Step 5: Configure an Amazon DMS Target Endpoint
To use Amazon S3 as an Amazon Database Migration Service (Amazon DMS) target endpoint, create an IAM role with write and delete access to the S3 bucket. Then add DMS (dms.amazonaws.com) as trusted entity in this IAM role. For more information, see Prerequisites for using Amazon S3 as a target.
When using Amazon DMS to migrate data to an Amazon Simple Storage Service (Amazon S3) data lake, you can change the default task behavior, such as file formats, partitioning, file sizing, and so on. This leads to minimizing post-migration processing and helps downstream applications consume data efficiently. You can customize task behavior using endpoint settings and extra connection attributes (ECA). Most of the Amazon S3 endpoint settings and ECA settings overlap, except for a few parameters. In this walkthrough, we will configure Amazon S3 endpoint settings.
Choose File Format
Amazon DMS supports data replication through comma-separated values (CSV) or Apache Parquet file formats. Each file format has its own benefits. Choose the right file format depending on your consumption pattern.
Apache Parquet is a columnar format, which is built to support efficient compression and encoding schemes providing storage space savings and performance benefits. With Parquet, you can specify compression schemes for each column to improve query performance when using avg(), max(), or other column level aggregation operations. That is why Parquet is popular for data lake and analytics use cases.
CSV files are helpful when you plan to keep data in human readable format, share or transfer Amazon S3 files into other downstream systems for further processing.
For this walkthrough, we will use the Parquet file format. Specify the following endpoint settings.
DataFormat=parquet ParquetVersion=PARQUET_2_0
Determine File Size
By default, during ongoing replication Amazon DMS tasks writes to Amazon S3 are triggered either if the file size reaches 32 KB or if the previous file write was more than 60 seconds ago. These settings ensure that the data capture latency is less than a minute. However, this approach creates a large number of small files in target Amazon S3 bucket.
Because we migrate our source Sales database schema for an analytics use case, some latency is acceptable. However, we need to optimize this schema for cost and performance. When you use distributed processing frameworks such as Amazon Athena, Amazon Glue or Amazon EMR, it is recommended to avoid too many small files (less than 64 MB). Small files create management overhead for the driver node of the distributed processing framework.
Because we plan to use Amazon Athena to query data from our Amazon S3 bucket, we need to make sure our target file size is at least 64 MB. Specify the following endpoint settings: CdcMaxBatchInterval=3600 and CdcMinFileSize=64000. These settings ensure that Amazon DMS writes the file until its size reaches 64 MB or if the last file write was more than an hour ago.
Note
Parquet files created by Amazon DMS are usually smaller than the specified CdcMinFileSize setting because Parquet data compression ratio varies depending on the source data set. The size of CSV files created by Amazon DMS is equal to the value specified in CdcMinFileSize.
Turn on S3 Partitioning
Partitioning in Amazon S3 structures your data by folders and subfolders that help efficiently query data. For example, if you receive sales record data daily from different regions and you query data for a specific region and find stats for a few months, then it is recommended to partition data by region, year, and month. In Amazon S3, the path for our use case looks as following:
s3://<sales-data-bucket-name>/<region>/<schemaname>/<tablename>/<year>/<month>/<day> s3://adventure-works-datalake - s3://adventure-works-datalake/US-WEST-DATA - s3://adventure-works-datalake/US-WEST-DATA/Sales - s3://adventure-works-datalake/US-WEST-DATA/Sales/CreditCard/ - s3://adventure-works-datalake/US-WEST-DATA/Sales/CreditCard/LOAD00000001.parquet - s3://adventure-works-datalake/US-WEST-DATA/Sales/SalesPerson - s3://adventure-works-datalake/US-WEST-DATA/Sales/SalesPerson/LOAD00000001.parquet - s3://adventure-works-datalake/US-WEST-DATA/Sales/SalesPerson/2021/11/23/ - s3://adventure-works-datalake/US-WEST-DATA/Sales/SalesPerson/2021/11/23/20211123-013830913.parquet - s3://adventure-works-datalake/US-WEST-DATA/Sales/SalesPerson/2021/11/27/20211127-175902985.parquet
Partitioning provides performance benefits because data scanning will be limited to the amount of data in the specific partition based on the filter condition in your queries. For our sales data example, your queries might look as follows:
SELECT <column-list> FROM <sales-table-name> WHERE <region> = <region-name> AND <year> = <year-value>
If you use Amazon Athena to query data, partitioning helps reduce cost as Athena pricing is based on the amount of data that you scan when running queries.
To turn on partitioning for ongoing changes in the preceding format, use the following queries.
bucketFolder=US-WEST-DATA DatePartitionedEnabled=true DatePartitionSequence=YYYYMMDD DatePartitionDelimiter=SLASH
Other Considerations
The preceding settings help optimize performance and cost. We also need to configure additional settings because:
-
Our use case does not have a fixed end-date.
-
We need to minimize issues arising from misconfigurations or retroactive changes.
-
We want to minimize recovery time in case of unforeseen issues.
Serialize ongoing replication events
A common challenge when using Amazon S3 as a target involves identifying the ongoing replication event sequence when multiple records are updated at the same time on the source database.
Amazon DMS provides two options to help serialize such events for Amazon S3. You can use the TimeStampColumnName endpoint setting or use transformation rules to include LSN column. Here, we will discuss the first option. For more information about the second option, see Step 6: Create an Amazon DMS Task.
Use the TimeStampColumnName endpoint setting
The TimeStampColumnName setting adds an additional STRING column to the target Parquet file created by Amazon DMS. During the ongoing replication, the column value represents the commit timestamp of the event in SQL Server. For the full load phase, the columns values represent the timestamp of data transfer to Amazon S3.
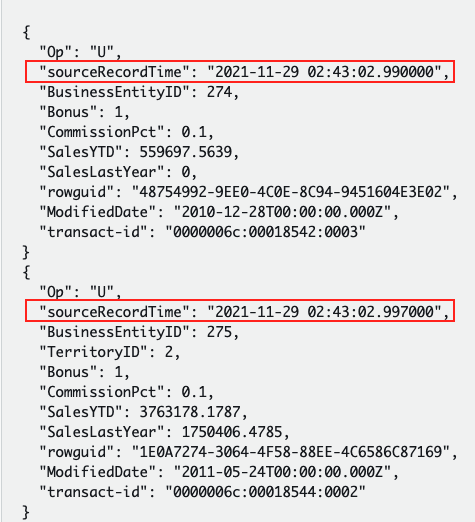
The default format is yyyy-MM-dd HH:mm:ss.SSSSSS. This format provides a microsecond precision but depends on the source database transaction log timestamp precision. The following image shows the seven microseconds difference between two operations in the sourceRecordTime field.
Note
Because TimeStampColumnName is an endpoint setting, all tasks that use this endpoint, will include this column for all tables.
Include full load operation field
All files created during the ongoing replication, have the first column marked with I, U, or D. These symbols represent the DML operation on the source and stand for Insert, Update, or Delete operations.
For full load files, you can add this column by configuring the endpoint setting.
includeOpForFullLoad=true
This ensures that all full load files are marked with an I operation.
When you use this approach, new subscribers can consume the entire data set or prepare a fresh copy in case of any downstream processing issues.
Create a Target Endpoint
After you completed all settings configurations, you can create a target endpoint.
To create a target endpoint, do the following:
-
Open the Amazon DMS console at https://console.aws.amazon.com/dms/v2/.
-
Choose Endpoints, and then choose Create endpoint.
-
On the Create endpoint page, enter the following information.
For This Parameter Do This Endpoint type
Choose Target endpoint, and turn off Select RDS DB instance.
Endpoint identifier
Enter adventure-works-datalake-target.
Target engine
Choose Amazon S3.
Service access role ARN
Enter the IAM role that can access your Amazon S3 data lake.
Bucket name
Enter adventure-works-datalake.
Bucket folder
Enter US-WEST-DATA.
-
Expand the Endpoint settings section, choose Wizard, and then choose Add new setting to add the settings as shown on the following image.

-
Choose Create endpoint.