Best practices for performance optimization and efficiency in Amazon MQ for RabbitMQ
You can optimize your Amazon MQ for RabbitMQ broker performance by maximizing throughput, minimizing latency, and ensuring efficient resource utilization. Complete the following best practices to optimize your application performance.
Step 1: Keep message sizes under 1 MB
We recommend keeping messages under 1 Megabyte (MB) for optimal performance and reliability.
RabbitMQ 3.13 supports message sizes up to 128 MB by default, but large messages may trigger unpredictable memory alarms that block publishing and potentially create high memory pressure while replicating messages across nodes. Oversized messages can also affect broker restart and recovery processes, which increases risks to service continuity and may cause performance degradation.
Store and retrieve large payloads using the claim check pattern
To manage large messages, you can implement the claim check pattern by storing the message payload in external storage and sending only the payload reference identifier through RabbitMQ. The consumer uses the payload reference identifier to retrieve and process the large message.
The following diagram demonstrates how to use Amazon MQ for RabbitMQ and Amazon S3 to implement the claim check pattern.
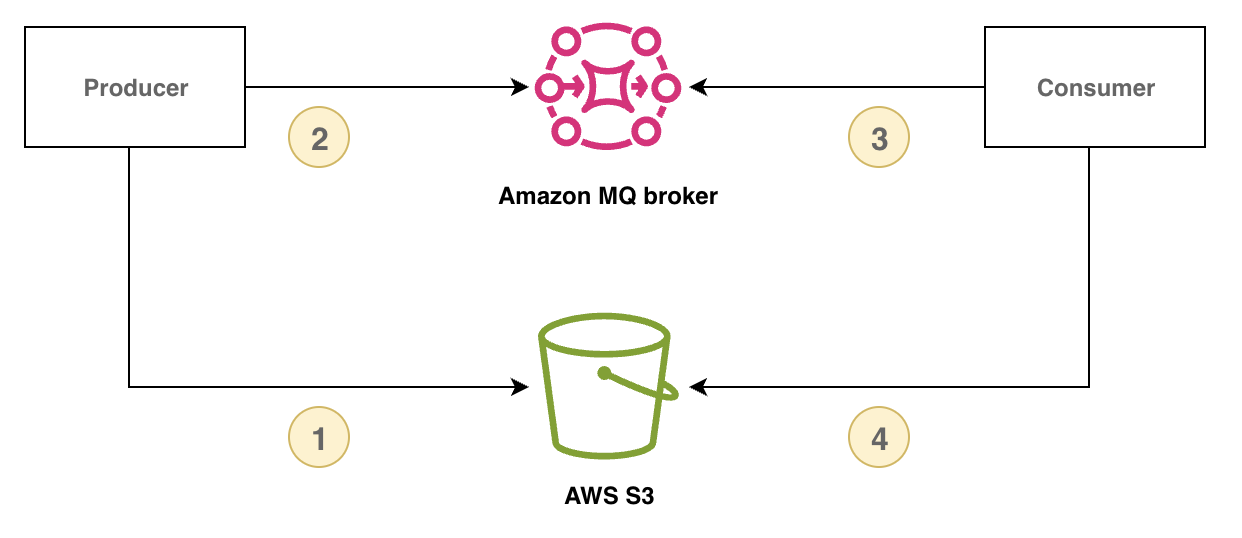
The following example demonstrates this pattern using Amazon MQ,
the Amazon SDK for Java 2.x
-
First, define a Message class that will hold the Amazon S3 reference identifier.
class Message { // Other data fields of the message... public String s3Key; public String s3Bucket; } -
Create a publisher method that stores the payload in Amazon S3 and sends a reference message through RabbitMQ.
public void publishPayload() { // Store the payload in S3. String payload = PAYLOAD; String prefix = S3_KEY_PREFIX; String s3Key = prefix + "/" + UUID.randomUUID(); s3Client.putObject(PutObjectRequest.builder() .bucket(S3_BUCKET).key(s3Key).build(), RequestBody.fromString(payload)); // Send the reference through RabbitMQ. Message message = new Message(); message.s3Key = s3Key; message.s3Bucket = S3_BUCKET; // Assign values to other fields in your message instance. publishMessage(message); } -
Implement a consumer method that retrieves the payload from Amazon S3, processes the payload, and deletes the Amazon S3 object.
public void consumeMessage(Message message) { // Retrieve the payload from S3. String payload = s3Client.getObjectAsBytes(GetObjectRequest.builder() .bucket(message.s3Bucket).key(message.s3Key).build()) .asUtf8String(); // Process the complete message. processPayload(message, payload); // Delete the S3 object. s3Client.deleteObject(DeleteObjectRequest.builder() .bucket(message.s3Bucket).key(message.s3Key).build()); }
Step 2: Use basic.consume and long-lived consumers
Using basic.consume with a long-lived consumer is more efficient than
polling for individual messages using basic.get. For more information,
see Polling for individual messages
Step 3: Configure pre-fetching
You can use the RabbitMQ pre-fetch value to optimize how your consumers consume messages. RabbitMQ implements the channel pre-fetch mechanism provided by AMQP 0-9-1 by applying the pre-fetch count to consumers as opposed to channels. The pre-fetch value is used to specify how many messages are being sent to the consumer at any given time. By default, RabbitMQ sets an unlimited buffer size for client applications.
There are a variety of factors to consider when setting a pre-fetch count for your RabbitMQ consumers. First, consider your consumers' environment and configuration. Because consumers need to keep all messages in memory as they are being processed, a high pre-fetch value can have a negative impact on your consumers' performance, and in some cases, can result in a consumer potentially crashing all together. Similarly, the RabbitMQ broker itself keeps all messages that it sends cached in memory until it recieves consumer acknowledgement. A high pre-fetch value can cause your RabbitMQ server to run out of memory quickly if automatic acknowledgement is not configured for consumers, and if consumers take a relatively long time to process messages.
With the above considerations in mind, we recommend always setting a pre-fetch value in order to prevent situations where a RabbitMQ broker or its consumers run out of memory due to a large number number of unprocessed, or unacknowledged messages. If you need to optimize your brokers to process large volumes of messages, you can test your brokers and consumers using a range of pre-fetch counts to determine the value at which point network overhead becomes largely insignificant compared to the time it takes a consumer to process messages.
Note
If your client applications have configured to automatically acknowledge delivery of messages to consumers, setting a pre-fetch value will have no effect.
All pre-fetched messages are removed from the queue.
The following example desmonstrate setting a pre-fetch value of 10 for a single consumer using the RabbitMQ Java client library.
ConnectionFactory factory = new ConnectionFactory(); Connection connection = factory.newConnection(); Channel channel = connection.createChannel(); channel.basicQos(10, false); QueueingConsumer consumer = new QueueingConsumer(channel); channel.basicConsume("my_queue", false, consumer);
Note
In the RabbitMQ Java client library, the default value for the global flag is set to false, so
the above example can be written simply as channel.basicQos(10).
Step 4: Use Celery 5.5 or later with quorum queues
Python Celery
For all Celery versions
-
Turn off
task_create_missing_queuesto mitigate queue churn. -
Then, turn off
worker_enable_remote_controlto stop dynamic creation ofcelery@...pidboxqueues. This will reduce queue churn on the broker.worker_enable_remote_control = false -
To further reduce non-critical message activity, turn off Celery worker-send-task-events
by not including -Eor--task-eventsflag when starting your Celery application. -
Start your Celery application using the following parameters:
celery -A app_name worker --without-heartbeat --without-gossip --without-mingle
For Celery versions 5.5 and above
-
Upgrade to Celery version 5.5
, the minimum version that supports quorum queues, or a later version. To check what version of Celery you are using, use celery --version. For more information on quorum queues, see Quorum queues for RabbitMQ on Amazon MQ. -
After upgrading to Celery 5.5 or later, configure
task_default_queue_typeto "quorum". -
Then, you must also turn on Publish Confirms in Broker Transport Options
: broker_transport_options = {"confirm_publish": True}