRUNCATE TABLE |
Amazon Redshift truncates the table. |
ALTER TABLE
(RENAME...) |
Amazon Redshift renames the table or column. |
ALTER TABLE (SET
SCHEMA) |
Amazon Redshift drops the table in the original schema and resynchronizes the table in the new schema. |
ALTER TABLE (ADD PRIMARY
KEY) |
Amazon Redshift adds a primary key and resynchronizes the table. |
ALTER TABLE (ADD
COLUMN) |
Amazon Redshift adds a column to the table. |
ALTER TABLE (DROP
COLUMN) |
Amazon Redshift drops the column if it's not a primary key column. Otherwise, it resynchronizes the table. |
ALTER TABLE (SET
LOGGED/UNLOGGED) |
If you change the table to logged, Amazon Redshift resynchronizes the table. If you change the table to unlogged, Amazon Redshift drops the table. |