Health checks for instances in an Auto Scaling group
Amazon EC2 Auto Scaling continuously monitors the health status of instances in an Auto Scaling group to maintain the desired capacity.
All instances in an Auto Scaling group start with a Healthy status. Instances are
assumed to be healthy unless Amazon EC2 Auto Scaling receives notification that they are unhealthy. It can
receive notifications from various sources when an instance becomes unhealthy and must be
replaced. These sources include the following:
-
Amazon EC2
-
Elastic Load Balancing
-
VPC Lattice
-
Amazon EBS
-
Custom health checks that you define
When Amazon EC2 Auto Scaling determines that an InService instance is unhealthy, it replaces
it with a new instance to maintain the desired capacity of the group. The new instance
launches using the current settings of the Auto Scaling group and its associated launch template or
launch configuration.
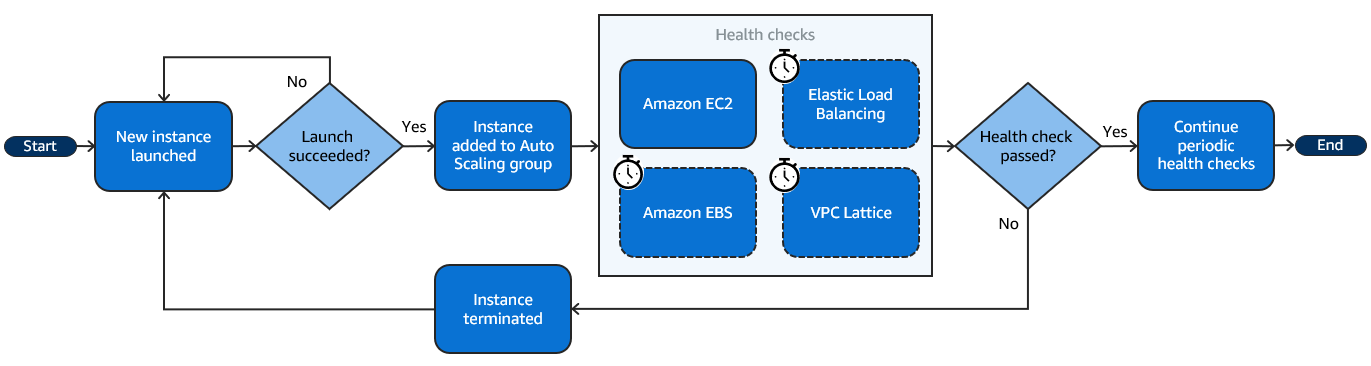
The following flow diagram illustrates the process of launching a new instance in an Auto Scaling group. It begins by launching the instance. If the launch succeeds, the instance gets added to the Auto Scaling group. Then, Amazon EC2 Auto Scaling performs health checks on the instance by using the built-in Amazon EC2 status checks, and after a grace period, any optional health checks that you enabled for the group. These health checks continue periodically. If any of the health checks fail, the instance is replaced.
Unhealthy instances can also occur when an instance terminates unexpectedly, such as from a Spot Instance interruption or manual termination by a user. Again, Amazon EC2 Auto Scaling will automatically launch a replacement instance in these cases to maintain the desired capacity.