Best practices to optimize S3 Express One Zone performance
When building applications that upload and retrieve objects from Amazon S3 Express One Zone, follow our best practice guidelines to optimize performance. To use the S3 Express One Zone storage class, you must create an S3 directory bucket. The S3 Express One Zone storage class isn't supported for use with S3 general purpose buckets.
For performance guidelines for all other Amazon S3 storage classes and S3 general purpose buckets, see Best practices design patterns: optimizing Amazon S3 performance.
For optimal performance and scalability with S3 Express One Zone storage class and directory buckets in high-scale workloads, it's important to understand how directory buckets work differently from general purpose buckets. Then, we provide best practices to align your applications with the way directory buckets work.
How directory buckets work
Amazon S3 Express One Zone storage class can support workloads with up to 2,000,000 GET and up to 200,000 PUT transactions per second (TPS) per directory bucket. With S3 Express One Zone, data is stored in S3 directory buckets in Availability Zones. Objects in directory buckets are accessible within a hierarchical namespace, similar to a file system and in contrast to S3 general purpose buckets that have a flat namespace. Unlike general purpose buckets, directory buckets organize keys hierarchically into directories instead of prefixes. A prefix is a string of characters at the beginning of the object key name. You can use prefixes to organize your data and manage a flat object storage architecture in general purpose buckets. For more information, see Organizing objects using prefixes.
In directory buckets, objects are organized in a hierarchical namespace using forward slash (/) as the only supported delimiter. When you upload an object with a key like dir1/dir2/file1.txt, the directories dir1/ and dir2/ are automatically created and managed by Amazon S3. Directories are created during PutObject or CreateMultiPartUpload operations and automatically removed when they become empty after DeleteObject or AbortMultiPartUpload operations. There is no upper limit to the number of objects and subdirectories in a directory.
The directories that are created when objects are uploaded to directory buckets can scale instantaneously to reduce the chance of HTTP 503 (Slow Down) errors. This automatic scaling allows your applications to parallelize read and write requests within and across directories as needed. For S3 Express One Zone, individual directories are designed to support the maximum request rate of a directory bucket. There is no need to randomize key prefixes to achieve optimal performance as the system automatically distributes objects for even load distribution, but as a result, keys are not stored lexicographically in directory buckets. This is in contrast to S3 general purpose buckets where keys that are lexicographically closer are more likely to be co-located on the same server.
For more information about examples of directory bucket operations and directory interactions, see Directory bucket operation and directory interaction examples.
Best practices
Follow the best practices to optimize your directory bucket performance and help your workloads scale over time.
Use directories that contain many entries (objects or subdirectories)
Directory buckets deliver high performance by default for all workloads. For even greater performance optimization with certain operations, consolidating more entries (which are objects or subdirectories) into directories will lead to lower latency and higher request rate:
Mutating API operations, such as
PutObject,DeleteObject,CreateMultiPartUploadandAbortMultiPartUpload, achieve optimal performance when implemented with fewer, denser directories containing thousands of entries, rather than with a large number of smaller directories.ListObjectsV2operations perform better when fewer directories need to be traversed to populate a page of results.
Don't use entropy in prefixes
In Amazon S3 operations, entropy refers to the randomness in prefix naming that helps distribute workloads evenly across storage partitions. However, since directory buckets internally manage load distribution, it's not recommended to use entropy in prefixes for the best performance. This is because for directory buckets, entropy can cause requests to be slower by not reusing the directories that have already been created.
A key pattern such as $HASH/directory/object could end up creating many intermediate directories. In the following example, all the job-1 s are different directories since their parents are different. Directories will be sparse and mutation and list requests will be slower. In this example there are 12 intermediate Directories that all have a single entry.
s3://my-bucket/0cc175b9c0f1b6a831c399e269772661/job-1/file1 s3://my-bucket/92eb5ffee6ae2fec3ad71c777531578f/job-1/file2 s3://my-bucket/4a8a08f09d37b73795649038408b5f33/job-1/file3 s3://my-bucket/8277e0910d750195b448797616e091ad/job-1/file4 s3://my-bucket/e1671797c52e15f763380b45e841ec32/job-1/file5 s3://my-bucket/8fa14cdd754f91cc6554c9e71929cce7/job-1/file6
Instead, for better performance, we can remove the $HASH component and allow job-1 to become a single directory, improving the density of a directory. In the following example, the single intermediate directory that has 6 entries can lead to better performance, compared with the previous example.
s3://my-bucket/job-1/file1 s3://my-bucket/job-1/file2 s3://my-bucket/job-1/file3 s3://my-bucket/job-1/file4 s3://my-bucket/job-1/file5 s3://my-bucket/job-1/file6
This performance advantage occurs because when an object key is initially created and its key name includes a directory, the directory is automatically created for the object. Subsequent object uploads to that same directory do not require the directory to be created, which reduces latency on object uploads to existing directories.
Use a separator other than the delimiter / to separate parts of your key if you don't need the ability to logically group objects during ListObjectsV2 calls
Since the / delimiter is treated specially for directory buckets, it should be used with intention. While directory buckets do not lexicographically order objects, objects within a directory are still grouped together in ListObjectsV2 outputs. If you don't need this functionality, you can replace / with another character as a separator to not cause the creation of intermediate directories.
For example, assume the following keys are in a YYYY/MM/DD/HH/ prefix pattern
s3://my-bucket/2024/04/00/01/file1 s3://my-bucket/2024/04/00/02/file2 s3://my-bucket/2024/04/00/03/file3 s3://my-bucket/2024/04/01/01/file4 s3://my-bucket/2024/04/01/02/file5 s3://my-bucket/2024/04/01/03/file6
If you don't have the need to group objects by hour or day in ListObjectsV2 results, but you need to group objects by month, the following key pattern of YYYY/MM/DD-HH- will lead to significantly fewer directories and better performance for the ListObjectsV2 operation.
s3://my-bucket/2024/04/00-01-file1 s3://my-bucket/2024/04/00-01-file2 s3://my-bucket/2024/04/00-01-file3 s3://my-bucket/2024/04/01-02-file4 s3://my-bucket/2024/04/01-02-file5 s3://my-bucket/2024/04/01-02-file6
Use delimited list operations where possible
A ListObjectsV2 request without a delimiter performs depth-first recursive traversal of all directories.
A ListObjectsV2 request with a delimiter retrieves only entries in the directory specified by the prefix parameter, reducing request latency and increasing aggregate keys per second. For directory buckets, use delimited list operations where possible. Delimited lists result in directories being visited fewer times, which leads to more keys per second and lower request latency.
For example, for the following directories and objects in your directory bucket:
s3://my-bucket/2024/04/12-01-file1 s3://my-bucket/2024/04/12-01-file2 ... s3://my-bucket/2024/05/12-01-file1 s3://my-bucket/2024/05/12-01-file2 ... s3://my-bucket/2024/06/12-01-file1 s3://my-bucket/2024/06/12-01-file2 ... s3://my-bucket/2024/07/12-01-file1 s3://my-bucket/2024/07/12-01-file2 ...
For better ListObjectsV2 performance, use a delimited list to list your subdirectories and objects, if your application's logic allows for it. For example, you can run the following command for the delimited list operation,
aws s3api list-objects-v2 --bucket my-bucket --prefix '2024/' --delimiter '/'
The output is the list of subdirectories.
{ "CommonPrefixes": [ { "Prefix": "2024/04/" }, { "Prefix": "2024/05/" }, { "Prefix": "2024/06/" }, { "Prefix": "2024/07/" } ] }
To list each subdirectory with better performance, you can run a command like the following example:
Command:
aws s3api list-objects-v2 --bucket my-bucket --prefix '2024/04' --delimiter '/'
Output:
{ "Contents": [ { "Key": "2024/04/12-01-file1" }, { "Key": "2024/04/12-01-file2" } ] }
Co-locate S3 Express One Zone storage with your compute resources
With S3 Express One Zone, each directory bucket is located in a single Availability Zone that you select when you create the bucket. You can get started by creating a new directory bucket in an Availability Zone local to your compute workloads or resources. You can then immediately begin very low-latency reads and writes. Directory buckets are a type of S3 buckets where you can choose the Availability Zone in an Amazon Web Services Region to reduce latency between compute and storage.
If you access directory buckets across Availability Zones, you may experience slightly increased latency. To optimize performance, we recommend that you access a directory bucket from Amazon Elastic Container Service, Amazon Elastic Kubernetes Service, and Amazon Elastic Compute Cloud instances that are located in the same Availability Zone when possible.
Use concurrent connections to achieve high throughput with objects over 1MB
You can achieve the best performance by issuing multiple concurrent requests to directory buckets to spread your requests over separate connections to maximize the accessible bandwidth. Like general purpose buckets, S3 Express One Zone doesn't have any limits for the number of connections made to your directory bucket. Individual directories can scale performance horizontally and automatically when large numbers of concurrent writes to the same directory are happening.
Individual TCP connections to directory buckets have a fixed upper bound on the number of bytes that can be uploaded or downloaded per second. When objects get larger, request times become dominated by byte streaming rather than transaction processing. To use multiple connections to parallelize the upload or download of larger objects, you can reduce end-to-end latency. If using the Java 2.x SDK, you should consider using the
S3 Transfer Manager which will take advantage of performance improvements such as the multipart upload API operations and byte-range fetches to access data in parallel.
Use Gateway VPC endpoints
Gateway endpoints provide a direct connection from your VPC to directory buckets, without requiring an internet gateway or a NAT device for your VPC. To reduce the amount of time your packets spend on the network, you should configure your VPC with a gateway VPC endpoint for directory buckets. For more information, see Networking for directory buckets.
Use session authentication and reuse session tokens while they're valid
Directory buckets provide a session token authentication mechanism to reduce
latency on performance-sensitive API operations. You can make a single call to
CreateSession to get a session token which is then valid for all requests in the
following 5 minutes. To get the lowest latency in your API calls, make sure to
acquire a session token and reuse it for the entire lifetime of that token before
refreshing it.
If you use Amazon SDKs, SDKs handle the session token refreshes automatically to avoid service interruptions when a session expires. We recommend that you use the Amazon SDKs to initiate and manage requests to the CreateSession API operation.
For more information about CreateSession, see Authorizing Zonal endpoint API operations with CreateSession.
Use a CRT-based client
The Amazon Common Runtime (CRT) is a set of modular, performant, and efficient libraries written in C and meant to act as the base of the Amazon SDKs. The CRT provides improved throughput, enhanced connection management, and faster startup times. The CRT is available through all the Amazon SDKs except Go.
For more information on how to configure the CRT for the SDK you use, see Amazon Common Runtime (CRT) libraries, Accelerate Amazon S3 throughput with the Amazon Common Runtime
Use the latest version of the Amazon SDKs
The Amazon SDKs provide built-in support for many of the recommended guidelines for optimizing Amazon S3 performance. The SDKs offer a simpler API for taking advantage of Amazon S3 from within an application and are regularly updated to follow the latest best practices. For example, the SDKs automatically retry requests after HTTP 503 errors and handle slow connections responses.
If using the Java 2.x SDK, you should consider using the S3 Transfer Manager, which automatically scales connections horizontally to achieve thousands of requests per second using byte-range requests when appropriate. Byte-range requests can improve performance because you can use concurrent connections to S3 to fetch different byte ranges from within the same object. This helps you achieve higher aggregate throughput versus a single whole-object request. So it's important to use the latest version of the Amazon SDKs to obtain the latest performance optimization features.
Performance troubleshooting
Are you setting retry requests for latency-sensitive applications?
S3 Express One Zone is purpose-built to deliver consistent levels of high-performance without additional tuning. However, setting aggressive timeout values and retries can further help drive consistent latency and performance. The Amazon SDKs have configurable timeout and retry values that you can tune to the tolerances of your specific application.
Are you using Amazon Common Runtime (CRT) libraries and optimal Amazon EC2 instance types?
Applications that perform a large number of read and write operations likely need more memory or computing capacity than applications that don't. When launching your Amazon Elastic Compute Cloud (Amazon EC2) instances for your performance-demanding workload, choose instance types that have the amount of these resources that your application needs. S3 Express One Zone high-performance storage is ideally paired with larger and newer instance types with larger amounts of system memory and more powerful CPUs and GPUs that can take advantage of higher-performance storage. We also recommend using the latest versions of the CRT-enabled Amazon SDKs, which can better accelerate read and write requests in parallel.
Are you using Amazon SDKs for session-based authentication?
With Amazon S3, you can also optimize performance when you're using HTTP REST API requests by following the same best practices that are part of the Amazon SDKs. However, with the session-based authorization and authentication mechanism that's used by S3 Express One Zone, we strongly recommend that you use the Amazon SDKs to manage CreateSession and its managed session token. The Amazon SDKs automatically create and refresh tokens on your behalf by using the CreateSession API operation. Using CreateSession saves on per-request round-trip latency to Amazon Identity and Access Management (IAM) to authorize each request.
Directory bucket operation and directory interaction examples
The following shows three examples about how directory buckets work.
Example 1: How S3 PutObject requests to a directory bucket interact with directories
-
When the operation
PUT(<bucket>, "documents/reports/quarterly.txt")is executed in an empty bucket, the directorydocuments/within the root of the bucket is created, the directoryreports/withindocuments/is created, and the objectquarterly.txtwithinreports/is created. For this operation, two directories were created in addition to the object.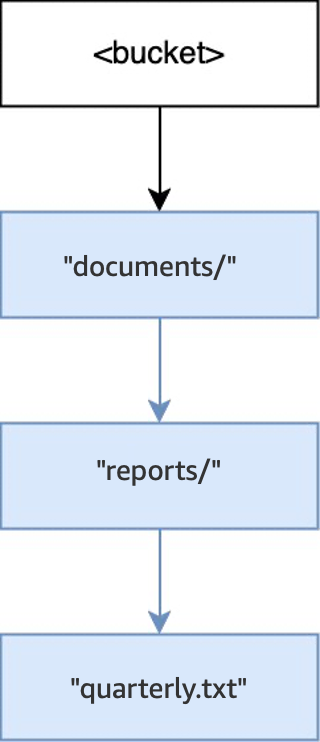
-
Then, when another operation
PUT(<bucket>, "documents/logs/application.txt")is executed, the directorydocuments/already exists, the directorylogs/withindocuments/doesn't exist and is created, and the objectapplication.txtwithinlogs/is created. For this operation, only one directory was created in addition to the object.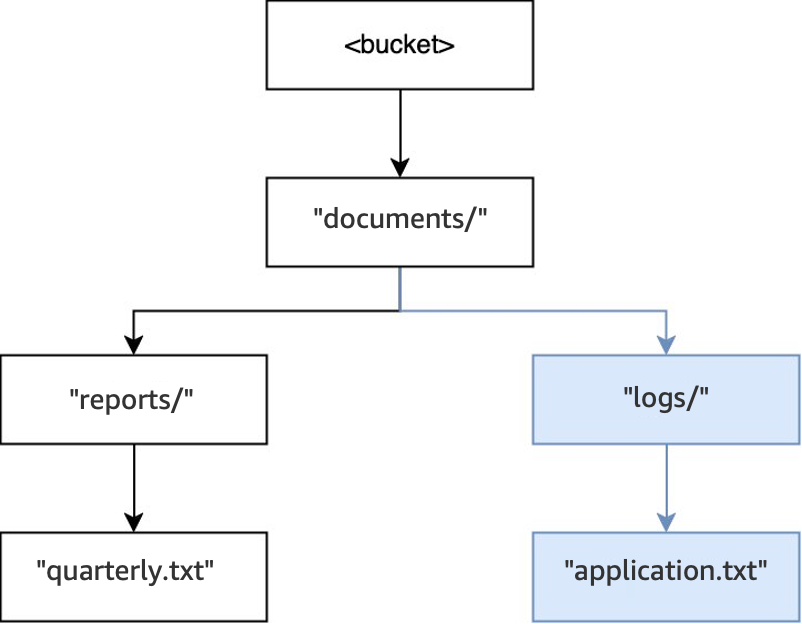
-
Lastly, when a
PUT(<bucket>, "documents/readme.txt")operation is executed, the directorydocuments/within the root already exists and the objectreadme.txtis created. For this operation, no directories are created.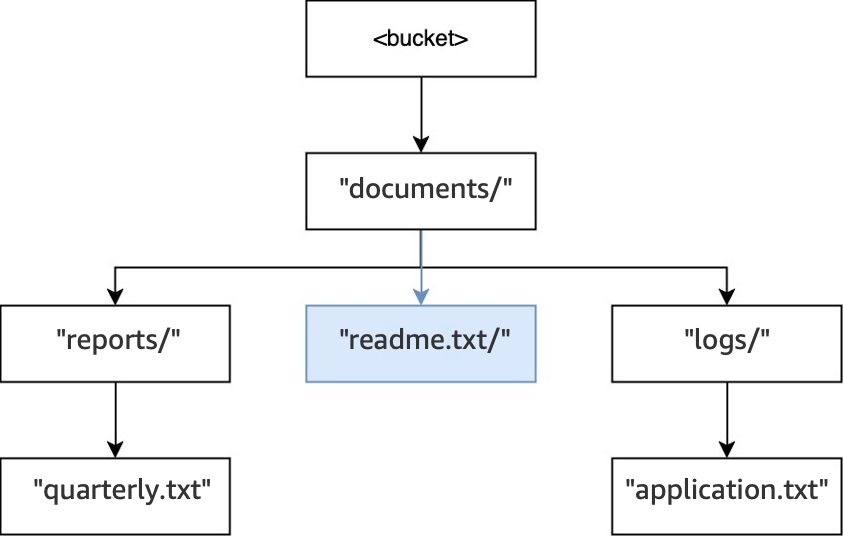
Example 2: How S3 ListObjectsV2 requests to a directory bucket interact with directories
For the S3 ListObjectsV2 requests without specifying a delimiter, a bucket is traversed in a depth-first manner. The outputs are returned in a consistent order. However, while this order remains the same between requests, the order is not lexicographic. For the bucket and directories created in the previous example:
-
When a
LIST(<bucket>)is executed, the directorydocuments/is entered and the traversing begins. -
The subdirectory
logs/is entered and the traversing begins. -
The object
application.txtis found withinlogs/. -
No more entries exist within
logs/. The List operation exits fromlogs/and entersdocuments/again. -
The
documents/directory continues being traversed and the objectreadme.txtis found. -
The
documents/directory continues being traversed and the subdirectoryreports/is entered and the traversing begins. -
The object
quarterly.txtis found withinreports/. -
No more entries exist within
reports/. The List exits fromreports/and entersdocuments/again. -
No more entries exist within
documents/and the List returns.
In this example, logs/ is ordered before readme.txt and readme.txt is ordered before reports/.
Example 3: How S3 DeleteObject requests to a directory bucket interact with directories
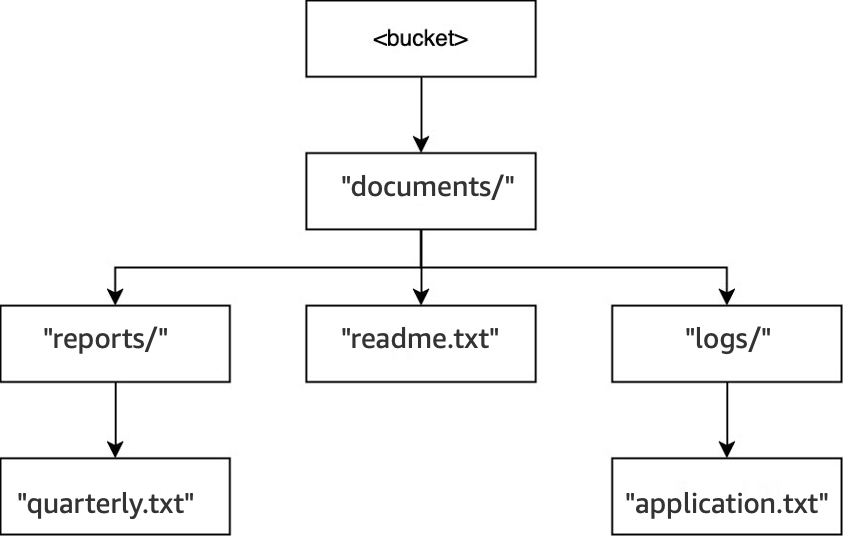
-
In that same bucket, when the operation
DELETE(<bucket>, "documents/reports/quarterly.txt")is executed, the objectquarterly.txtis deleted, leaving the directoryreports/empty and causing it to be deleted immediately. Thedocuments/directory is not empty because it has both the directorylogs/and the objectreadme.txtwithin it, so it's not deleted. For this operation, only one object and one directory were deleted.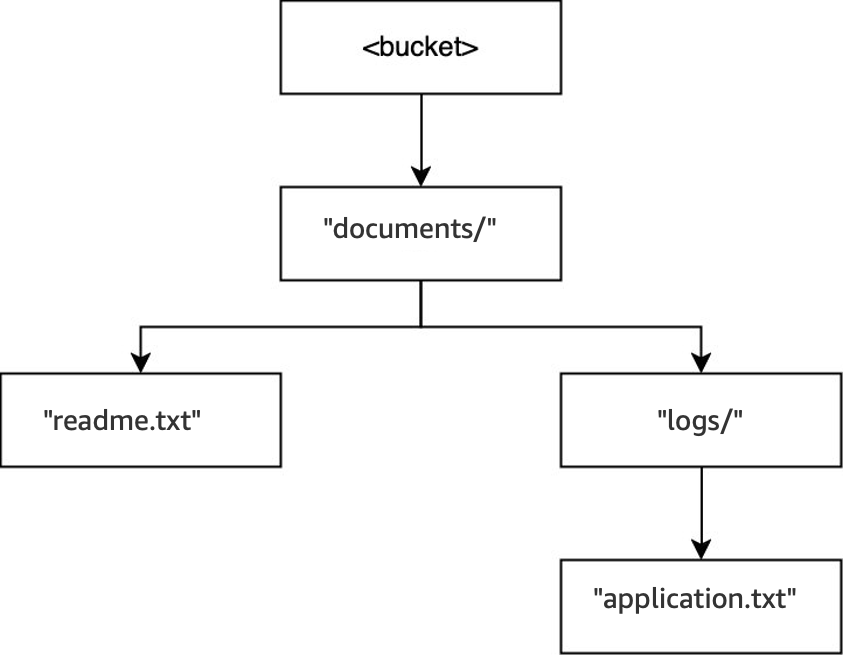
-
When the operation
DELETE(<bucket>, "documents/readme.txt")is executed, the objectreadme.txtis deleted.documents/is still not empty because it contains the directorylogs/, so it's not deleted. For this operation, no directories are deleted and only the object is deleted.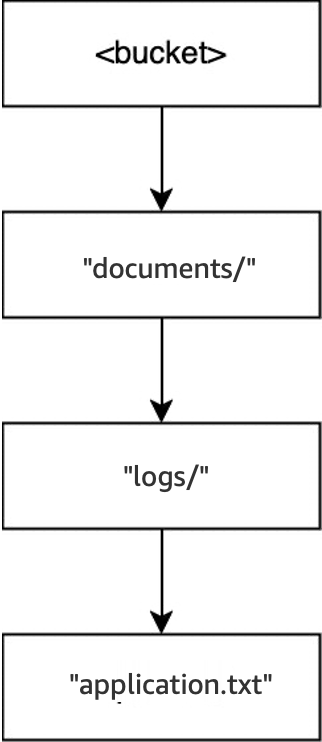
-
Lastly, when the operation
DELETE(<bucket>, "documents/logs/application.txt")is executed,application.txtis deleted, leavinglogs/empty and causing it to be deleted immediately. This then leavesdocuments/empty and causing it to also be deleted immediately. For this operation, two directories and one object are deleted. The bucket is now empty.