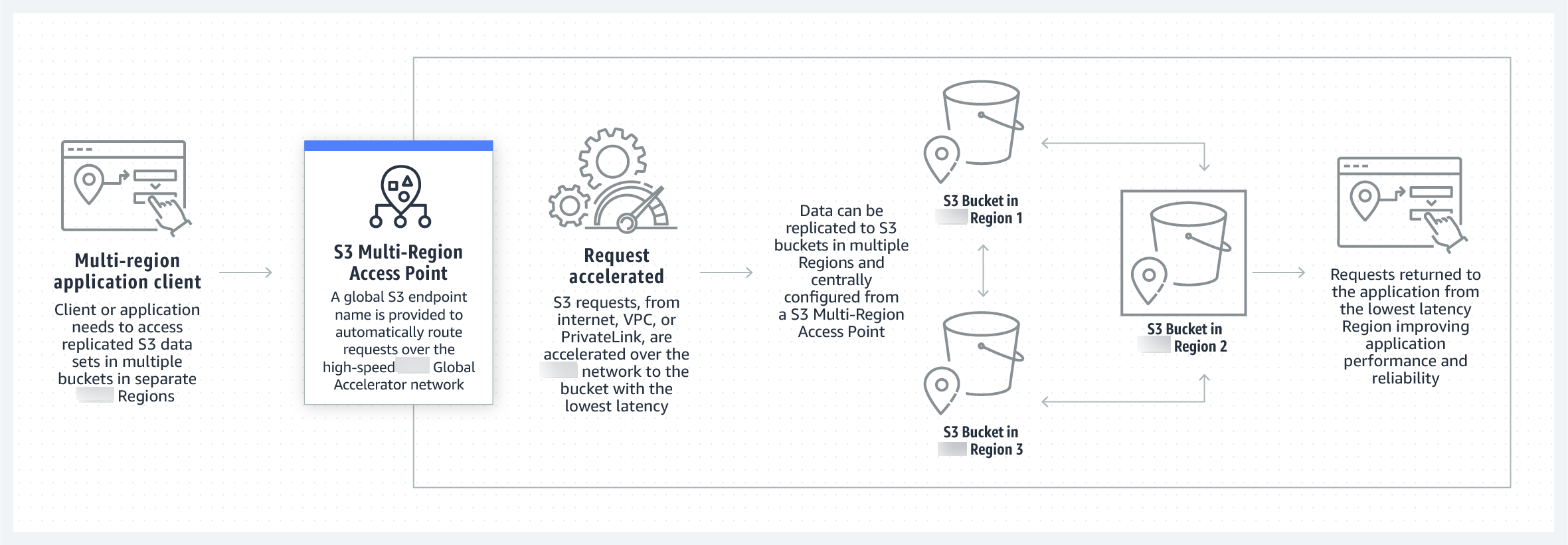
Managing multi-Region traffic with Multi-Region Access Points
Amazon S3 Multi-Region Access Points provides a global endpoint that applications can use to fulfill requests from S3 buckets that are located in multiple Amazon Web Services Regions. You can use Multi-Region Access Points to build multi-Region applications with the same architecture that's used in a single Region, and then run those applications anywhere in the world. Instead of sending requests over the congested public internet, Multi-Region Access Points provides built-in network resilience with acceleration of internet-based requests to Amazon S3. Application requests made to a Multi-Region Access Point global endpoint uses Amazon Global Accelerator to automatically route over the Amazon global network to the closest proximity S3 bucket with an active routing status.
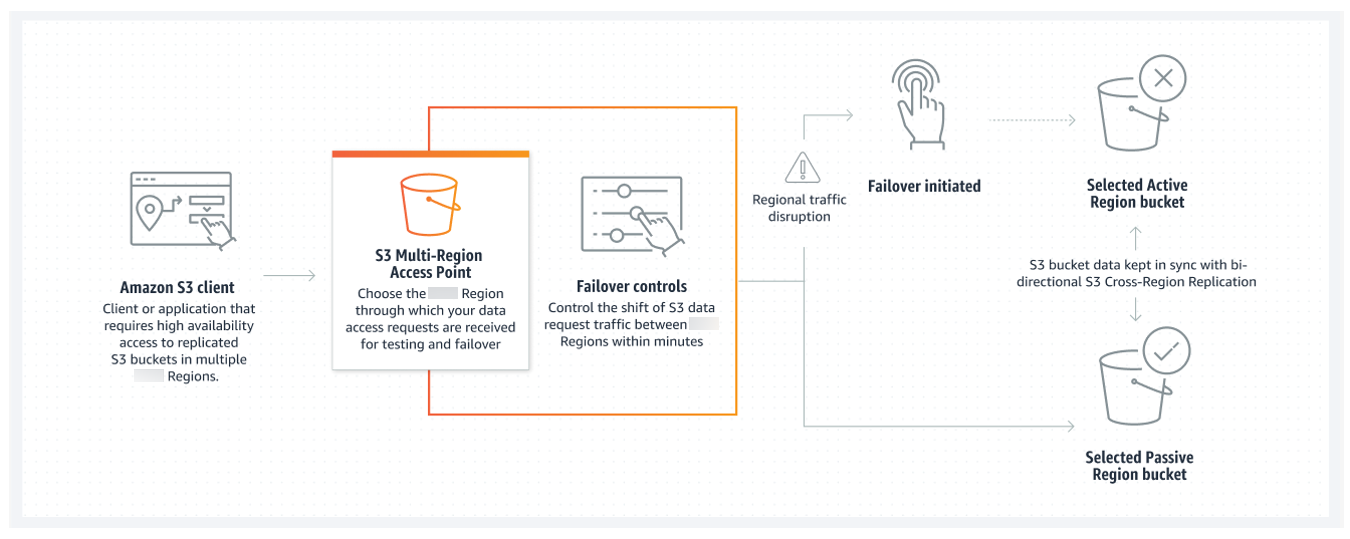
If a Regional traffic disruption occurs, you can use Multi-Region Access Points failover controls to shift the S3 data request traffic between Amazon Web Services Regions and redirect S3 traffic away from the disruptions within minutes. You can also test the application resiliency against a disruption to conduct application failover and perform disaster recovery simulations. If you need to connect and accelerate requests to S3 from outside of a VPC, you can simplify applications and network architecture with Amazon S3 Multi-Region Access Points. Your Multi-Region Access Points requests will be routed over the Amazon global network and then back to S3 within the Amazon Web Services Region, without having to traverse the public internet. As a result, you can build more highly available applications.
During your Multi-Region Access Points creation and setup, you'll specify a set of Amazon Web Services Regions where you want to store data
to be served through that Multi-Region Access Point. You can use the provided Multi-Region Access Points endpoint name to connect your
clients. After you've established your client connections, you can select the existing or
new buckets that you'd like to route the Multi-Region Access Points requests between. Then, use S3 Cross-Region Replication
(CRR)
After you've set up your Multi-Region Access Point. you can then request or write data through the Multi-Region Access Points global endpoint. Amazon S3 automatically serves requests to the replicated data set from the closest available Region. Within the Amazon Web Services Management Console, you're also able to view the underlying replication topology and replication metrics related to your Multi-Region Access Points requests. This gives you an even easier way to build, manage, and monitor storage for multi-Region applications. Alternatively, you can use Amazon CloudFront to automate the creation and configuration of S3 Multi-Region Access Points.
The following image is a graphical representation of an Amazon S3 Multi-Region Access Point in an active-active configuration. The graphic shows how Amazon S3 requests are automatically routed to buckets in the closest active Amazon Web Services Region.
The following image is a graphical representation of an Amazon S3 Multi-Region Access Point in an active-passive configuration. The graphic shows how you can control Amazon S3 data-access traffic to fail over between active and passive Amazon Web Services Regions.