Connect Athena to an Apache Hive metastore
To connect Athena to an Apache Hive metastore, you must create and configure a Lambda function. For a basic implementation, you can perform all required steps starting from the Athena management console.
Note
The following procedure requires that you have permission to create a custom IAM role for the Lambda function. If you do not have permission to create a custom role, you can use the Athena reference implementation to create a Lambda function separately, and then use the Amazon Lambda console to choose an existing IAM role for the function. For more information, see Connect Athena to a Hive metastore using an existing IAM execution role.
To connect Athena to a Hive metastore
Open the Athena console at https://console.amazonaws.cn/athena/
. If the console navigation pane is not visible, choose the expansion menu on the left.
-
Choose Data sources and catalogs.
-
On the upper right of the console, choose Create data source.
-
On the Choose a data source page, for Data sources, choose S3 - Apache Hive metastore.
-
Choose Next.
-
In the Data source details section, for Data source name, enter the name that you want to use in your SQL statements when you query the data source from Athena. The name can be up to 127 characters and must be unique within your account. It cannot be changed after you create it. Valid characters are a-z, A-Z, 0-9, _ (underscore), @ (at sign) and - (hyphen). The names
awsdatacatalog,hive,jmx, andsystemare reserved by Athena and cannot be used for data source names. -
For Lambda function, choose Create Lambda function, and then choose Create a new Lambda function in Amazon Lambda
The AthenaHiveMetastoreFunction page opens in the Amazon Lambda console. The page includes detailed information about the connector.
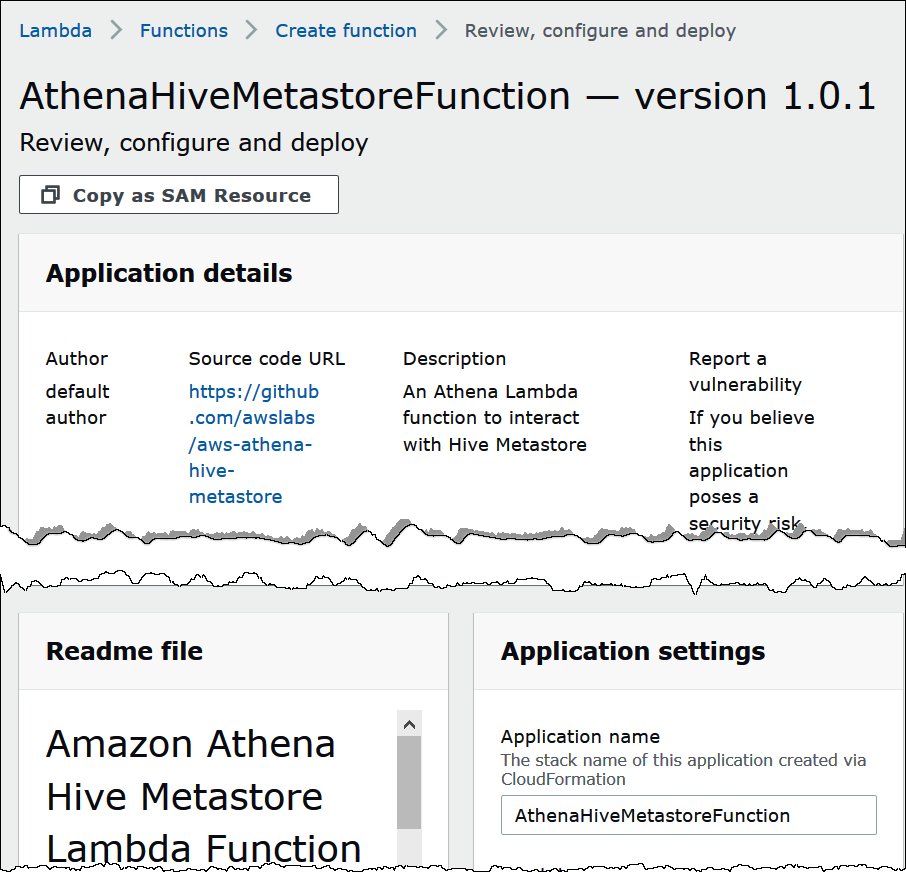
Under Application settings, enter the parameters for your Lambda function.
-
LambdaFuncName – Provide a name for the function. For example, myHiveMetastore.
-
SpillLocation – Specify an Amazon S3 location in this account to hold spillover metadata if the Lambda function response size exceeds 4 MB.
-
HMSUris – Enter the URI of your Hive metastore host that uses the Thrift protocol at port 9083. Use the syntax
thrift://<host_name>:9083. -
LambdaMemory – Specify a value from 128 MB to 3008 MB. The Lambda function is allocated CPU cycles proportional to the amount of memory that you configure. The default is 1024.
-
LambdaTimeout – Specify the maximum permissible Lambda invocation run time in seconds from 1 to 900 (900 seconds is 15 minutes). The default is 300 seconds (5 minutes).
-
VPCSecurityGroupIds – Enter a comma-separated list of VPC security group IDs for the Hive metastore.
-
VPCSubnetIds – Enter a comma-separated list of VPC subnet IDs for the Hive metastore.
-
-
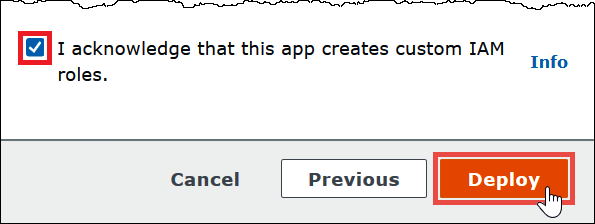
Select I acknowledge that this app creates custom IAM roles, and then choose Deploy.
When the deployment completes, your function appears in your list of Lambda applications. Now that the Hive metastore function has been deployed to your account, you can configure Athena to use it.
-
Return to the Enter data source details page of the Athena console.
-
In the Lambda function section, choose the refresh icon next to the Lambda function search box. Refreshing the list of available functions causes your newly created function to appear in the list.
-
Choose the name of the function that you just created in the Lambda console. The ARN of the Lambda function displays.
-
(Optional) For Tags, add key-value pairs to associate with this data source. For more information about tags, see Tag Athena resources.
-
Choose Next.
-
On the Review and create page, review the data source details, and then choose Create data source.
-
The Data source details section of the page for your data source shows information about your new connector.
You can now use the Data source name that you specified to reference the Hive metastore in your SQL queries in Athena. In your SQL queries, use the following example syntax, replacing
hms-catalog-1with the catalog name that you specified earlier.SELECT * FROM hms-catalog-1.CustomerData.customers -
For information about viewing, editing, or deleting the data sources that you create, see Manage your data sources.