How Amazon S3 File Gateway works
To use an S3 File Gateway, you start by downloading a VM image for the gateway. You then activate the gateway from the Amazon Web Services Management Console or through the Storage Gateway API. You can also create an S3 File Gateway using an Amazon EC2 image.
After the S3 File Gateway is activated, you create and configure your file share and associate that share with your Amazon Simple Storage Service (Amazon S3) bucket. Doing this makes the share accessible by clients using either the Network File System (NFS) or Server Message Block (SMB) protocol. Files written to a file share become objects in Amazon S3, with the path as the key. There is a one-to-one mapping between files and objects, and the gateway asynchronously updates the objects in Amazon S3 as you change the files. Existing objects in the Amazon S3 bucket appear as files in the file system, and the key becomes the path. Objects are encrypted with Amazon S3–server-side encryption keys (SSE-S3). All data transfer is done through HTTPS.
When sending HTTPS data upload requests to the Amazon S3, File Gateway populates the Content-MD5 header with the MD5 checksum of the data being uploaded. The use of this header causes Amazon S3 to return a failure in case of mismatch between the MD5 checksum computed by Amazon S3 and the value received from the File Gateway. If such a failure is returned, the File Gateway resends the request.
The service optimizes data transfer between the gateway and Amazon using multipart parallel uploads or byte-range downloads, to better use the available bandwidth. Local cache is maintained to provide low latency access to the recently accessed data and reduce data egress charges. CloudWatch metrics provide insight into resource use on the VM and data transfer to and from Amazon. CloudTrail tracks all API calls.
With S3 File Gateway storage, you can do such tasks as ingesting cloud workloads to Amazon S3, performing backups and archiving, tiering, and migrating storage data to the Amazon Cloud. The following diagram provides an overview of file storage deployment for Storage Gateway.
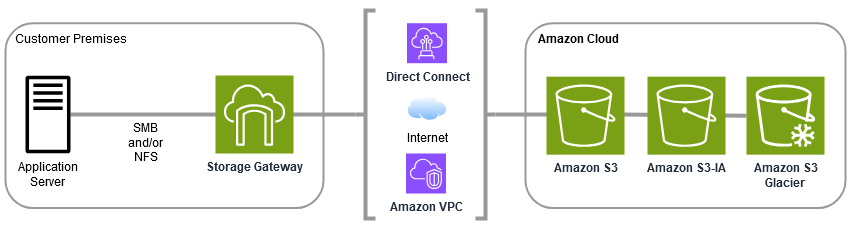
S3 File Gateway converts files to S3 objects when uploading files to Amazon S3. The interaction between file operations performed against files shares on S3 File Gateway and S3 objects requires certain operations to be carefully considered when converting between files and objects.
Common file operations change file metadata, which results in the deletion of the current S3 object and the creation of a new S3 object. The following table shows example file operations and the impact on S3 objects.
| File operation | S3 object impact | Storage class implication |
|---|---|---|
|
Rename file |
Replaces existing S3 object and creates a new S3 object for each file |
Early deletion fees and retrieval fees may apply |
|
Rename folder |
Replaces all existing S3 objects and creates new S3 objects for each folder and files in the folder structure |
Early deletion fees and retrieval fees may apply |
|
Change file/folder permissions |
Replaces existing S3 object and creates a new S3 object for each file or folder |
Early deletion fees and retrieval fees may apply |
|
Change file/folder ownership |
Replaces existing S3 object and creates a new S3 object for each file or folder |
Early deletion fees and retrieval fees may apply |
|
Append to a file |
Replaces existing S3 object and creates a new S3 object for each file |
Early deletion fees and retrieval fees may apply |
When a file is written to the S3 File Gateway by an NFS or SMB client, the File Gateway uploads the file's data to Amazon S3 followed by its metadata, (ownerships, timestamps, etc.). Uploading the file data creates an S3 object, and uploading the metadata for the file updates the metadata for the S3 object. This process creates another version of the object, resulting in two versions of an object. If S3 Versioning is turned on, both versions will be stored.
When a file is modified in the S3 File Gateway by an NFS or SMB client after it has been uploaded to Amazon S3, the S3 File Gateway uploads the new or modified data instead of uploading the whole file. The file modification results in a new version of the S3 object being created.
When the S3 File Gateway uploads larger files, it might need to upload smaller chunks of the file before the client is done writing to the S3 File Gateway. Some reasons for this include freeing up cache space or a high rate of writes to a file share. This can result in multiple versions of an object in the S3 bucket.
You should monitor your S3 bucket to determine how many versions of an object exist before setting up lifecycle policies to move objects to different storage classes. You should configure lifecycle expiration for previous versions to minimize the number of versions you have for an object in your S3 bucket. The use of Same-Region replication (SRR) or Cross-Region replication (CRR) between S3 buckets will increase the storage used.