Using an Amazon DynamoDB database as a target for Amazon Database Migration Service
You can use Amazon DMS to migrate data to an Amazon DynamoDB table. Amazon DynamoDB is a fully managed NoSQL database service that provides fast and predictable performance with seamless scalability. Amazon DMS supports using a relational database or MongoDB as a source.
In DynamoDB, tables, items, and attributes are the core components that you work with. A table is a collection of items, and each item is a collection of attributes. DynamoDB uses primary keys, called partition keys, to uniquely identify each item in a table. You can also use keys and secondary indexes to provide more querying flexibility.
You use object mapping to migrate your data from a source database to a target DynamoDB table. Object mapping enables you to determine where the source data is located in the target.
When Amazon DMS creates tables on an DynamoDB target endpoint, it creates as many tables as in the source database endpoint. Amazon DMS also sets several DynamoDB parameter values. The cost for the table creation depends on the amount of data and the number of tables to be migrated.
Note
The SSL Mode option on the Amazon DMS console or API doesn’t apply to some data streaming and NoSQL services like Kinesis and DynamoDB. They are secure by default, so Amazon DMS shows the SSL mode setting is equal to none (SSL Mode=None). You don’t need to provide any additional configuration for your endpoint to make use of SSL. For example, when using DynamoDB as a target endpoint, it is secure by default. All API calls to DynamoDB use SSL, so there is no need for an additional SSL option in the Amazon DMS endpoint. You can securely put data and retrieve data through SSL endpoints using the HTTPS protocol, which Amazon DMS uses by default when connecting to a DynamoDB database.
To help increase the speed of the transfer, Amazon DMS supports a multithreaded full load to a DynamoDB target instance. DMS supports this multithreading with task settings that include the following:
-
MaxFullLoadSubTasks– Use this option to indicate the maximum number of source tables to load in parallel. DMS loads each table into its corresponding DynamoDB target table using a dedicated subtask. The default value is 8. The maximum value is 49. -
ParallelLoadThreads– Use this option to specify the number of threads that Amazon DMS uses to load each table into its DynamoDB target table. The default value is 0 (single-threaded). The maximum value is 200. You can ask to have this maximum limit increased.Note
DMS assigns each segment of a table to its own thread for loading. Therefore, set
ParallelLoadThreadsto the maximum number of segments that you specify for a table in the source. -
ParallelLoadBufferSize– Use this option to specify the maximum number of records to store in the buffer that the parallel load threads use to load data to the DynamoDB target. The default value is 50. The maximum value is 1,000. Use this setting withParallelLoadThreads.ParallelLoadBufferSizeis valid only when there is more than one thread. -
Table-mapping settings for individual tables – Use
table-settingsrules to identify individual tables from the source that you want to load in parallel. Also use these rules to specify how to segment the rows of each table for multithreaded loading. For more information, see Table and collection settings rules and operations.
Note
When Amazon DMS sets DynamoDB parameter values for a migration task, the default Read Capacity Units (RCU) parameter value is set to 200.
The Write Capacity Units (WCU) parameter value is also set, but its value depends on several other settings:
-
The default value for the WCU parameter is 200.
-
If the
ParallelLoadThreadstask setting is set greater than 1 (the default is 0), then the WCU parameter is set to 200 times theParallelLoadThreadsvalue. Standard Amazon DMS usage fees apply to resources you use.
Migrating from a relational database to a DynamoDB table
Amazon DMS supports migrating data to DynamoDB scalar data types. When migrating from a relational database like Oracle or MySQL to DynamoDB, you might want to restructure how you store this data.
Currently Amazon DMS supports single table to single table restructuring to DynamoDB scalar type attributes. If you are migrating data into DynamoDB from a relational database table, you take data from a table and reformat it into DynamoDB scalar data type attributes. These attributes can accept data from multiple columns, and you can map a column to an attribute directly.
Amazon DMS supports the following DynamoDB scalar data types:
-
String
-
Number
-
Boolean
Note
NULL data from the source are ignored on the target.
Prerequisites for using DynamoDB as a target for Amazon Database Migration Service
Before you begin to work with a DynamoDB database as a target for Amazon DMS, make sure that you create an IAM role. This IAM role should allow Amazon DMS to assume and grant access to the DynamoDB tables that are being migrated into. The minimum set of access permissions is shown in the following IAM policy.
The role that you use for the migration to DynamoDB must have the following permissions.
Limitations when using DynamoDB as a target for Amazon Database Migration Service
The following limitations apply when using DynamoDB as a target:
-
DynamoDB limits the precision of the Number data type to 38 places. Store all data types with a higher precision as a String. You need to explicitly specify this using the object-mapping feature.
-
Because DynamoDB doesn't have a Date data type, data using the Date data type are converted to strings.
-
DynamoDB doesn't allow updates to the primary key attributes. This restriction is important when using ongoing replication with change data capture (CDC) because it can result in unwanted data in the target. Depending on how you have the object mapping, a CDC operation that updates the primary key can do one of two things. It can either fail or insert a new item with the updated primary key and incomplete data.
-
Amazon DMS only supports replication of tables with noncomposite primary keys. The exception is if you specify an object mapping for the target table with a custom partition key or sort key, or both.
-
Amazon DMS doesn't support LOB data unless it is a CLOB. Amazon DMS converts CLOB data into a DynamoDB string when migrating the data.
-
When you use DynamoDB as target, only the Apply Exceptions control table (
dmslogs.awsdms_apply_exceptions) is supported. For more information about control tables, see Control table task settings. Amazon DMS doesn't support the task setting
TargetTablePrepMode=TRUNCATE_BEFORE_LOADfor DynamoDB as a target.Amazon DMS doesn't support the task setting
TaskRecoveryTableEnabledfor DynamoDB as a target.BatchApplyis not supported for a DynamoDB endpoint.-
Amazon DMS cannot migrate attributes whose names match reserved words in DynamoDB. For more information, see Reserved words in DynamoDB in the Amazon DynamoDB Developer Guide.
Using object mapping to migrate data to DynamoDB
Amazon DMS uses table-mapping rules to map data from the source to the target DynamoDB table. To map data to a DynamoDB target, you use a type of table-mapping rule called object-mapping. Object mapping lets you define the attribute names and the data to be migrated to them. You must have selection rules when you use object mapping.
DynamoDB doesn't have a preset structure other than having a partition key and an optional sort key. If you have a noncomposite primary key, Amazon DMS uses it. If you have a composite primary key or you want to use a sort key, define these keys and the other attributes in your target DynamoDB table.
To create an object-mapping rule, you specify the rule-type as
object-mapping. This rule specifies what type of object
mapping you want to use.
The structure for the rule is as follows:
{ "rules": [ { "rule-type": "object-mapping", "rule-id": "<id>", "rule-name": "<name>", "rule-action": "<valid object-mapping rule action>", "object-locator": { "schema-name": "<case-sensitive schema name>", "table-name": "" }, "target-table-name": "<table_name>" } ] }
Amazon DMS currently supports map-record-to-record and
map-record-to-document as the only valid values for the
rule-action parameter. These values specify what Amazon DMS does by
default to records that aren't excluded as part of the exclude-columns
attribute list. These values don't affect the attribute mappings in any way.
-
You can use
map-record-to-recordwhen migrating from a relational database to DynamoDB. It uses the primary key from the relational database as the partition key in DynamoDB and creates an attribute for each column in the source database. When usingmap-record-to-record, for any column in the source table not listed in theexclude-columnsattribute list, Amazon DMS creates a corresponding attribute on the target DynamoDB instance. It does so regardless of whether that source column is used in an attribute mapping. -
You use
map-record-to-documentto put source columns into a single, flat DynamoDB map on the target using the attribute name "_doc." When usingmap-record-to-document, Amazon DMS places the data into a single, flat, DynamoDB map attribute on the source. This attribute is called "_doc". This placement applies to any column in the source table not listed in theexclude-columnsattribute list.
One way to understand the difference between the rule-action
parameters map-record-to-record and
map-record-to-document is to see the two parameters in
action. For this example, assume that you are starting with a relational database
table row with the following structure and data:

To migrate this information to DynamoDB, you create rules to map the data into a
DynamoDB table item. Note the columns listed for the exclude-columns
parameter. These columns are not directly mapped over to the target. Instead,
attribute mapping is used to combine the data into new items, such as where
FirstName and LastName are grouped
together to become CustomerName on the DynamoDB target.
NickName and income are not
excluded.
{ "rules": [ { "rule-type": "selection", "rule-id": "1", "rule-name": "1", "object-locator": { "schema-name": "test", "table-name": "%" }, "rule-action": "include" }, { "rule-type": "object-mapping", "rule-id": "2", "rule-name": "TransformToDDB", "rule-action": "map-record-to-record", "object-locator": { "schema-name": "test", "table-name": "customer" }, "target-table-name": "customer_t", "mapping-parameters": { "partition-key-name": "CustomerName", "exclude-columns": [ "FirstName", "LastName", "HomeAddress", "HomePhone", "WorkAddress", "WorkPhone" ], "attribute-mappings": [ { "target-attribute-name": "CustomerName", "attribute-type": "scalar", "attribute-sub-type": "string", "value": "${FirstName},${LastName}" }, { "target-attribute-name": "ContactDetails", "attribute-type": "document", "attribute-sub-type": "dynamodb-map", "value": { "M": { "Home": { "M": { "Address": { "S": "${HomeAddress}" }, "Phone": { "S": "${HomePhone}" } } }, "Work": { "M": { "Address": { "S": "${WorkAddress}" }, "Phone": { "S": "${WorkPhone}" } } } } } } ] } } ] }
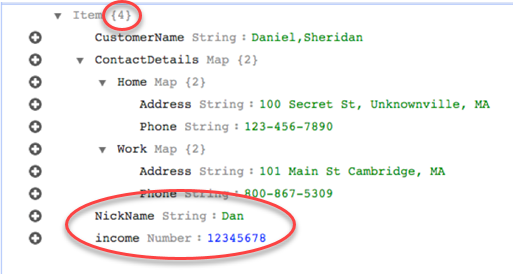
By using the rule-action parameter
map-record-to-record, the data for
NickName and income are mapped to
items of the same name in the DynamoDB target.
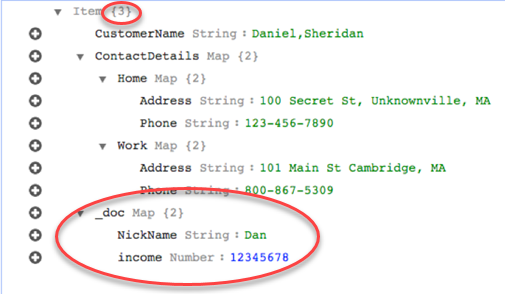
However, suppose that you use the same rules but change the
rule-action parameter to
map-record-to-document. In this case, the columns not
listed in the exclude-columns parameter, NickName
and income, are mapped to a _doc
item.
Using custom condition expressions with object mapping
You can use a feature of DynamoDB called conditional expressions to manipulate data that is being written to a DynamoDB table. For more information about condition expressions in DynamoDB, see Condition expressions.
A condition expression member consists of:
-
an expression (required)
-
expression attribute values (required). Specifies a DynamoDB json structure of the attribute value. This is useful for comparing an attribute with a value in DynamoDB that you might not know until runtime. You can define an expression attribute value as a placeholder for an actual value.
-
expression attribute names (required). This helps avoid potential conflicts with any DynamoDB reserved words, attribute names containing special characters, and similar.
-
options for when to use the condition expression (optional). The default is apply-during-cdc = false and apply-during-full-load = true
The structure for the rule is as follows:
"target-table-name": "customer_t", "mapping-parameters": { "partition-key-name": "CustomerName", "condition-expression": { "expression":"<conditional expression>", "expression-attribute-values": [ { "name":"<attribute name>", "value":<attribute value> } ], "apply-during-cdc":<optional Boolean value>, "apply-during-full-load": <optional Boolean value> }
The following sample highlights the sections used for condition expression.

Using attribute mapping with object mapping
Attribute mapping lets you specify a template string using source column names to restructure data on the target. There is no formatting done other than what the user specifies in the template.
The following example shows the structure of the source database and the desired structure of the DynamoDB target. First is shown the structure of the source, in this case an Oracle database, and then the desired structure of the data in DynamoDB. The example concludes with the JSON used to create the desired target structure.
The structure of the Oracle data is as follows:
| FirstName | LastName | StoreId | HomeAddress | HomePhone | WorkAddress | WorkPhone | DateOfBirth |
|---|---|---|---|---|---|---|---|
| Primary Key | N/A | ||||||
| Randy | Marsh | 5 | 221B Baker Street | 1234567890 | 31 Spooner Street, Quahog | 9876543210 | 02/29/1988 |
The structure of the DynamoDB data is as follows:
| CustomerName | StoreId | ContactDetails | DateOfBirth |
|---|---|---|---|
| Partition Key | Sort Key | N/A | |
|
|
|
|
The following JSON shows the object mapping and column mapping used to achieve the DynamoDB structure:
{ "rules": [ { "rule-type": "selection", "rule-id": "1", "rule-name": "1", "object-locator": { "schema-name": "test", "table-name": "%" }, "rule-action": "include" }, { "rule-type": "object-mapping", "rule-id": "2", "rule-name": "TransformToDDB", "rule-action": "map-record-to-record", "object-locator": { "schema-name": "test", "table-name": "customer" }, "target-table-name": "customer_t", "mapping-parameters": { "partition-key-name": "CustomerName", "sort-key-name": "StoreId", "exclude-columns": [ "FirstName", "LastName", "HomeAddress", "HomePhone", "WorkAddress", "WorkPhone" ], "attribute-mappings": [ { "target-attribute-name": "CustomerName", "attribute-type": "scalar", "attribute-sub-type": "string", "value": "${FirstName},${LastName}" }, { "target-attribute-name": "StoreId", "attribute-type": "scalar", "attribute-sub-type": "string", "value": "${StoreId}" }, { "target-attribute-name": "ContactDetails", "attribute-type": "scalar", "attribute-sub-type": "string", "value": "{\"Name\":\"${FirstName}\",\"Home\":{\"Address\":\"${HomeAddress}\",\"Phone\":\"${HomePhone}\"}, \"Work\":{\"Address\":\"${WorkAddress}\",\"Phone\":\"${WorkPhone}\"}}" } ] } } ] }
Another way to use column mapping is to use DynamoDB format as your document
type. The following code example uses dynamodb-map as the
attribute-sub-type for attribute mapping.
{ "rules": [ { "rule-type": "selection", "rule-id": "1", "rule-name": "1", "object-locator": { "schema-name": "test", "table-name": "%" }, "rule-action": "include" }, { "rule-type": "object-mapping", "rule-id": "2", "rule-name": "TransformToDDB", "rule-action": "map-record-to-record", "object-locator": { "schema-name": "test", "table-name": "customer" }, "target-table-name": "customer_t", "mapping-parameters": { "partition-key-name": "CustomerName", "sort-key-name": "StoreId", "exclude-columns": [ "FirstName", "LastName", "HomeAddress", "HomePhone", "WorkAddress", "WorkPhone" ], "attribute-mappings": [ { "target-attribute-name": "CustomerName", "attribute-type": "scalar", "attribute-sub-type": "string", "value": "${FirstName},${LastName}" }, { "target-attribute-name": "StoreId", "attribute-type": "scalar", "attribute-sub-type": "string", "value": "${StoreId}" }, { "target-attribute-name": "ContactDetails", "attribute-type": "document", "attribute-sub-type": "dynamodb-map", "value": { "M": { "Name": { "S": "${FirstName}" }, "Home": { "M": { "Address": { "S": "${HomeAddress}" }, "Phone": { "S": "${HomePhone}" } } }, "Work": { "M": { "Address": { "S": "${WorkAddress}" }, "Phone": { "S": "${WorkPhone}" } } } } } } ] } } ] }
As an alternative to dynamodb-map, you can use dynamodb-list
as the attribute-sub-type for attribute mapping, as shown in the following example.
{ "target-attribute-name": "ContactDetailsList", "attribute-type": "document", "attribute-sub-type": "dynamodb-list", "value": { "L": [ { "N": "${FirstName}" }, { "N": "${HomeAddress}" }, { "N": "${HomePhone}" }, { "N": "${WorkAddress}" }, { "N": "${WorkPhone}" } ] } }
Example 1: Using attribute mapping with object mapping
The following example migrates data from two MySQL database tables, nfl_data and sport_team , to two DynamoDB table called NFLTeams and SportTeams. The structure of the tables and the JSON used to map the data from the MySQL database tables to the DynamoDB tables are shown following.
The structure of the MySQL database table nfl_data is shown below:
mysql> desc nfl_data; +---------------+-------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +---------------+-------------+------+-----+---------+-------+ | Position | varchar(5) | YES | | NULL | | | player_number | smallint(6) | YES | | NULL | | | Name | varchar(40) | YES | | NULL | | | status | varchar(10) | YES | | NULL | | | stat1 | varchar(10) | YES | | NULL | | | stat1_val | varchar(10) | YES | | NULL | | | stat2 | varchar(10) | YES | | NULL | | | stat2_val | varchar(10) | YES | | NULL | | | stat3 | varchar(10) | YES | | NULL | | | stat3_val | varchar(10) | YES | | NULL | | | stat4 | varchar(10) | YES | | NULL | | | stat4_val | varchar(10) | YES | | NULL | | | team | varchar(10) | YES | | NULL | | +---------------+-------------+------+-----+---------+-------+
The structure of the MySQL database table sport_team is shown below:
mysql> desc sport_team; +---------------------------+--------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +---------------------------+--------------+------+-----+---------+----------------+ | id | mediumint(9) | NO | PRI | NULL | auto_increment | | name | varchar(30) | NO | | NULL | | | abbreviated_name | varchar(10) | YES | | NULL | | | home_field_id | smallint(6) | YES | MUL | NULL | | | sport_type_name | varchar(15) | NO | MUL | NULL | | | sport_league_short_name | varchar(10) | NO | | NULL | | | sport_division_short_name | varchar(10) | YES | | NULL | |
The table-mapping rules used to map the two tables to the two DynamoDB tables is shown below:
{ "rules":[ { "rule-type": "selection", "rule-id": "1", "rule-name": "1", "object-locator": { "schema-name": "dms_sample", "table-name": "nfl_data" }, "rule-action": "include" }, { "rule-type": "selection", "rule-id": "2", "rule-name": "2", "object-locator": { "schema-name": "dms_sample", "table-name": "sport_team" }, "rule-action": "include" }, { "rule-type":"object-mapping", "rule-id":"3", "rule-name":"MapNFLData", "rule-action":"map-record-to-record", "object-locator":{ "schema-name":"dms_sample", "table-name":"nfl_data" }, "target-table-name":"NFLTeams", "mapping-parameters":{ "partition-key-name":"Team", "sort-key-name":"PlayerName", "exclude-columns": [ "player_number", "team", "name" ], "attribute-mappings":[ { "target-attribute-name":"Team", "attribute-type":"scalar", "attribute-sub-type":"string", "value":"${team}" }, { "target-attribute-name":"PlayerName", "attribute-type":"scalar", "attribute-sub-type":"string", "value":"${name}" }, { "target-attribute-name":"PlayerInfo", "attribute-type":"scalar", "attribute-sub-type":"string", "value":"{\"Number\": \"${player_number}\",\"Position\": \"${Position}\",\"Status\": \"${status}\",\"Stats\": {\"Stat1\": \"${stat1}:${stat1_val}\",\"Stat2\": \"${stat2}:${stat2_val}\",\"Stat3\": \"${stat3}:${ stat3_val}\",\"Stat4\": \"${stat4}:${stat4_val}\"}" } ] } }, { "rule-type":"object-mapping", "rule-id":"4", "rule-name":"MapSportTeam", "rule-action":"map-record-to-record", "object-locator":{ "schema-name":"dms_sample", "table-name":"sport_team" }, "target-table-name":"SportTeams", "mapping-parameters":{ "partition-key-name":"TeamName", "exclude-columns": [ "name", "id" ], "attribute-mappings":[ { "target-attribute-name":"TeamName", "attribute-type":"scalar", "attribute-sub-type":"string", "value":"${name}" }, { "target-attribute-name":"TeamInfo", "attribute-type":"scalar", "attribute-sub-type":"string", "value":"{\"League\": \"${sport_league_short_name}\",\"Division\": \"${sport_division_short_name}\"}" } ] } } ] }
The sample output for the NFLTeams DynamoDB table is shown below:
"PlayerInfo": "{\"Number\": \"6\",\"Position\": \"P\",\"Status\": \"ACT\",\"Stats\": {\"Stat1\": \"PUNTS:73\",\"Stat2\": \"AVG:46\",\"Stat3\": \"LNG:67\",\"Stat4\": \"IN 20:31\"}", "PlayerName": "Allen, Ryan", "Position": "P", "stat1": "PUNTS", "stat1_val": "73", "stat2": "AVG", "stat2_val": "46", "stat3": "LNG", "stat3_val": "67", "stat4": "IN 20", "stat4_val": "31", "status": "ACT", "Team": "NE" }
The sample output for the SportsTeams DynamoDB table is shown below:
{ "abbreviated_name": "IND", "home_field_id": 53, "sport_division_short_name": "AFC South", "sport_league_short_name": "NFL", "sport_type_name": "football", "TeamInfo": "{\"League\": \"NFL\",\"Division\": \"AFC South\"}", "TeamName": "Indianapolis Colts" }
Target data types for DynamoDB
The DynamoDB endpoint for Amazon DMS supports most DynamoDB data types. The following table shows the Amazon Amazon DMS target data types that are supported when using Amazon DMS and the default mapping from Amazon DMS data types.
For additional information about Amazon DMS data types, see Data types for Amazon Database Migration Service.
When Amazon DMS migrates data from heterogeneous databases, we map data types from the source database to intermediate data types called Amazon DMS data types. We then map the intermediate data types to the target data types. The following table shows each Amazon DMS data type and the data type it maps to in DynamoDB:
| Amazon DMS data type | DynamoDB data type |
|---|---|
|
String |
String |
|
WString |
String |
|
Boolean |
Boolean |
|
Date |
String |
|
DateTime |
String |
|
INT1 |
Number |
|
INT2 |
Number |
|
INT4 |
Number |
|
INT8 |
Number |
|
Numeric |
Number |
|
Real4 |
Number |
|
Real8 |
Number |
|
UINT1 |
Number |
|
UINT2 |
Number |
|
UINT4 |
Number |
| UINT8 | Number |
| CLOB | String |